简介:
激活函数是人工神经网络的一个极其重要的特征。它决定一个神经元是否应该被激活,激活代表神经元接收的信息与给定的信息有关。
激活函数实际上是将输入信息做了非线性变换传给下一层神经元,在神经网络中,激活函数基本是必不可少的一部分,因为他增加了我们的模型的复杂性,每层神经元都有一个权重向量weight和偏置向量bias,如果没有了激活函数,神经网络实质上就成了一个线性回归网络,每一次都只是在上一层的基础上做了线性变换。那它就不能完成比较复杂的学习任务,如语言翻译,图片分类等等。
常用的激活函数及使用方法:
1.softmax函数
在多分类中常用的激活函数,是基于逻辑回归的,常用在输出一层,将输出压缩在0~1之间,且保证所有元素和为1,表示输入值属于每个输出值的概率大小。
2.sigmoid函数
公式:
sigmoid(x)=1/(1+exp(-x))
函数及其导数曲线: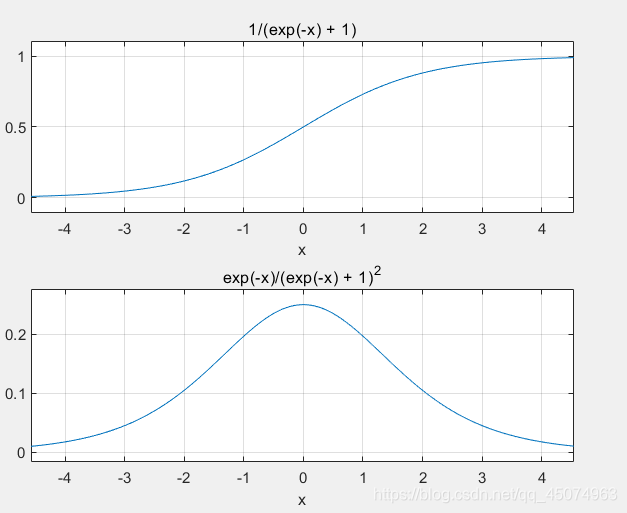
