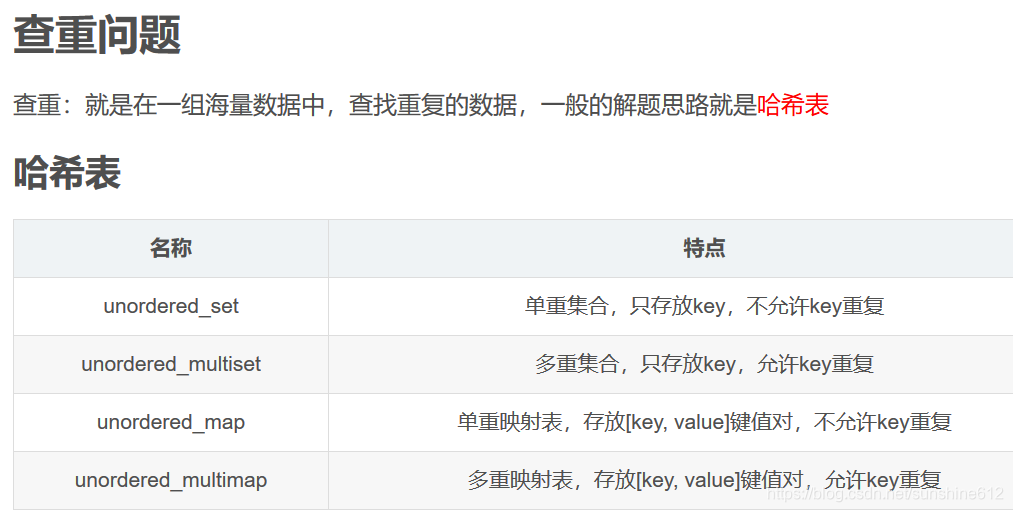
求解海量数据
统计英文单词出现的次数,并按照出现的顺序打印单词和它的次数
int main()
{
string strArr[] =
{"hello", "sfdf", "rtyui", "vbn", "hello", "sfdf"};
// 统计上面的英文单词出现的次数,并按照出现的顺序打印单词和它的次数
vector<string> vec;
unordered_map<string, int> map;
for (string &str : strArr)
{
map[str]++;//用map记单词以及单次次数,紧接着传入vector 输出vector中的单词
vec.push_back(str);
}
for (string &str : vec)
{
auto it = map.find(str);
if (it != map.end())
{
cout << str << " " << map[str] << endl;
map.erase(str);//如果不查出来删掉会出现打两遍的结果 hello....hello..
}
}
return 0;
}
通过快排的分割,来求解海量数据top k的问题
如何通过快排的分割,来求解海量数据top k的问题
10000 值最大的前10个 / 值最大的第10个
/*
*/
template<typename T>
int partation(vector<T> &arr, int i, int j)
{
int val = arr[i];
while (i < j)
{
while (i < j && arr[j] > val)
{
j--;
}
if (i < j)
{
arr[i++] = arr[j];
}
while (i < j && arr[i] < val)
{
i++;
}
if (i < j)
{
arr[j--] = arr[i];
}
}
arr[i] = val;
return i;
}
// 2,3,6,5,8,0,3,1,9,10
template<typename T>
int selectValue01(vector<T> &vec, int i, int j, int k)
{
int pos = partation(vec, i, j);
if (pos == k - 1)
{
return pos;
}
else if (pos < k - 1)
{//如果找到的位置是小于k的 说明得从右边再找 所以变动i下标
return selectValue01(vec, pos + 1, j, k);
}
else
{
return selectValue01(vec, i, pos - 1, k);
}
}
int main()
{
vector<int> vec;
for (int i = 0; i < 20; ++i)
{
vec.push_back(rand() % 100);
}
// 求vec容器中,值第5小和值第8大的元素,打印出来
for (int data : vec)
{
cout << data << " ";
}
cout << endl;
// 找vec第5小的数字 1 5 2 7 8 4 8 9 0
int val1 = selectValue01(vec, 0, vec.size() - 1, vec.size() - 6 + 1);
for (int i = val1; i < vec.size(); ++i)
{
cout << vec[i] << " ";
}
/*for (int i = 0; i <= val1; ++i)
{
cout << vec[i] << " ";
}*/
cout << endl;
//cout << "第5小的数字是:" << val1 << endl;
sort(vec.begin(), vec.end());
for (int data : vec)
{
cout << data << " ";
}
cout << endl;
return 0;
}
海量数据的前n大/前n小/Top k问题
海量数据求top k的问题要用到容器和堆
大根堆/小根堆
大根堆(求最小的前n个数)
小根堆(求最大的前n个数)
堆的实质其实就是一颗完全二叉树
最大堆特点:父节点值均大于子节点;(堆顶元素最大)
最小堆特点:父节点值均小于子节点;(堆顶元素最小)
总结:找top最大的用小根堆;找top最小的用大根堆
最大堆找top k小代码的基本思路
1.求前n个最小的数 先建立最大堆 把海量数据向最大堆添加n个数,然后堆的内部会自动排序
2.不用管它的内部是怎么操作的 接下来我们往最大堆进行插入操作 因为最大堆的特点就是堆顶元素最大 若插入元素大于堆顶元素 则它大于堆中任何一个元素 所以摒弃该元素 遍历下一个元素
