0x00 获取请求头
1. 设置Fiddler
到Fiddler官网下载最新版Fidder,然后安装。接下来对其进行设置。点击【Tools->Options…】打开设置面板。选择【HTTPS】选项卡,将【Decrypt HTTPS traffic】勾上;
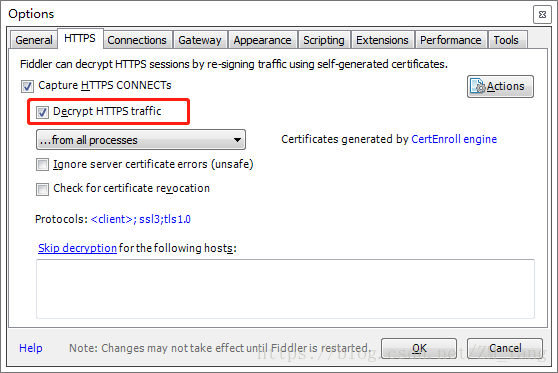
选择【Connections】选项卡,将【Allow remote computers to connect】勾上,保存退出设置。记住端口号,一般默认8888即可。
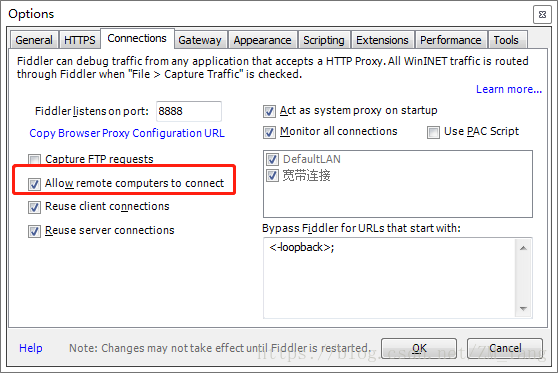
2.设置手机
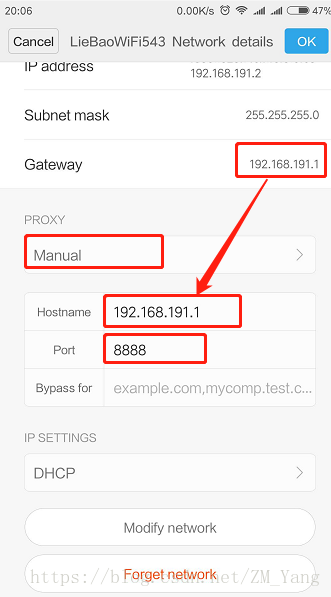
将手机连入电脑所在局域网(我这里是直接用电脑开启WiFi),进入到WiFi设置界面,如下图,代理选择【手动】,IP一般填写网关IP即可,如果手机上不显示,可以将鼠标放置Fiddler界面右上角【Online】处,即可查看到IP地址,端口填写刚刚设置的端口,这里是【8888】,点击保存。
打开手机浏览器,随便浏览个网址,这是浏览器会提示你有证书不受信任等风险,点击继续即可。
3.获取请求头
打开手机摩拜应用,这事会看到Fiddler捕获了很多请求,其中有很多是包含【mobike】字样,这就是摩拜的请求信息。
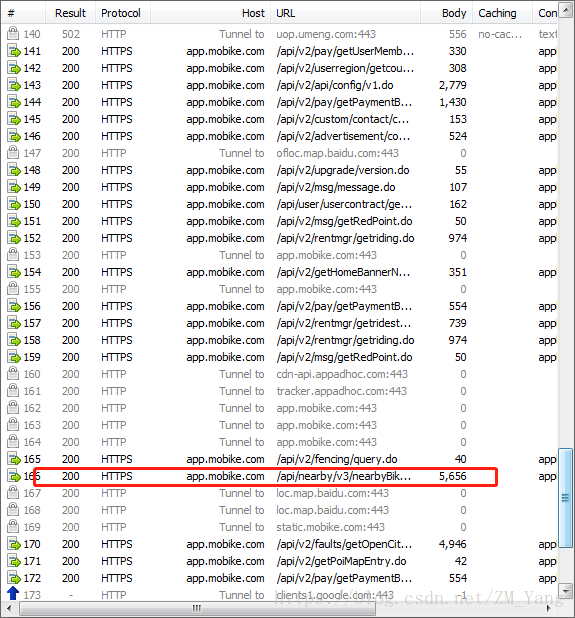
其中找到一个包含【nearby】字样的请求,这就是我们需要的自行车信息请求点看查看内容。
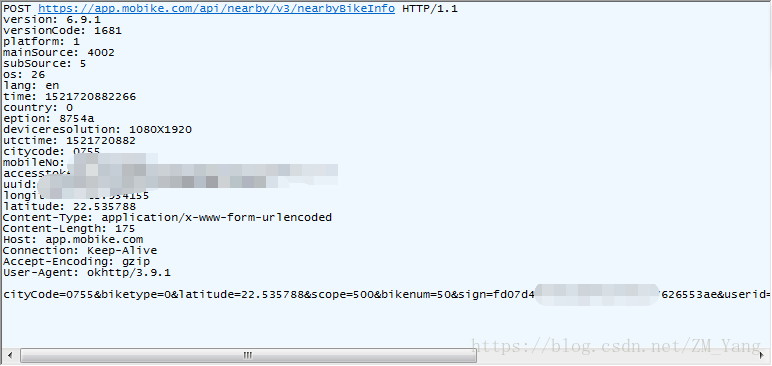
这就是我们需要的请求头的内容。到这一步,前期准备已经完成,接下来就该模拟请求获取单车信息了。
0x01 单车信息爬取
将刚刚捕获的请求头信息,用Python封装一下,便可以发起模拟请求,我这里去除了用户信息,虽然这样亦可以请求道,但是相比有用户信息的每次获取到的信息会更少:
def makeRequest(lat, lng) :
utcTime = int(time.time())
localTime = int(utcTime * 1000)
url = 'https://app.mobike.com/api/nearby/v3/nearbyBikeInfo'
HEADERS = {
'version': '6.9.0', 'versionCode': '1680', 'platform': '1',
'mainSource': '4002', 'subSource': '5', 'os': '25', 'lang': 'en',
'time': localTime, 'country': '0', 'eption': 'daf2b',
'deviceresolution': '1080X1920', 'utctime': utcTime,
'uuid': 'fc2567c5371315217a9abd7a57f45326',
'longitude': str(lng), 'latitude': str(lat),
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': '144', 'Host': 'app.mobike.com',
'Connection': 'Keep-Alive', 'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.9.1'
}
DATA = ('scope=500&sign=edaf3f37e2343f2fe63ff85f156f66b4&client_id=android&biketype=0&longitude=' \
+str(lng)+'67844588&latitude=' + str(lat) + '423412055&bikenum=50').encode('ascii')
try:
print('Request bikes at ' + str(lat) +','+ str(lng) + ' at ' + str(datetime.datetime.today()))