sigmoid函数也是用于将实数映射在0~1范围内的,可以用它来做二分类问题,上述的softmax是处理多分类问题,从图像中可以看出sigmoid函数的梯度主要集中在[-3,3]区域,所以用于特征相差不是特别大的时候比较好。从其导数图像可以看出导数从x=0出又很快衰减至趋于0,所以在深层次网络中的反向传播过程表现不是很好,容易出现“梯度消失”现象。
3.tanh函数:
公式:
tanh(x)=2sigmoid(2x)-1=2/(1+exp(-2x))-1
函数及其导数曲线:
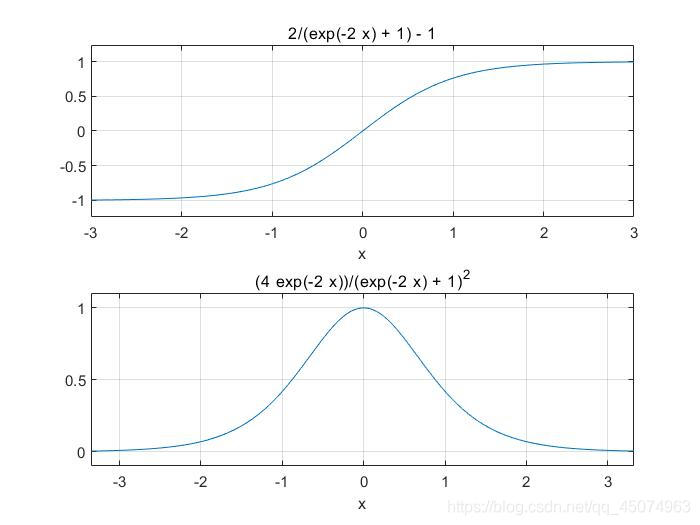
tanh函数(又称双正切函数)实际上时sigmoid函数的一个放大版本,图像也十分相似,不过tanh函数图像关于原点对称,范围为[-1,1],tanh函数在特征相差明显时效果比较好,会不断扩大特征效果。他的梯度函数比sigmoid的更陡峭,所以可以根据梯度要求选取二者的使用,但也容易出现‘梯度消失’现象。
4.relu函数
公式:
f(x)=max(0,x)
函数及其导数曲线:
