之所以需要单独提及sync.Pool是因为 1. 它对于性能优化非常重要,gin利用sync.Pool来重新利用context, fasthttp更是专门提及"sync.Pool is your best friend."。2. 由于其引入就是为了优化性能,因此我们可以从源码中了解到很多优化的技巧。
Sync.Pool的使用
sync.Pool用于并发安全的获取和存储一组对象,这个结构体只有两个方法Get和Put。
注意的是,Get只能保证从Pool中获取一个对象,但是无法保证任何顺序。
我们也可以提供New函数,在Get被调用的时候如果临时对象池中没有对象那么会调用该函数返回一个object
pool := &sync.Pool{
New: func() interface{} {
return NewConnection()
},
}
connection := pool.Get().(*Connection)
使用场景
-
我们需要使用到很多临时的对象而希望避免频繁分配(从而带来的时延)
-
优化内存分配
比方说在某个情景下,我们需要写入一个buffer然后将buffer内容持久化到文件中。我们可以利用
sync.Pool来重用这个buffer。但是获取的内容是有状态的,可能需要清除。// Gets a buffer object buf := pool.Get().(*bytes.Buffer) // Returns the buffer into the pool defer pool.Put(buf) // Reset buffer otherwise it will contain "foo" during the first call// Then "foofoo" etc. buf.Reset() buf.WriteString("foo") return ioutil.WriteFile(filename, buf.Bytes(), 0644)
存储对象还是指针?
一般来说我们的目的是重用,因此最好使用指针。
有什么注意事项?
Pool可以未经提醒而删除引用(只是解除Pool对其的引用),如果sync.Pool是唯一一个持有池中对象引用的对象,那么池中对象随时可以被回收内存。
Get可以选择忽略池中对象(视其为空),我们不应该认为“用Put传入的数值可以用Get获取”
历代版本变更与实现分析
1.3版本下的sync.Pool
其实缓存池作为一个普遍的需求一直被尝试加入标准库中,但是之前的若干次提案(proposal)都卡壳在一个问题上-怎么设置缓存池清空的频率,或者等价问题,怎么设置缓存池的大小。
这个问题之所以重要,是因为缓存池是与GC的目标不一致的:缓存池希望留下内存以争取重用,而GC则希望能尽可能回收内存使其对用户可或者返回给操作系统。因此缓存池的清理频率会影响GC的效率。
如果缓存池的清理触发在GC之前,那么由于“清理缓存池-GC触发”这个时间段没有回收内存,因此这部分内存没有重用。而如果触发在GC之后,那么可能本来有一些内存可以在GC时候释放以提供给其他类型使用或者返回给操作系统。
因此,sync.Pool的清理是发生在GC之中:每次触发GC的时候,缓存池都会清空自己的缓存。
1.9版本下的sync.Pool
