redis持久化有一定缺陷的,单点是解决不掉的,有的时候需要用多节点,节点之间需要协调,官方提供了多种解决方案:
1.主从复制 replication
2.高可用 sentinel,redis高可用必须用
3.集群 cluster
目前企业用的很多还是2.0,2.8,3.2,3.0最主要的是提供了集群,官方的cluster,3.0的sentinel的高可用集群。必须要用,只要是有多台redis,肯定要用。
高可用就是怎么都能用,单节点是一定会出现故障的,集群一般都建议三台,这时候有些分布式服务要选老大,就要决出胜负,不然脑裂
一般高并发的机器要多台来解决,一个人扛不住多台机器一起扛,顺带就实现了高可用,高并发解决方案,要么水平扩展,要么垂直扩展。
一主可以多从,还可以读写分离,master做写操作,slave只做读操作,客户端可以任意链接一个slave执行读操作,降低主服务器的压力

三种实现方式

1,启动的时候就告诉从服务器是谁

链接到一个redis从服务器,告诉它从属哪个redis服务器。salve no one 就是不从属任何一个人,这样就恢复为master。默认都是master

在配置文件也可以做这个事情

一般起redis都会做主从

虽然之前用service redisd start启动了一个,但是redis-server可执行文件还可以再起一个,指定端口6380,作为本机原先启动的6379的从

这样就启动在前排

6380起来了

链接指定端口6380

说明有数据

master是6379

6380这里就有数据了

这样主从同步就实现了

在从这里写一下,提示从服务器根本没有写的资格

现在把配置改改,现在只读状态已经没有了,不属于任何主机,就自己是master了

这边已经告诉你主从部分取消了

6379设定一个master1 =100

slave没了,也就是主从同步,根本不关心原来有什么,从服务器只要跟主服务器一致即可,原来的数据全部清理掉

如果是读写分离,前面可以写一个程序,读操作可以在列表中选择任意一个访问,写操作就指定哪个为主就可以了

主从复制会让从跟主是一样的数据,slaveof no one就可以解放自己
现在这样主从复制,单点失败。切来切去太麻烦了,一个挂了,另外就顶上来,这就是高可用

主从复制出现了上述单点问题,切换服务器的问题,官方提供了sentinel哨兵,也就是第二种高可用方案,主从复制是他的基础,后面的集群也是基于这个基础来创建的,哨兵能找到主从复制中主或从的问题,从一般会有多从,比如一主二从,一旦主下线了,就要考虑选谁当新的主,选好了要迁移

sentinel
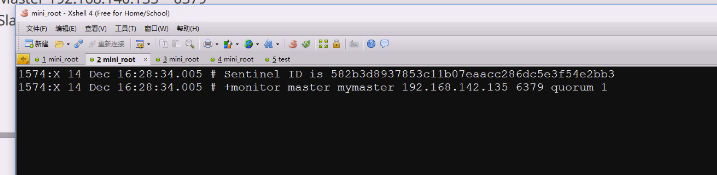
高可用sentinel,是启动了一个哨兵sentinel这样一个角色,但这个角色也是一个服务,这个哨兵服务就是实际上是redis-server,之前看是软链接,指向了redis-server

哨兵实际上就是redis-server
 在哨兵后面指定配置文件即可,如果用server启动就在后面加长选项-sentinel,server读取哨兵配置文件启动就可以作为一个哨兵了
在哨兵后面指定配置文件即可,如果用server启动就在后面加长选项-sentinel,server读取哨兵配置文件启动就可以作为一个哨兵了

哨兵可以形成一个哨兵网络,是一个特殊的服务,服务之间形成哨兵网络,并且相互通信。
单独的哨兵可以监控主服务器,不需要监控从服务器,因为监控主服务器的时候,就知道从服务器有谁了,就可以了解到,主服务器挂了,就会有动作

哨兵还可以管理多个服务器,实际上可以监管多个服务器
哨兵会形成一个哨兵网络,会内部通信,其实就是哨兵的分布式服务,之间相互通信

当master下线的时候(分主观下线,单个sentinel认为下线,客观下线,都说它下线,多个sentinel通信确认服务下线)

主服务器挂了,几个sentinel都说看到了,就达到 一定的数目,从主观下线变成了客观下线,(其实有个投票数)就按照你的配置,客观下线就是拿掉主的能力,投票超过半数,从服务器s2提升为主服务器,之后会让另外的从服务器s3重新指向现在是s2主服务器

现在s3就指向了s2,但是s1回来了,想当老大,但是哨兵不允许,被迫将自己从主状态变成从状态,并且指向s2,所有主从的切换都由哨兵来完成。
有些操作很浪费时间,就可以让从服务器来做操作,比如RDB保存