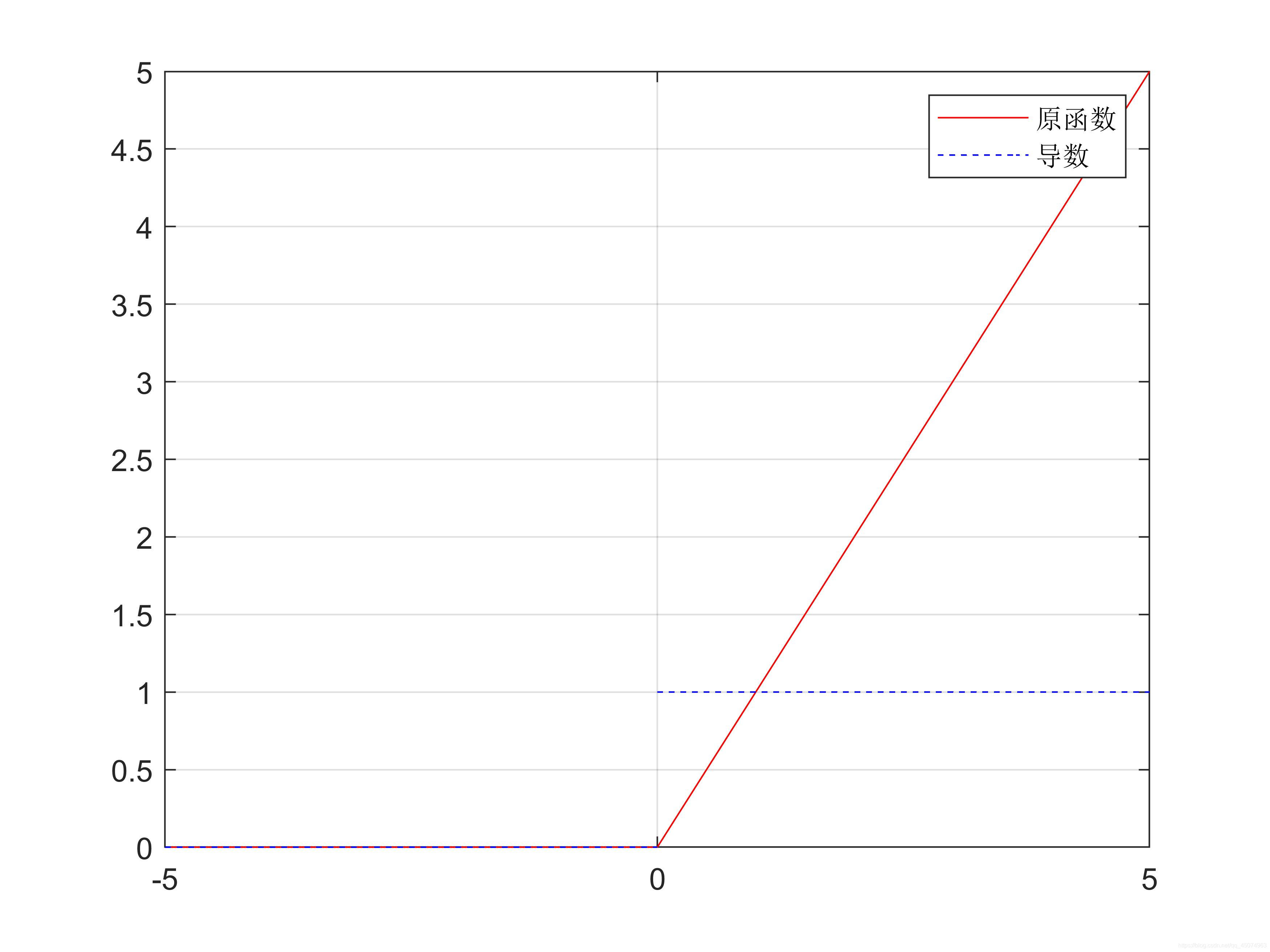 relu函数可以说是如今使用最广泛的激活函数了。从图像可以看出,当输入<0时,输出和导数(梯度)都为0,当输入>0时,输出等于输入,导数(梯度)等于1。
relu函数可以说是如今使用最广泛的激活函数了。从图像可以看出,当输入<0时,输出和导数(梯度)都为0,当输入>0时,输出等于输入,导数(梯度)等于1。
Relu一大优点是他不会同时激活所有神经元,即输入值为负时输出为0,而神经元也不会被激活,也就是说在一段时间内,只有部分神经元被激活,使神经网络变得高效易于计算。
但Relu函数也存在梯度为0的时候(x<0时),那就是说反向传播过程中,权重没有得到更新,那这个神经元永远都不会被激活,如果learing rate还比较大,那很多神经元都会’Dead’掉。
5.Leaky Relu函数
公式:
f(x)=ax,x<0(a值很小,这里取0.01)
f(x)= x ,x>0
函数及其导数曲线:
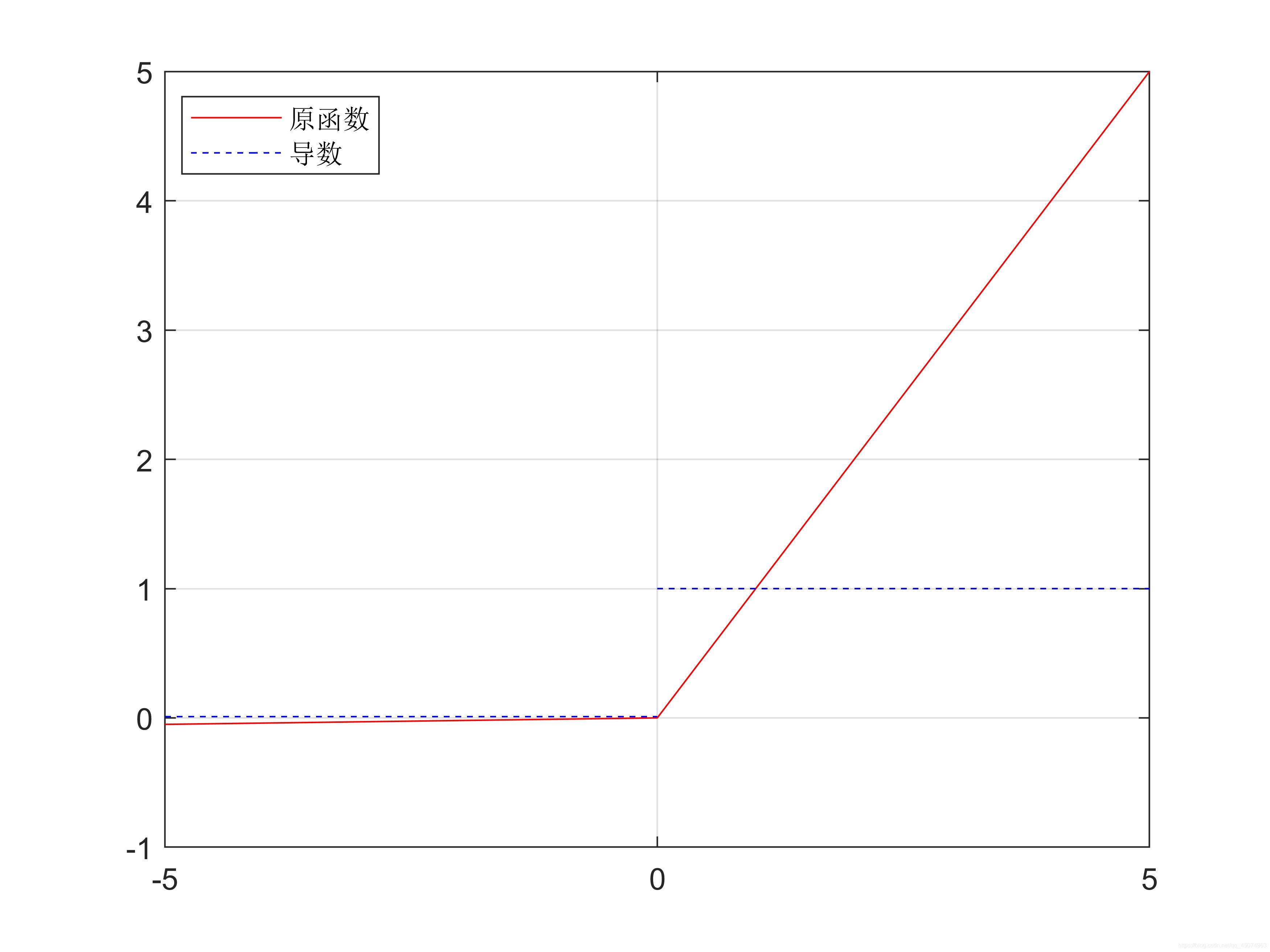
由于Relu函数存在梯度为0的情况,Leaky Relu函数作为Relu函数的改良版,去掉了梯度为0的部分,这样就不会出现死神经元。