3.若插入元素小于堆顶元素则进行插入 插入后堆内自动排序 堆顶元素又成为该堆的最大元素 原堆顶元素出堆 持续遍历完 得到的就是所有元素中最小的前n个数
最小堆找top k大代码的基本思路
1.求前n个最大的数 先建立最小堆 把海量数据向最小堆添加n个数,堆的内部会自动排序
2.然后我们往最小堆进行插入操作 因为最小堆的特点就是堆顶元素最小 若插入元素小于堆顶元素 则它小于堆中任何一个元素 所以摒弃该元素 遍历下一个元素
3.若插入元素大于堆顶元素则进行插入 插入后堆内自动排序 堆顶元素又成为该堆的最小元素 原堆顶元素出堆 持续遍历完 得到的就是所有元素中最大的前n个数
时间复杂度O(n)
源代码
扫描二维码关注公众号,回复:
10938404 查看本文章

int main()
{
//在最短时间内找到所有整数中最大/最小的n个数并且打印;
//找top最大的用小根堆;找top最小的用大根堆
//时间复杂度 O(n)*log2 n
//===================最大堆找最小值======================
vector<unsigned int>vec;
for (unsigned int i = 0; i < 20000; ++i)
{
vec.push_back(rand() + i); //随机产生两万个数据放在vector容器中
}
priority_queue<int> maxHeap; //声明最大堆
int k = 10;//求20000个数据中前10小个数
for (int i = 0; i < k; i++)
{
maxHeap.push(vec[i]);//先往最大堆中放10个数
}
for (int i = k; i < 20000; ++i)
{
//遍历判断容器中剩余的每个数与堆顶元素的大小
//若小于堆顶元素 则把堆顶元素出堆 把该元素入堆
if (vec[i] < maxHeap.top())
{
maxHeap.pop();
maxHeap.push(vec[i]);
}
}
while (!maxHeap.empty())
//打印最大堆里边的十个最小的数
{
cout << maxHeap.top() << " ";
maxHeap.pop();
}
cout << endl;
//==========================================================
//==========================最小堆找最大值===================
for (unsigned int i = 0; i < 20000; ++i)
{
vec.push_back(rand() + i);
}
priority_queue<int, vector<int>, greater<int>> minHeap; //建立最小堆
//注意:最小堆要加上greater<int>
int j = 10;
for (int i = 0; i < j; i++)
{
minHeap.push(vec[i]);
}
for (int i = j; i < 20000; ++i)
{
//遍历判断容器中剩余的每个数与堆顶元素的大小
//若大于堆顶元素 则把堆顶元素出堆 把该元素入堆
if (vec[i] > minHeap.top())
{
minHeap.pop();
minHeap.push(vec[i]);
}
}
while (!minHeap.empty())
{
//打印最大堆里边的十个最小的数
cout << minHeap.top() << " ";
minHeap.pop();
}
cout << endl;
return 0;
}
用小根堆求出前五最大数据并输出
(使用优先级队列构建 以及lambda表达式)
#include "pch.h"
#include<unordered_map>
#include <iostream>
#include<vector>
#include<algorithm>
#include<functional>
#include<string>
#include<queue>
using namespace std;
int main()
{
vector<int> vec;
for (int i = 0; i < 20; ++i)
{
vec.push_back(rand() % 100);
}
unordered_map<int, int> hashmap;
for (int val : vec)
{
hashmap[val]++;//统计值和出现的次数 哈希表的[]返回哈希表对应的key ++即对值对应的次数++
}
//求top 5 最大次数 因为要输出次数和值 所以给优先级队列多传一个值 所以传pair对象键值对 传引用进去?