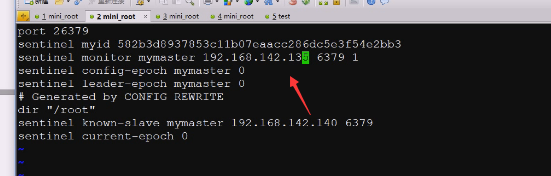
sentinel monitor mymaster 127.0.0.1 6379 2
mymaster 就是主节点的标识符是什么
172。。。。。 主节点工作地址
2是投票,至少需要2个sentinel说认为下线了,才达到主观下线的数量,就把现在的主下去,提升一个从作为主
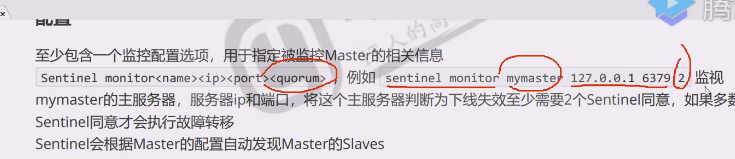
这个解决了我们现在监控谁,而且怎么判断下线的问题,为什么写2票,因为一般认为sentinel有三台,3个里有两个说了才算数,多数压倒少数,大多数分布式集群都需要用过半原则
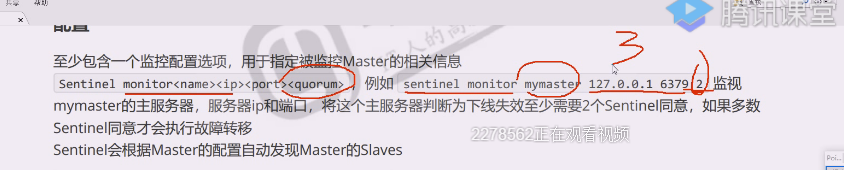
sentinel down-after-milliseconds
监控到指定的集群的主节点异常状态持续多久方才将标记为“故障”;超过这个时间,就主管认为下线了

故障恢复如果超时了,就认为恢复故障转移也失败了

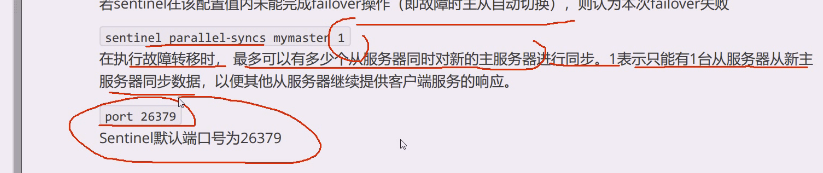
在故障转移时,最多可以有多少个从服务器对新的主服务器进行同步,1表示只有一台从服务器对新主服务器同步数据,这样就减少新主的压力。
默认内部通信端口26379
开启两台机器做演示

另外也安装下

make一下

缺省应该是放user/local/bin下了

安装服务脚本

但是现在的服务是监听在本地


监听地址加一下
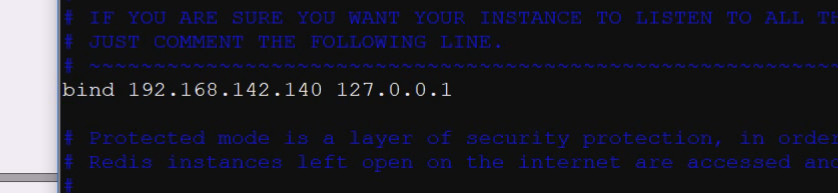
缺省就职10000

这里就直接配置里直接些从属于哪个个

启动服务

现在已经从主那边获取数据了

需要解除 就可以用命令行,slaveof no one

在主服务器这边看一下sentinel文件

这里是留下的,可以删除中间的蓝色说明文字

这里就是现在看到的
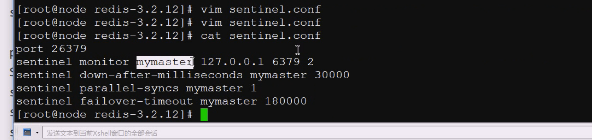
监视谁起个名字,至少2个同意才能成为主
sentinel monitor mymaster 182.。。。。。
mymaster就是主节点的标识符是什么
182.。。。。。 主节点工作地址
6379 端口
2 需要多少个sentinel节点投票同意这个集群某一节点,才能通过,有3个至少2,有5个至少3
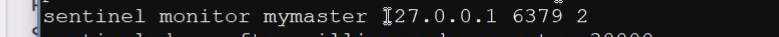
监控到指定的集群的主节点异常状态持续多久方才将标记为“故障”;
30000=30s 30秒链接不到就认为down