另外与Leaky Relu函数相似的还有PRelu函数(公式相同),PRelu函数中的a值可以训练,当Leaky Relu函数无法解决问题时可以考虑使用PRelu函数。
6.Elu函数
公式:
elu(x)=x,x>0;
elu(x)=a(exp(x)-1),x<0;
(a这里取0.2)
函数及其导数曲线:
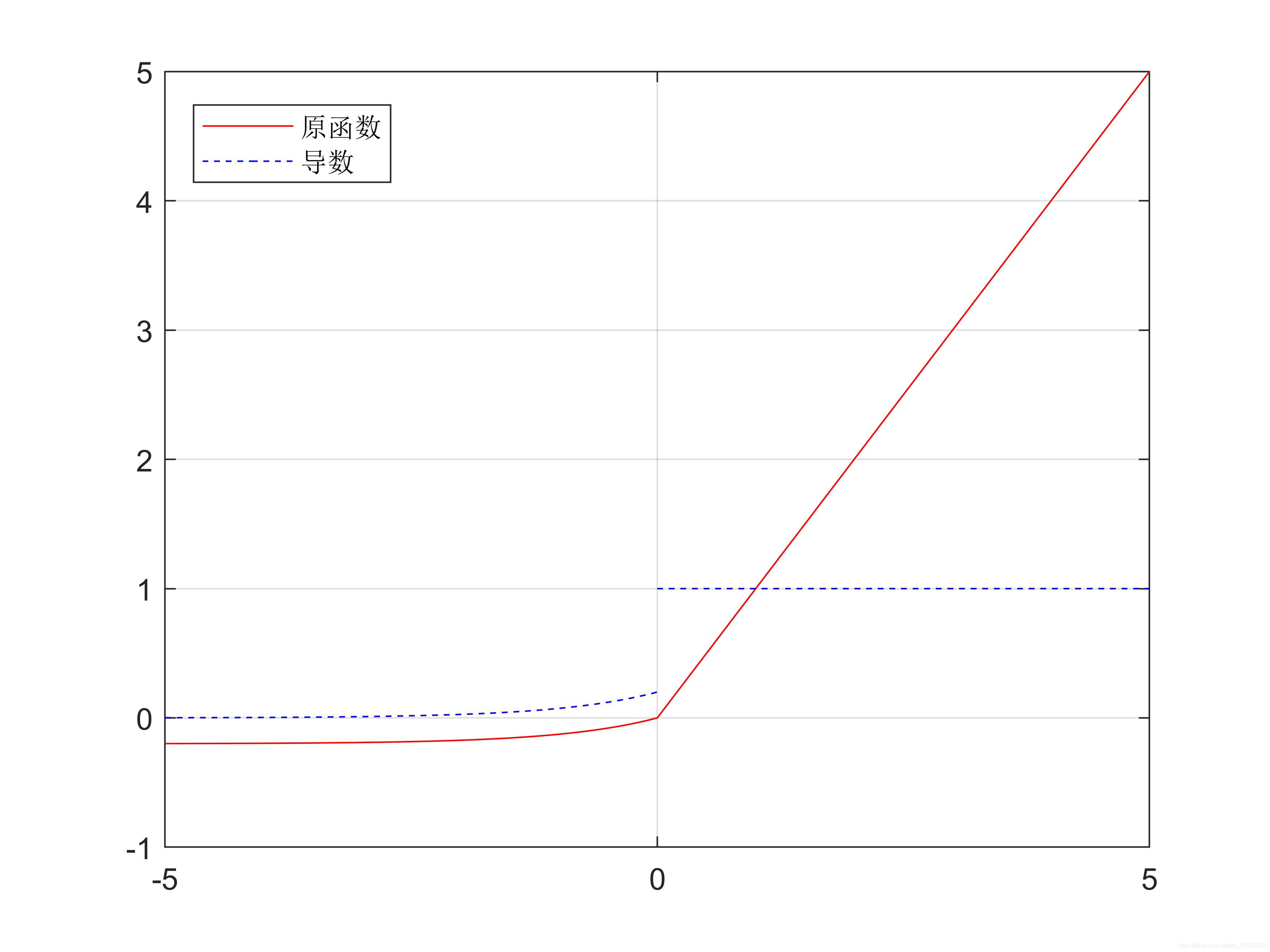
可以看出elu函数也是relu函数的一个改良版,解决掉了死亡神经元问题,能够得到负值输出,不过由于引入了指数运算,学习时间会更长,甚至可能产生梯度爆炸问题,神经网络也不能自己学习a值。
另外相似的函数还有SELU,GELU等
7.激活函数还有很多,不一一列举了
比如:
hard_sigmoid函数
计算速度比 sigmoid 激活函数更快。如果 x < -2.5,返回 0。如果 x > 2.5,返回 1。如果 -2.5 <= x <= 2.5,返回 0.2 * x + 0.5
linear (线性激活函数)
