一、什么是字符串匹配呢?
给定一个母串,再给定一个子串,要在母串中找是否有与子串对应的字符串
例如:母串S:ABABAC
子串P:BAB
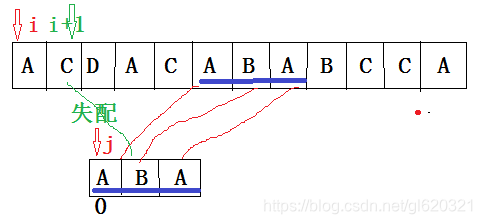
方法一:一般做法(时间复杂度很高)
利用指针Si和指针Pj作比较
如果它们相同就i+1,j+1;如果到某一个地方不同,称为失配。
当出现失配,把i退回之前标记的位置向后移动一个i+1的位置,j变为0回到起始点。一直重复上面操作。
直到i找到对的位置记为k,k位置和P0作比较,后面都符合匹配,两个指针一直向后移动,做++操作,当连续累计匹配个数等于P的长度时候,称为找到合适位置,返回m.
原因:假设S的长度为m,需要将母串S的字符都要作为起点,需要做m次匹配
假设P的长度为n
则它们的时间复杂度为0(n×m)
方法二:哈希法RabinKarp
hash-----滚动hash
思路:在子串P把字符串求出一个整数值,例如3个字符求出一个值;任意多个字符按一定顺序排列(字符序列,字符串)都可以求出一个值。这个值称为哈希值。
对S采用同样的算法,从起点开始,对每3字符序列的哈希值求出来。
算出来之后比对哈希值。
在母串S中求值只需要m次
在子串P中求值需要n次
先对P求哈希,o(n)
对S求哈希,o(m)
此时它们的时间复杂度仍为o(m×n),并未降低
求哈希hash
把若干个字符按进制的方法做一个转换,假设一个种子值为31进制,
在P子串中
C ^0 × 31^2+ C^1 ×31^1+C2
这样代码不好写,改进
((0+C0)×31+C1)×31+C2
什么是滚动hash,我求出第一个长度为n的子串的hash值,根据hash计算的特点,算第二个子串的hash值得时候不用再算,用第一个hash值×C(种子的值)+新增的字符元素值-第一个元素的值
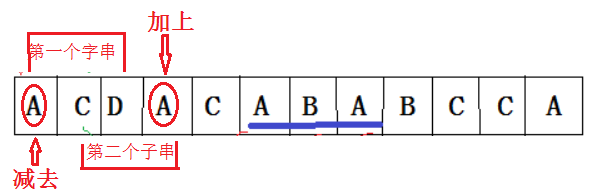
在算每n个(在这道题里面是3个)子串hash值的时候,将它们组成一个数组。
先求P子串的hash值,再求S母串的hash,m次
有hash数组之后,把母串S数组扫描一遍,匹配与子串P相同hash值时m次
o(2m+n)
再这个题目中每三个元素的hash值,一开始需要三次,后面只需要1次
滚动hash:时间复杂度0(n+m)
- 代码:
package rabinkarp;
import org.Lanqiao.rabinkarp.elementary.NExponent;
/*滚动hash法
* 对目标字符串按d进制求值,mod h取余作为其hash
* 对原串,依次求出m个字符的hash,保存在数组中(滚动计算)
* 匹配时,只需比对目标串的hash值和预存的原串的hash值表*/
/*S:母串 P:子串*/
public class Rabinkarp {
public static void main(String[] args) {
String s="ABABABA";
String p="ABA";
match(p,s);
}
private static void match(String p,String s) {
long hash_p =hash(p); //p的hash值
int p_len=p.length();
for(int i=0;i+p_len<=s.length();i++) {
long hash_i=hash(s.substring(i,i+p_len));//i为起点,长度为plen的子串的hash值
if(hash_i==hash_p) {
System.out.println("match:"+i);
}
}
long[] hashOfS=hash(s,p.length());
match(hash_p,hashOfS);
}
private static void match(long hash_p,long[] hash_s) {
for(int i=0;i<hash_s.length;i++) {
if(hash_s[i]==hash_p) {
System.out.println("match:"+i);
}
}
}
final static long seed=31;
//n是子串的长度
//用滚动hash法求出s中长度为n的每个子串的hash,组成一个hash数组
static long[] hash(final String s,final int n) {
long[] res=new long[s.length()-n+1];
//前面m个字符的hash值
res[0]=hash(substring(0,n));
for(int i=n;i<s.length();i++) {
char newChar=s.charAt(i);
char oldchar=s.charAt(i-n);
//前n个字符的hash值*seed-前n字符的第一个字符元素*seed的n次方
long v=(res[i-n]*seed+newChar-NExponent.ex2(seed,n)*oldchar)%Long.MAX_VALUE;
res[i-n+1]=v;
}
return res;
}
private static String substring(int i, int n) {
// TODO Auto-generated method stub
return null;
}
/*使用100000个不同字符串产生的冲突数,大概在0-3波动,使用100百万不同的字符串,冲突数大概在100+范围波动*/
static long hash(String str) {
long h=0;
for(int i=0;i!=str.length();i++) {
h=seed*h+str.charAt(i);
}
return h%Long.MAX_VALUE;
}
}
