1:直接读取文件:
scala> val userDF=spark.read.format("csv").option("header","true").option("delimiter",",").load("file:///home/data/users.csv")
userDF: org.apache.spark.sql.DataFrame = [user_id: string, locale: string ... 5 more fields]
scala> userDF.printSchema
root
|-- user_id: string (nullable = true)
|-- locale: string (nullable = true)
|-- birthyear: string (nullable = true)
|-- gender: string (nullable = true)
|-- joinedAt: string (nullable = true)
|-- location: string (nullable = true)
|-- timezone: string (nullable = true)
2根据已有的DF选择部分字段生成新的DF:
|-- user_id: string (nullable = true)
|-- locale: string (nullable = true)
|-- birthyear: string (nullable = true)
|-- gender: string (nullable = true)
scala> val userDF2=userDF.select("user_id","locale","birthyear","gender")
userDF2: org.apache.spark.sql.DataFrame = [user_id: string, locale: string ... 2 more fields]
scala> userDF2.printSchema
root
|-- user_id: string (nullable = true)
|-- locale: string (nullable = true)
|-- birthyear: string (nullable = true)
|-- gender: string (nullable = true)
3:显示 数据(默认显示 20条):
scala> userDF2.show

4:读取没有表头的文件作处理:
scala> import org.apache.spark.sql.functions.col
import org.apache.spark.sql.functions.col
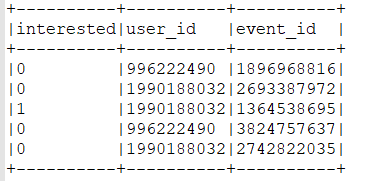
scala> val data2=data1.select(col("_c0").as("interested"),col("_c1").as("user_id"),col("_c2").as("event_id"))
data2: org.apache.spark.sql.DataFrame = [interested: string, user_id: string ... 1 more field]
scala> data2.printSchema
root
|-- interested: string (nullable = true)
|-- user_id: string (nullable = true)
|-- event_id: string (nullable = true)
scala> data2.show(5,false)
5.间接读取其他RDD,生成新的DF:
scala> val wf=sc.textFile("file:///home/data/test.txt").flatMap(line =>line.split(" ").map(x =>(x,1))).reduceByKey(_+_)
wf: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[35] at reduceByKey at <console>:28
scala> wf.foreach(println)
(d,2)
(up,1)
(a,4)
(b,1)
(day,2)
(hello,8)
(good,2)
(study,1)
(c,1)
1:由RDD-》DF:
scala> val wcDF=wf.toDF
wcDF: org.apache.spark.sql.DataFrame = [_1: string, _2: int]
scala> wcDF.printSchema
root
|-- _1: string (nullable = true)
|-- _2: integer (nullable = false)
2.DF -->表格化数据处理:
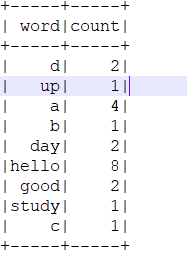
scala> val wc=wcDF.withColumnRenamed("_1","word").withColumnRenamed("_2","count")
wc: org.apache.spark.sql.DataFrame = [word: string, count: int]
scala> wc.printSchema
root
|-- word: string (nullable = true)
|-- count: integer (nullable = false)
scala> wc.show