requests库是一个常用的用于http请求的模块,它使用python语言编写,可以方便的对网页进行爬取,是学习python爬虫的较好的http请求模块
requests库的安装
在这里,我是使用pycharm对requests库进行安装的,首先选择File->settings,找到Project pychram,点击右边的加号
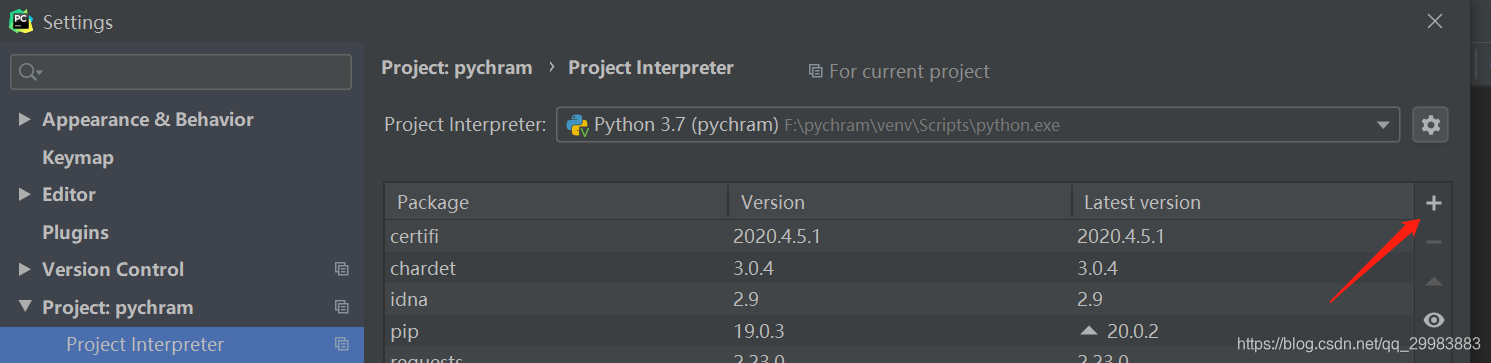
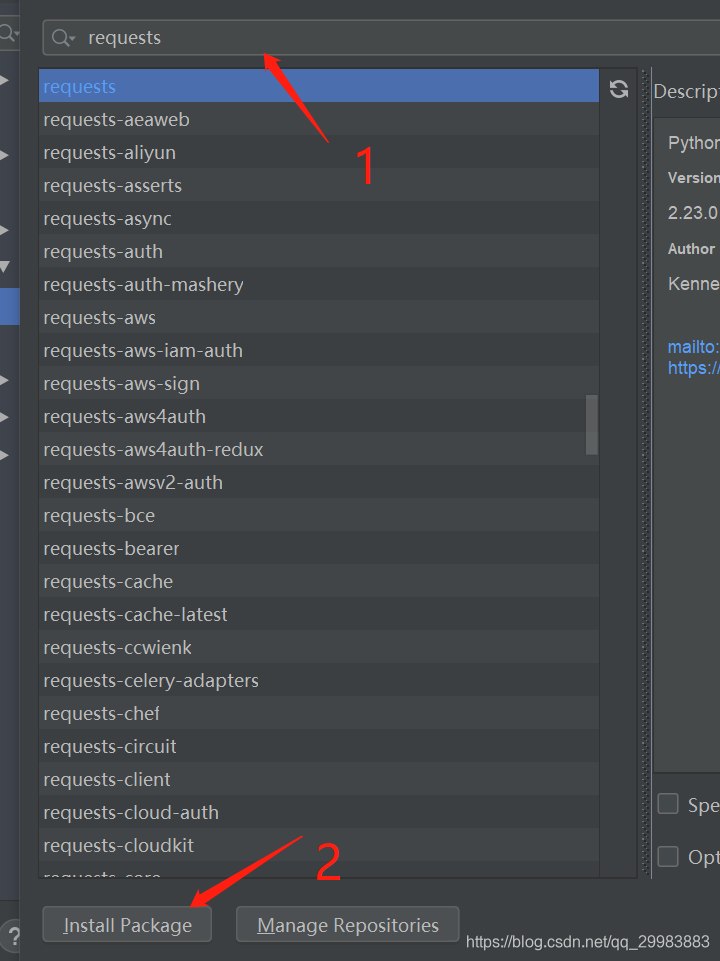
在弹出栏中输入requests选中,然后点击下面的install Package按钮,进行包的安装
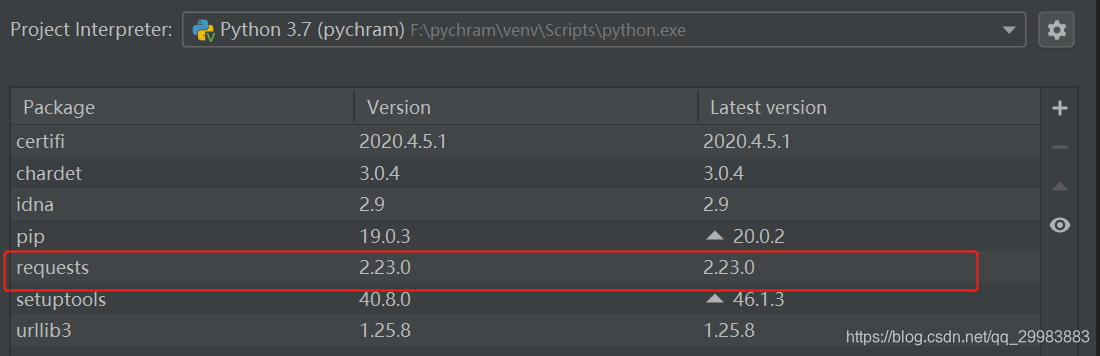
安装完成后,就能在之前一个界面查看到安装的requests
requests库的使用
request提供的方法
| 方法 | 描述 |
|---|---|
| requests.get() | 向服务器发送get请求 |
| requests.post() | 向服务器发送post请求 |
| requests.put() | 向服务器发送put请求 |
| requests.head() | 获取头部信息 |
| requests.patch() | 向服务器提交局部修改的请求 |
| requests.delete() | 向html提交删除请求 |
| requests.request() | 构造一个请求,支持以下各种方法 |
get
get(url,params,**kwargs)
- url: 需要爬取的网站地址。
- params: url中的额外参数,字典或者字节流格式,可选。
- **kwargs : 控制访问的参数
post
post(url, data=None, json=None, **kwargs):
- url: 需要爬取的网站地址。
- data:传递的内容。
- json:json格式传递的内容
- **kwargs : 控制访问的参数
requests
request(method, url, **kwargs):
- method:需要使用的方法
- url:爬行的路径
- **kwargs : 控制访问的参数
| 名称 | 描述 |
|---|---|
| data | (optional) Dictionary, list of tuples, bytes, or file-likeobject to send in the body of the :class:Request. |
| json | (optional) A JSON serializable Python object to send in the body of the :class:Request. |
| headers | (optional) Dictionary of HTTP Headers to send with the :class:Request. |
| cookies | (optional) Dict or CookieJar object to send with the :class:Request. |
| files | (optional) Dictionary of 'name': file-like-objects (or {'name': file-tuple}) for multipart encoding upload. file-tuple can be a 2-tuple ('filename', fileobj), 3-tuple ('filename', fileobj, 'content_type')or a 4-tuple ('filename', fileobj, 'content_type', custom_headers), where 'content-type' is a string defining the content type of the given file and custom_headers a dict-like object containing additional headers to add for the file. |