1.3-1.8的版本对sync.Pool的修改比较少,包括修改一些引进的bug,去掉不必要的类型转换,以及增加对race的支持等。
1.9版本则略微改善了sync.Pool的性能,做法包括
-
将
indexLocal方法中的return &(*[1000000]poolLocal)(l)[i]修改为
lp := unsafe.Pointer(uintptr(l) + uintptr(i)*unsafe.Sizeof(poolLocal{})) return (*poolLocal)(lp)这个方法之所以更快,是因为第一种方法中由于使用到了数组,所以会有边界检查(bound check)以及非空检查(nil check)。而修改后无需检查所以更快
-
修改poolLocal实现
原先
type poolLocal struct { private interface{} // Can be used only by the respective P. shared []interface{} // Can be used by any P. Mutex // Protects shared. pad [128]byte // Prevents false sharing. }修改后
type poolLocalInternal struct { private interface{} // Can be used only by the respective P. shared []interface{} // Can be used by any P. Mutex // Protects shared. } type poolLocal struct { poolLocalInternal // Prevents false sharing on widespread platforms with // 128 mod (cache line size) = 0 . pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte }原先的实现为了避免false sharing,选择用一个128字节的
pad字段来填充,而修改后的办法则强制保证poolLocal体积刚好是128字节。这样做的优点有三个:1. 显然减小了体积 2. 由于128字节最多只用两个缓存行(cache line),比起之前的176字节可以减少对缓存行的影响 3. 从编译器层面,使用下面的办法减少了一次Multiplication操作(在部分架构下比较昂贵)
总的来说,1.9的改动是非常轻微的,以至于没有在release log上有记录
1.12及其之前版本sync.Pool实现具体分析
考虑到自sync.Pool在1.3提出到1.12期间,仅仅在1.9做了简单的修改。因此我们不妨就以1.12版本为例说明其实现方式
内部组件
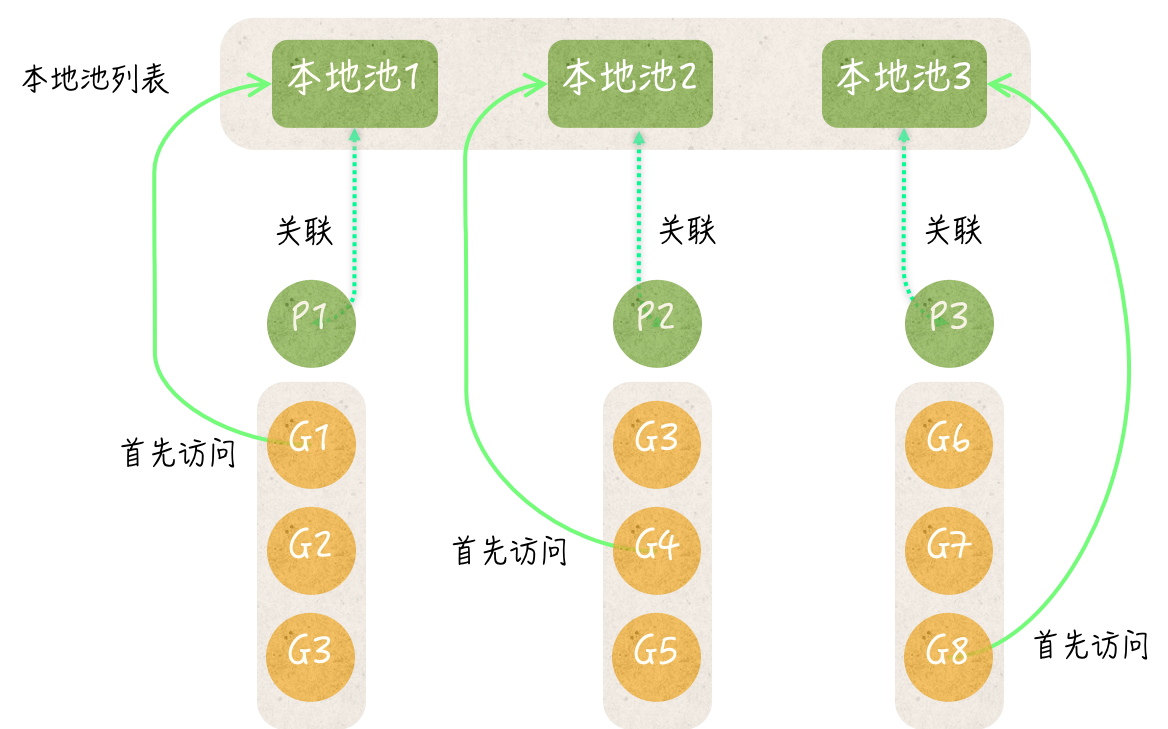
每一个池都会包含一个本地池列表,该列表长度与P(processor)相同。每一个本地池都包含存储私有临时对象字段的private,共享临时对象列表字段shared和sync.Mutex类型的嵌入字段
当程序调用Put或者Get的时候,总是先根据goroutine关联的P的ID找到对应本地池。
