import urllib.request
import re
import time
import random
import os
def getPic():
url='http://www.wmpic.me/'
path='E:/picture/'
rdnum=random.randint(96000,96999)
url=url+str(rdnum)
if not os.path.exists(path):
os.makedirs(path)
try:
html=urllib.request.urlopen(url)
htmls=html.read().decode(encoding='utf-8',errors='strict')
src=re.findall(' src="(.*?[^0-9].jpg)"',htmls)
for link in src:
print(link)
urllib.request.urlretrieve(link,path+'%s.jpg'%time.time())
except urllib.error.HTTPError as e:
print(e.code)
getPic()
-3-23这样爬好像有点乱不是我想要的,现在想想爬下分类的图。那就爬分类的图看看。有了以下代码;
import urllib.request
import re
import time
import os
def getPic():
url='http://www.wmpic.me/tupian/qingxin/page/'
urlpg='http://www.wmpic.me/'
path='E:/qxpicture/'
url=[url+"{a}".format(a=str(i)) for i in range(1,3)]
if not os.path.exists(path):
os.makedirs(path)
try:
for ur in url:
page=urllib.request.urlopen(ur)
pages=page.read().decode(encoding='utf-8',errors='ignore')
href=re.findall('<a target="_blank" href="(.*?[0-9])">',pages)
print(ur)
for pageur in href:
html=urllib.request.urlopen(urlpg+pageur)
htmls=html.read().decode(encoding='utf-8',errors='ignore')
src=re.findall('<img src="(.*?[^0-9].jpg|.*?[^0-9].png)"',htmls)
for link in src:
print(link)
if link[0:4]=='http':