一次最多给几个从节点完成同步

故障转义多长时间完成不了,就认为超时,可能需要重新启动故障转移

拷贝到家目录里
投票数改成1,就满足1票就下线了
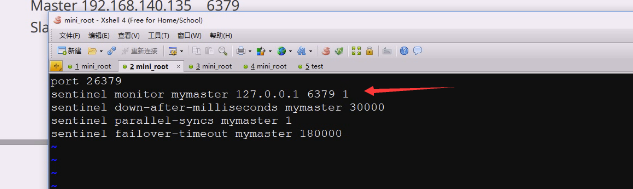
把sentinel启动起来

最好把地址改下

再次启动下

现在主从还存在,写个值看看

从服务器就同步到了

26379是哨兵在跑

现在把主服务器下线

主观下线会有个超时时间
投票 ,1/1,自己说了算,投票选出它作为主

现在能写入了

原来的主再次上线,配置文件里没有salveof 所以起来就认为是老大

让原来的主变成从





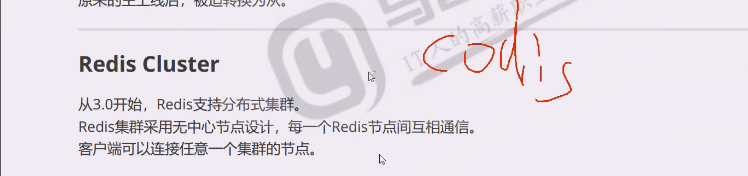
3.0之前,redis还是有很大问题的,用起来还是很不方便,比如分片的方案,把数据分散到不同的服务上去,codies要用到zookeeper来做数据存储,这些都是非官方集群解决方案。
现在可以用官方3.0真正的集群,还带高可用
redis cluster
提供了一种分布式集群的解决方案,采用了无中心节点的设计,每一个redis节点之间都需要通信,会把数据分散到不同节点存储,合起来是一个大的存储空间,每一个节点上只有一部分数据

可以理解abc内存连成一片,数据有些在A放有些在B放,但是没有副本

这种无中心节点也是有它的问题,谁说了都不算,这种,到达一定规模,通信成本也很高,有master的话,就可以让master来协调
 蓝色代表多个的主,三个主之间互相通信,这三个相当于内存连成一片,各自保存一部分数据,7000要是down了,只能它的slave,7003来顶了。
蓝色代表多个的主,三个主之间互相通信,这三个相当于内存连成一片,各自保存一部分数据,7000要是down了,只能它的slave,7003来顶了。
在这种集群服务里去掉了sentinel,sentinel是要经过投票谁来上。但是这里7000下了,由其他的主服务器7001,7002来商量选择7000的从服务器作为新的主服务器,所以原来sentinel功能,选举功能和故障转义功能都是放在主服务上的


把数据库分为16386个槽,这个数字就是0x4000,16进制4000,所有的key都会经过计算放到槽当中,这个槽就被分配到不同的服务器了

16384个槽位slot,一开始三个平均分配,

新来的数据放到那里去,会做crc16进制 运算得到数值给16384取模,余几放到谁那,只不过让你的数据更加规整,做了crc算法(循环校验的算法)得到值和16384取模,总会将一个数据放到某个地方,这个数据放好后,会到某个槽位,这个对应的槽位会在某一台主服务器上,也就是数据被分开放了,每一个服务器上都放了不同的槽位,这就是分片集群。
分别就是sharding

**redis集群是无中心节点的,可以连接任意节点,要请求一个key,连着个key,算一下就不再这个槽位了,如果在这个节点找不到会返回给你一个转向错误并且带上你请求的key应该在哪里,然后就可以通过客户端再次连接服务器,找到数据,因为数据在这个服务器的槽位里 **


它的集群是由多个节点组成分布式集群服务,具有复制,主从,高可用sentinel和分片特性sharding

集群没有带中心节点,并且带有复制和故障转移特性,并可以避免单个节点称为性能瓶颈,或者因为某个节点下线导致整个集群下线。
集群中的主节点负责处理槽,从节点是主节点调度复制品。
redis集群,整个就是16384个槽,每一个键都属于16384的一个槽位,每个主节点都可以管理槽,当16384个槽都有节点负责,集群进入上线状态,也就是但凡有槽位没有分布完成,集群不工作。
主节点只会执行和自己负责的槽相关的命令,不是自己的槽位会告诉你找谁,转向找能够处理这个节点的

2.8redis一般用sentinel,3.0用cluster,一部分不愿意动的就用codis,第三方的豌豆荚做的,用到 zookeeper。redis cluster把codis分布式服务和temproxy做切片的
其实集群就是通过转向可以给你找到想要的数据,既有主从,高可用和分片