-
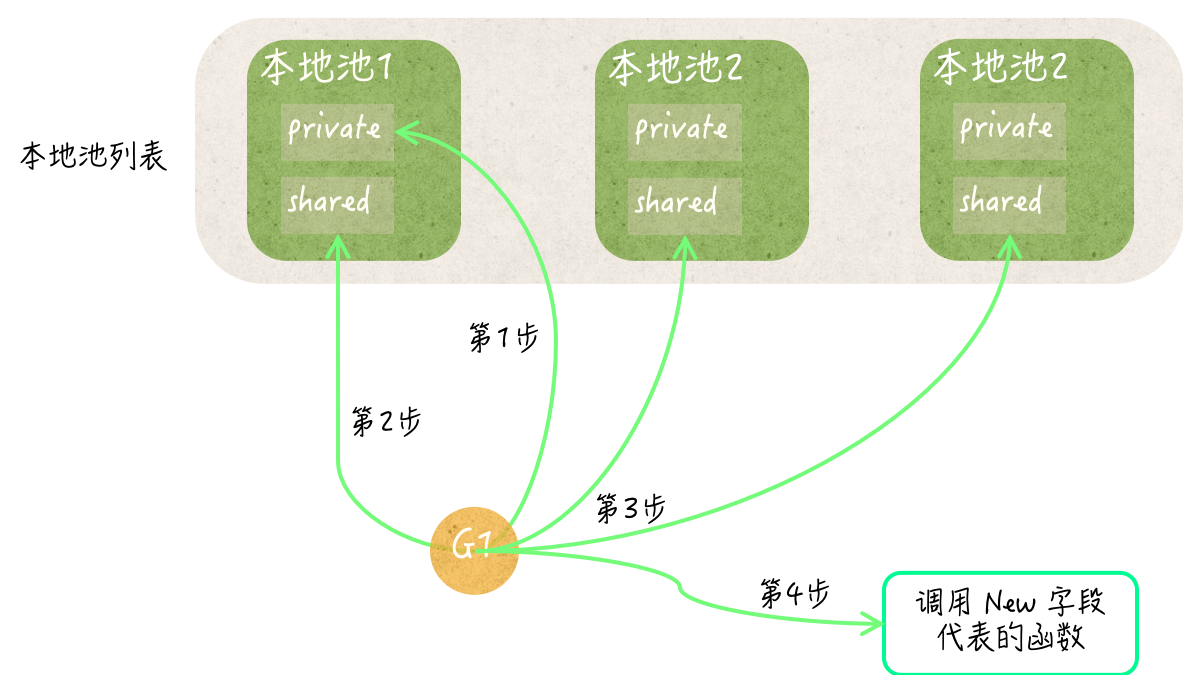
Put方法的执行流程
- 基于P的运行ID找到本地池
- 查看私有对象是否为空,是的话就直接写入
- 否则就插入到共享临时对象列表的队首
-
Get方法的执行流程
- 基于P的运行ID找到本地池
- 查看私有对象是否不为空,是的话就返回该对象
- 检查共享临时对象列表是否有值,有则弹出队首
- 检查其他本地池的共享列表是否有对象,有的话弹出队尾
- 如果都没有,调用New函数
临时对象的清理
在sync包初始化的时候会向go语言运行时系统注册一个函数。该函数会清除所有已创建的临时对象池中的值(池清理函数)。该函数会在每次即将执行垃圾回收时运行。
而sync包中有包级私有的全局变量,该变量汇总了所有临时对象池,当sync.Pool对象第一次执行Put或者Get的时候就会将其自身添加到该列表中。
而池清理函数就会遍历池列表,将私有临时对象和共享临时对象列表置为nil,然后销毁所有临时对象池,最后将该列表重置为空的切片,从而完成了清理过程。可想而知,如果对象池拥有对对象唯一引用,在清理之后就会在垃圾清理中被清除。这也是为什么我们提到Pool可以在未经提醒的时候删除引用甚至回收内存的原因。
1.13版本下的sync.Pool变更
1.13版本对sync.Pool的改动主要包括两点
-
之前对于shard的访问都是加锁完成的,现在改为无锁(lock free)
简单来说,有锁实现下Get/Put操作和清理池不同步,从而导致Get/Put操作可以返回已经被清理的缓存池的引用,导致无法被GC回收。为了避免这种情况,清理池的过程是“清理所有对象”,时间复杂度为O(# object of all pools)。由于池清理操作发生在STW时候,会显著增加GC所需时间。
而修改为无锁之后,Get/Put操作可以与池清理操作同步,因此池清理只需要简单的解除对池的引用,时间复杂度为O(# pool),从而大大提高了性能。
有几个问题可能需要进一步解释:
-
为什么Get/Put操作和清理池不同步?
清理池操作发生在STW的时候,如果需要和清理池操作保持同步,只需要使用pin/unpin方法,在pin状态下,goroutine相当于绑定在指定P上面,不能中断,而垃圾收集器(collector)会等待goroutine调用unpin解除绑定才能进入STW状态,因此不会并发清理池操作。
遗憾的是,1.13以下Get/Put操作用mutex来保护本地池的分享列表(shared),而pin状态下是不能上锁的,否则在特定时序下会触发死锁。
-
(可忽略)为什么pin状态下不能上锁?
假设发生了下面的序列事件:
M1:获得锁1
M2:pin
M2:尝试获得锁1(此时阻塞了)
M3:开始stop the world
M3:停止了M1操作
M3:尝试停止M2,但是由于M2被pin,所以失败
这个时候我们会发现已经陷入了死锁:M1被停止了无法运作因此不能释放锁1,而M3在等待M2pin(然后完成标记启动之后才能启动M1),而M2则在等待锁1
因此pin状态下不能上锁
因此1.13版本下Get/Put会需要先unpin,上锁,然后pin住。而unpin之后就意味着Get/Put和池清理是可以并行的,因此是不同步
-
-
不同步带来什么问题?