urllib.request.urlretrieve(link,path+'%s.jpg'%time.time())
except urllib.error.HTTPError as e:
print(e.code)
getPic()
;
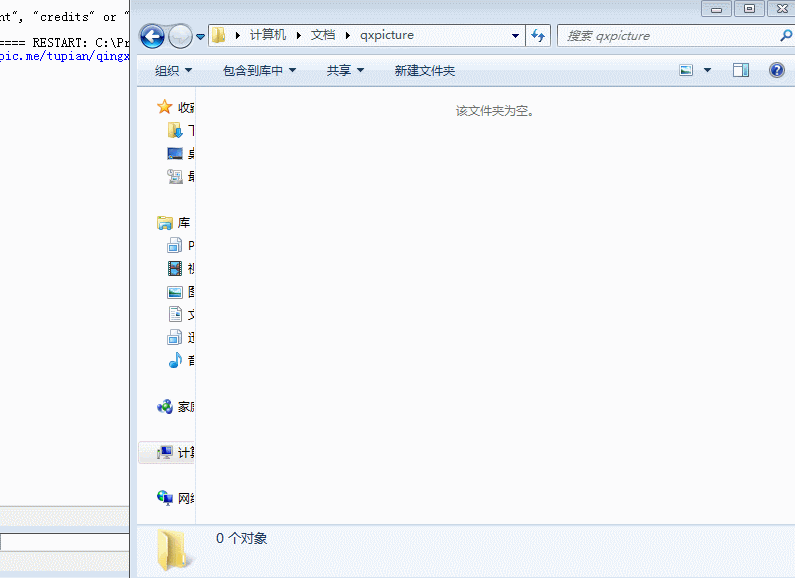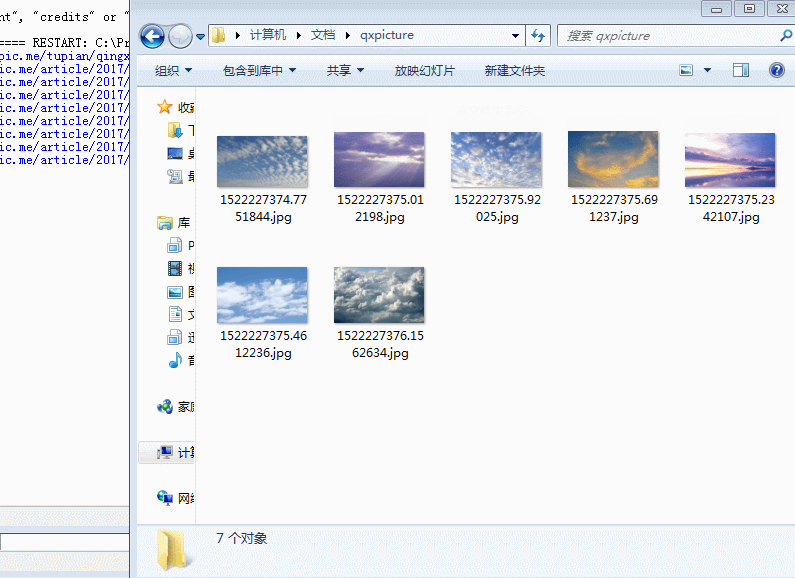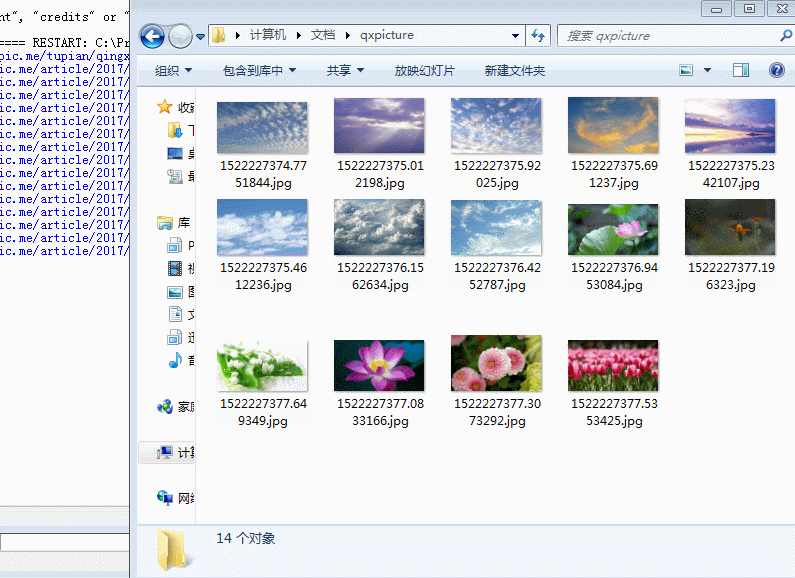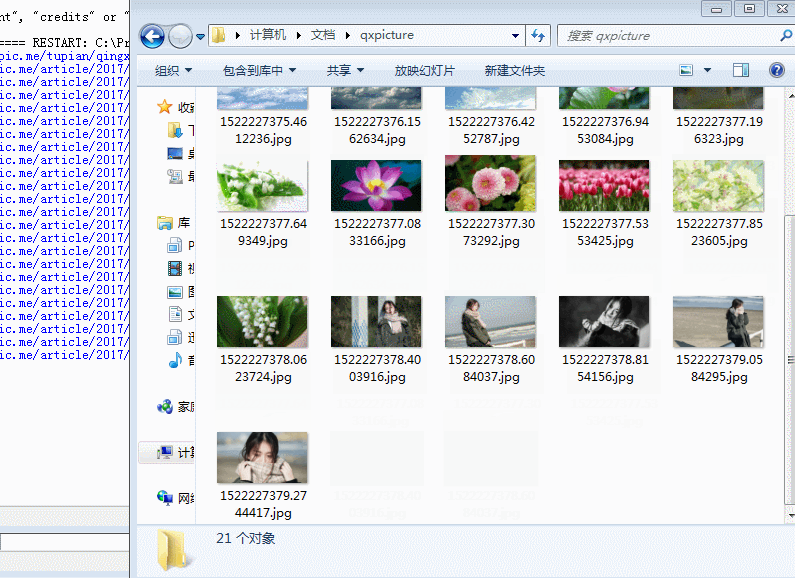
-3-28发现下载的图片混入了其他类图,查看了一下网页,原来右边猜你喜欢的图也抓取下来了,所以想办法过滤。
import urllib.request
import re
import time
import os
def getPic():
url='http://www.wmpic.me/tupian/qingxin/page/'
urlpg='http://www.wmpic.me/'
path='E:/qxpicture/'
url=[url+"{a}".format(a=str(i)) for i in range(1,3)]
if not os.path.exists(path):
os.makedirs(path)
try:
for ur in url:
print(ur)
page=urllib.request.urlopen(ur)
pages=page.read().decode()
href=re.findall('<div id="mainbox">(.*?)<div id="sidebox">',pages,re.S)
for href1 in href:
href=href1.replace('\r','').replace('\n','').replace('\t','')
href=re.findall('<div class="post"><a target="_blank" href="(.*?[0-9])"',href)
for pageur in href:
html=urllib.request.urlopen(urlpg+pageur)
htmls=html.read().decode()
src=re.findall('src="(.*?[^0-9].jpg|.*?[^0-9].png)"',htmls)
for link in src:
print(link)
if link[0:4]=='http':
urllib.request.urlretrieve(link,path+'%s.jpg'%time.time())
except urllib.error.HTTPError as e:
print(e.code)
getPic()
如图;