using MinHeap= priority_queue<pair<int, int>, vector<pair<int, int>>,
function<bool(const pair<int,int>&, const pair<int, int>&)>>;//传两个是因为要进行比较 所以传两个pair对象
MinHeap heap([](const pair<int, int>&p1, const pair<int, int>&p2)->bool {return p1.second > p2.second; });
//用前五个元素构建小根堆
for (auto &pair : hashmap)
{
if (heap.size() < 5)
{
heap.push(pair);
}
else
{
if (pair.second > heap.top().second)
{
heap.pop();
heap.push(pair);
}
}
}
while (!heap.empty())
{
cout << heap.top().first << " "<<heap.top().second<<" ";
heap.pop();
}
}
找第一个重复的数字
int main()
{
vector<int> vec;//将要查找的数据放在vec中
for (int i = 0; i < 200000; ++i)
{
vec.push_back(rand());
}
// 用哈希表解决查重,因为只查重,所以用无序集合解决该问题
unordered_set<int> hashSet;
for (int val : vec)
{
// 在哈希表中查找val
auto it = hashSet.find(val);
if (it != hashSet.end())//找到了
{
cout << *it << "是第一个重复的数据" << endl;
return;
}
else
{
// 没找到
hashSet.insert(val);
}
}
return 0;
}
统计数字及其出现的次数可以使用无序映射表
#include <iostream>
#include <unordered_map>
using namespace std;
int main()
{
vector<int> vec;
for (int i = 0; i < 200000; ++i)
{
vec.push_back(rand());
}
// 用无序映射表统计数字和数字出现的次数
unordered_map<int, int> hashMap;
for (int val : vec)
{
hashMap[val]++; // 可以直接记录数据并且更新数据出现的次数
}
// 打印统计出来的重复的数据
for (pair<int, int> value : hashMap)
{
if (value.second > 1)
{
cout << "key:" << value.first << " 重复次数:" << value.second << endl;
}
}
cout << endl;
return 0;
}
对内存有限制的大数据处理
1.首先将所要计算的数据存进一个大文件中
2.由于内存限制,文件中的内容无法一次性加载进内存,需要将文件进行分割
3.将该大文件分割成每一个文件足够装载进内存的多个小文件
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_map>
using namespace std;
// 大文件划分小文件(哈希映射)+ 哈希统计 + 小根堆(快排也可以达到同样的时间复杂度)
int main()
{
// 打开存储数据的原始文件
FILE *pf = fopen("data.dat", "rb");
if (pf == nullptr)
return 0;
// 这里由于原始数据量缩小,所以这里文件划分的个数也变小了,11个小文件
const int FILE_NO = 11;
FILE *pfile[FILE_NO] = { nullptr };
for (int i = 0; i < FILE_NO; ++i)
{
char filename[20];
sprintf(filename, "data%d.dat", i+1);
pfile[i] = fopen(filename, "wb+");
}
// 哈希映射,把大文件中的数据,映射到各个小文件当中
int data;
while (fread(&data, 4, 1, pf) > 0)
{
int findex = data % FILE_NO;//相同元素必然会在同一个文件中
fwrite(&data, 4, 1, pfile[findex]);
}
// 因为结果要记录数字和重复的次数,所以需要打包一个类类型
struct Node
{
Node(int v, int c) :val(v), count(c) {}
// 为什么要实现operator>,因为小根堆里面要比较Node对象的大小
bool operator>(const Node &src)const
{
return count > src.count;
}
int val; // 表示数字的值
int count; // 表示数字重复的次数
};
// 定义一个链式哈希表
unordered_map<int, int> numMap;
// 先定义一个小根堆
priority_queue<Node, vector<Node>, greater<Node>> minheap;
// 分段求解小文件的top 10大的数字,并求出最终结果
for (int i = 0; i < FILE_NO; ++i)
{
// 恢复小文件的文件指针到起始位置
fseek(pfile[i], 0, SEEK_SET);
while (fread(&data, 4, 1, pfile[i]) > 0)
{
numMap[data]++;
}
int k = 0;
auto it = numMap.begin();
// 如果堆是空的,先往堆放10个数据
if (minheap.empty())//其实就是当读第一个文件时才会进入该循环
{
// 先从map表中读10个数据到小根堆中,建立具有10个元素的小根堆,最小的元素在堆顶
for (; it != numMap.end() && k < 10; ++it, ++k)
{
minheap.push(Node(it->first, it->second));
}
}
// 把K+1到末尾的元素进行遍历,和堆顶元素比较
for (; it != numMap.end(); ++it)
{
// 如果map表中当前元素重复次数大于,堆顶元素的重复次数,则替换
if (it->second > minheap.top().count)
{
minheap.pop();
minheap.push(Node(it->first, it->second));
}
}
// 清空哈希表,进行下一个小文件的数据统计
numMap.clear();
}
// 堆中剩下的就是重复次数最大的前k个
while (!minheap.empty())
{
Node node = minheap.top();
cout << node.val << " : " << node.count << endl;
minheap.pop();
}
return 0;
}