我们不妨截取Put方法的部分片段来解释
//上“锁“,此时GC不会发生,同时返回该Pool对应该P的PoolLocal l := p.pin() //检查private,这里是没有问题的 if l.private == nil { l.private = x x = nil } //这里发现private已经有了,就需要加入到shared中,为了同步Get/Put方法,需要上锁,而如上所述,必须先unpin runtime_procUnpin() //注意下面的代码是可以发生在池清理前或者后 if x != nil { l.Lock() l.shared = append(l.shared, x) l.Unlock() }由于不同步,如果发生下面的时序,就会导致GC标记的时候忽略了该pool
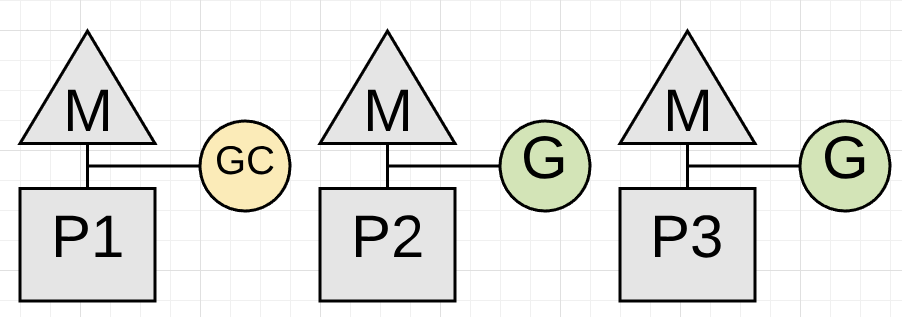
-
那么无锁实现怎么解决问题呢?
答案很简单,无锁下,不需要在访问shared的时候unpin了,因此Get/Put操作可以与池清理操作同步
因此池清理操作变为简单的将对池的引用置为nil,以及将池的Local置为nil,将时间复杂度变为O(# pool)
-
-
将“每次都清除所有缓存”改为区分victim和active。
旧版本下,每次GC都会触发清除池中所有对象的操作。新版本中变更为将victim池清空,将现有池(active池)设置为victim池。而Get操作在active池没有对象的时候会去victim池获取,之后当然一般也会Put回去。这样的实现在应用进入稳定状态的时候(也就是说Get,Put频率大致相同)不会产生任何不必要的分配,只是在将对象从active迁移到victim然后迁移回active。而在速度不匹配的情况下,也会在两次GC之后清理缓存。
这样做的目的在于
-
避免GC触发短时间大量的分配
旧版本的实现会清除所有的缓存,在高请求下这会导致短时间内会触发大量的New操作从而提高时延,对于部分有着软实时限制的应用不友好。除此之外,旧版本的实现定位为“两次GC之间的重用”,因此性能会依赖于请求频率与GC频率的对比:换言之,请求频率越高的应用受益于sync.Pool越多,而请求频率越低的应用可能受益越少。遗憾的是,GC频率是一个会受应用其他部分影响的因素,因此这使得性能可能会不稳定。
-
降低不必要GC的频率
在应用进入稳定状态的时候,Pool中的对象本质上是长期的(long-lived),它们被一次创建,然后就不停的被使用。但是在旧版本实现中,计算GC trigger和goal的时候将Pool中对象视为短期对象(short-lived),从而过频繁地触发GC
-
1.13版本下的sync.Pool实现具体分析
首先是在Pool结构体定义中增加了victim和victimSize
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
New func() interface{}
}
然后当触发GC的时候,会将victim池置空,将active池转换为victim池。在Get请求中,会先访问active池,直到确定没有之后才会访问victim池。Put请求则不会涉及到victim池
除此之外,还使用了一个双向链表实现的无锁队列作为P的shared队列,当是在自己的P对应的队列中的时候总是在Head加入(Push)或者取出(Pop),从而更好地利用局部性原理。而访问别的P对应的shared队列的时候则在tail取出
sync.Pool陷阱
sync.Pool同等对待所有对象,这意味着缓存的内容大小应当尽可能一致。否则可能会无意间占用大量的内存,其中容易让人忽略的就是bytes.Buffer等内部数据可以grow的结构。
比方说,如果每隔1s会生成一个256MB的buffer存入对象中,而其他所有请求只需要一个2KB的缓存。请求会不停的从缓存池中获取buffer,因此这些持续生成的大内存占比的buffer一直被Get请求调用并使用,GC无法对此进行处理(因为被引用)。
在1.13之后,由于引入了victim,情况只会变得更加糟糕:如果说之前版本在若干次GC后有机会清理这些大内存buffer,那么victim将确保这些大内存一直不被清理(因为一直被请求使用)
对此,一个较为明智的办法是:限制传入pool的buffer大小,比方说如果某个结构体体积大于指定值,那么就不调用Put。
但是如果有些时候,我们处理的请求的确会涉及到不同提及的buffer怎么办呢?我们可以分若干个Pool,不同的Pool存储的buffer大小不同。
总而言之,解决这个问题的办法有很多,最重要的是识别出这个问题并选择一种办法
