布隆过滤器: 我说它不存在,它 百分之两百 不存在!
(我说它存在,可能我有说错的时候...)
前言:
该篇文章将会使用最精简易懂的文字以及小图来给大家介绍讲解(不对哈希策略计算进行详解)
一.布隆过滤器有啥用?
二.布隆过滤器原理是什么?
三.java中怎么使用布隆过滤器?
本篇文章内容可能较多,所以还请耐心。
一. 布隆过滤器 有啥用
简单两点叙述:
1. 存值
存值,就是把值存进去, 类似于我们很常用的map,set等;
2.检验值是否存在
检验,也就是我们想知道某个值是否存在于布隆过滤器里面,调用相关的检验方法,我们会得知一个结果。
特别注意:
布隆过滤器校验值的结果, 如果返回结果是 false ,不存在, 那么是肯定不存在的!
但是如果返回结果是true,存在,也许有概率是误报的。
为啥? 看下面的实现原理你就能明白。
二.布隆过滤器 原理是什么
首先,从上边介绍的布隆过滤器作用来说,就是个存东西的容器。
但是这个容器有也有自己的特点,
1. 它是一个有固定的大小的,也就是一开始设置它能放多少东西。
2.校验元素的准确率(指 true 存在的准确率),是会随着存的东西越多而准确率会慢慢降低
怎么才能更好地理解这个所谓的原理?
我选择根据布隆过滤器的作用角度去给大家讲解。
首先是存值的原理
既然是可以存放值,然后后面又能校验存在与否,那么这个存值显然不是直接丢进去就好,是需要通过算法计算的。
那么这里我不对这个算法进行深入地介绍,但是我会以我的图文方式告诉你,过程和结果。
模拟场景
一个完全是空的布隆过滤器,是一个由m个二进制位构成的数组,这里我们假设就是m=5个构成的。

默认一开始,这5个二进制位,简单理解为位置, 都是绑定着一个标识 0.
那么接下来看怎么存值。
布隆过滤器存值,实际上不是存的 真实值,而且通过算法计算后,存入对应的标识。
过程简述,也就是布隆过滤器拿到我们传入的值, 它会将这个值,使用 K个 哈希函数去进行算法计算,计算完后,
会得出K个 二进制位的标识 0或者1 ,然后对应位置就会存入这个标识0或者1.
存值过程举例说明:
我们需要存入的值为 ‘JCTest’ ,
布隆过滤器会采取相关的 计算公式,来算出 需要使用几个 哈希函数,也就是K的数量:
(m是数组长度,n是插入的元素个数,k是hash函数的个数)
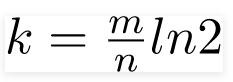
公式大家可以简单了解下, 我们现在假设 K 是 3.
也就是说 ‘JCTest’ 需要经过3个哈希函数计算 h1 ,h2,h3。
那么经过算法计算后, 得出的结果是:
h1算法对 ‘JCTest’ 的结果是,二进制 位置 是 一
h2算法对 ‘JCTest’ 的结果是,二进制 位置 是 三
h2算法对 ‘JCTest’ 的结果是,二进制 位置 是 五
那么这时候,对应的图会变成这样:
一,三,五 位置的标识此刻会绑定上1

同样,我们存入第二个值 ‘BFTest’,假设也是需要经过 3个哈希函数,
计算出的二进制位 分别是 二 ,三,五, 那么此刻的布隆过滤器如:

到这里,其实我们已经了解了这个布隆过滤器的存值方式, 直白的说就是,每个值对于它来说,都会转化成几个位置的 1 ,只要你往里面存,它就会把位置变成1 ,直到所有位置都变成1了,那么就不能再存了(大家不用担心这个位置会不会很快就都变成1,因为我这里只是举例了5个位置,后面的使用介绍环节会告诉你存上百万都不是问题,因为这些m值,K值,都会根据我设置的存入个数size和期待误判率进行算法生成的。)
接下来讲解布隆过滤器的校验值存在与否的原理:
很简单,其实也是我们告诉布隆过滤器一个值, 它也会通过K计算公式,取出一定数量的哈希函数,也是计算出很多个位置,
然后去一个个位置监测,如果每个位置都是1,这时候 它会返回true,告诉我们,这个值存在;
而如果只要存在一个位置是0,这时候,它会返回 false,告诉我们,这个值不存在。
校验举例说明:
如果我们想校验一个值 ,‘JCTest’,
布隆过滤器通过公式计算得出它准备使用三个函数 h1,h2,h3,
然后计算出对应的二进制位 一,三 ,五 ,接着去检查对应的位置上绑定的标识,如果都是1,那么就会返回存在 true。
误判举例说明:
那怎么会误判呢?
那就是例如,我们传入一个需要校验的值,‘CSDNTest’,布隆过滤器通过相关函数算出,位置恰好也是一,二,三 ,那我们实际上根本没存过CSDNTest,
但是因为我们之前存JCtest 和 BFTest 导致了相关的位置都绑定了标识1,所以这时候布隆过滤器就产生了误判现象。(这个概率不高其实,接下来的实用介绍会了解到)
PS: 也是因为这种校验的策略,所以只要在校验的时候,检测到一个对应的位置不为1,那么毫无疑问!这个值是百分之两百不存在的!
三.java中怎么使用布隆过滤器
了解了布隆过滤器的作用和原理后,那么我们接下来在java中使用它。
该篇就不去手动实现布隆过滤器了,因为 在GoogleGuavalibrary中Google为我们提供了一个布隆过滤器的实现。
所以我们第一步,导入jar包:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>然后建一个BloomFilterTest.class :
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @Author : JCccc
* @CreateTime : 2020/3/31
* @Description :
**/
public class BloomFilterTest {
private static int size = 1000000;//预计要插入多少数据
private static double fpp = 0.01;//期望的误判率
public static void main(String[] args) {
//存入的是字符串
BloomFilter<CharSequence> bloomFilterStr = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), size, fpp);
for (int i = 0; i < size; i++) {
bloomFilterStr.put("test" + i);
}
boolean containsValue1 = bloomFilterStr.mightContain("test1");
boolean containsValue2 = bloomFilterStr.mightContain("test34");
boolean containsValue3 = bloomFilterStr.mightContain("test1000001");
System.out.println(containsValue1);
System.out.println(containsValue2);
System.out.println(containsValue3);
}
}校验结果:

然后再试下,使用布隆过滤器存入数字:
BloomFilter<Integer> bloomFilterInt = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
for (int i=0; i<size;i++){
bloomFilterInt.put(i);
}
boolean containsValue4 = bloomFilterInt.mightContain(1);
boolean containsValue5 = bloomFilterInt.mightContain(2);
boolean containsValue6 = bloomFilterInt.mightContain(10000002);
System.out.println(containsValue4);
System.out.println(containsValue5);
System.out.println(containsValue6);
结果:

可以看到以上两存值&校验的测试都是准确无误的,那么我们大规模的存值检查,看看存在的误判现象:
我们刚刚往 bloomFilterInt 这个过滤器里面存入了0到1000000 个数字值,
那么接下来我们直接从1000000开始去累加到2000000,去进行校验,
我们明确知道 这时候的布隆过滤器里面有1百万个值,而我们的1000000到2000000除了‘1000000’其实都是不存在的,都应该返回false。
接下来我们用代码来模拟下这个判断存在 的误判现象:
int size = 1000000;//预计要插入多少数据
double fpp = 0.01;//期望的误判率
BloomFilter<Integer> bloomFilterInt = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
for (int i=0; i<size;i++){
bloomFilterInt.put(i);
}
int count = 0;
for (int i = 1000000; i < 2000000; i++) {
if (bloomFilterInt.mightContain(i)) {
count++;
System.out.println(i + "误判了");
}
}
System.out.println("总共的误判数:" + count);结果:

在这一百万个数值的布隆过滤器里面,再校验一百万次,存在的误判数是10314次。
所以咱们使用布隆过滤器进行值的存入和校验时,
我们应该更偏向使用 它返回的false 进行结合业务做操作,因为它的判断如果返回fasle,那是百分之两百可信的!
当然其实true误报的情况,概率也是非常小的,在一定的业务场景也能使用的其实。
ps:
例如,我们先到布隆过滤器查询一个订单是否存在,不存在就当失败订单处理;
存在的话,我们再去数据库获取详情信息进行订单的后续操作。
这时候只需要我们再接收到订单存入数据库的时候,把单独的订单号存入布隆过滤器即可。
就算布隆过滤器误判了,我们再去数据库查询订单时,加上多一步校验存在与否即可。
这样就可以减轻每个订单都需要查数据库的压力。
(其实有过了解redis使用的小伙伴,就明显知道布隆过滤器配和redis使用会非常不错,可以一定程度防止缓存穿透,这些我有时间会在我的redis栏目写一篇对缓存穿透和缓存雪崩的介绍和解决思路相关的文章)
那么这篇普及布隆过滤器就先到这吧。