request = req.Request(url, data=DATA, headers=HEADERS, method='POST')
html = req.urlopen(request)
return html.read().decode('utf-8')
except Exception as e:
print('Network error..........')最核心的功能有了,接线就是将所需要爬取的地区进行切块,一片片区域进行爬取即可,如将深圳地区切分如下:
def main():
tag = input('Please input the tag:')
regions = [[[22.590715,113.884621],[22.518424,113.975601]],[[22.560281,113.975601],[22.519851,114.035168]],
[[22.566147,114.029160],[22.516363,114.079285]],[[22.573755,114.072418],[22.531110,114.144516]],
[[22.647126,114.100227],[22.598322,114.163399]],[[22.528097,113.885307],[22.479886,113.957062]]]
for region in regions:
crawlRegion(region[0], region[1], tag)核心的爬取代码就这些,剩下的就是解析和存储。因为返回的信息是JSON格式,用Python内置的JSON解析器就能解析。接下来就是存储了,对于这种数量不大的数据,使用SQLite进行存储即可,非常方便。关于Python中SQLite的使用方法,可以参看Python中使用SQlite的相关介绍。
def parseJson(conn, jsonStr, company,tag):
try:
bikes = json.loads(jsonStr)['bike']
date = str(datetime.date.today())
#conn = sqlite3.connect('ShareBikes.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS Bikes
(id text, lng real, lat real, bikeType integer, date text, company text, ''' \
+ '''region text, tag text, PRIMARY KEY (id, company, tag))''')
for bike in bikes :
id = bike['distId']
lat = bike['distY']
lng = bike['distX']
region = getRegion(lat, lng)
bikeType = bike['biketype']
try :
storeToDb(c, id, lng, lat, bikeType, date, company, region, tag)
print('Store bike ' + bike['distId'],':',bike['distX'],',',bike['distY'])
except sqlite3.IntegrityError as e:
print('In ' + date + ' has crawl the bike ' + id + ' of ' + company + ',try update')
#updateDb(c, id, lng, lng, bikeType, date, company, region)
conn.commit()
except TypeError as e:对于摩拜单车信息的爬取,主要就是这些。完整代码后续整理后将会上传。
0x02 关于反爬
摩拜目前貌似对爬虫并没有限制,我刚开始每秒请求一次,到后来请求一次处理完便开始请求,一直没有被限制。所以,目前来看,爬取摩拜并不需要做更深的伪装。不过,毕竟这也会对别人服务器增加一定(可能很小)的负担,但是尽量把请求速度降到能接受的最低吧。