| auth | (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth. |
| timeout | (optional) How many seconds to wait for the server to send data before giving up, as a float, or a :ref:(connect timeout, read timeout) <timeouts> tuple. :type timeout: float or tuple |
| allow_redirects | (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to True. :type allow_redirects: bool |
| proxies | (optional) Dictionary mapping protocol to the URL of the proxy. |
| verify | (optional) Either a boolean, in which case it controls whether we verify the server’s TLS certificate, or a string, in which case it must be a path to a CA bundle to use. Defaults to True. |
| stream | (optional) if False, the response content will be immediately downloaded. |
| cert | (optional) if String, path to ssl client cert file (.pem). If Tuple, (‘cert’, ‘key’) pair. |
Response
通过上面方法返回的是一个Response对象,该对象有一下一些属性和方法
| 属性/方法 | 描述 |
|---|---|
| status_code | 服务器返回的状态 |
| text | 服务器返回的字符串,requests根据自己判断进行的解码 |
| content | 服务器响应内容的二进制形式 |
| encoding | requests猜测的相应内容编码方式,text就是根据该编码格式进行解码 |
| json() | 返回内容进行json转换 |
实例
实例1
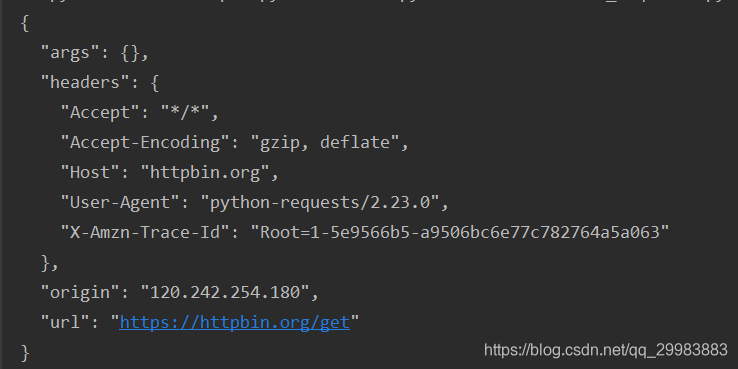
首先向https://httpbin.org/get获取发送的get请求
import requests
req = requests.get('https://httpbin.org/get')
print(req.text)
执行结果如下
实例2
通过get方法,使用百度查询关键字 新型管状病毒
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
data = {
"wd":"新型冠状病毒"
}
url = "https://www.baidu.com/s"
re = requests.get(url,params=data,headers= headers)
print(re.url)
with open("index.html","w",encoding="utf-8") as f:
count = f.write(re.content.decode("utf-8"))
print(count)
返回的结果

将上面结果的超链接复制到浏览器中,产生下面的效果,被百度察觉到了,
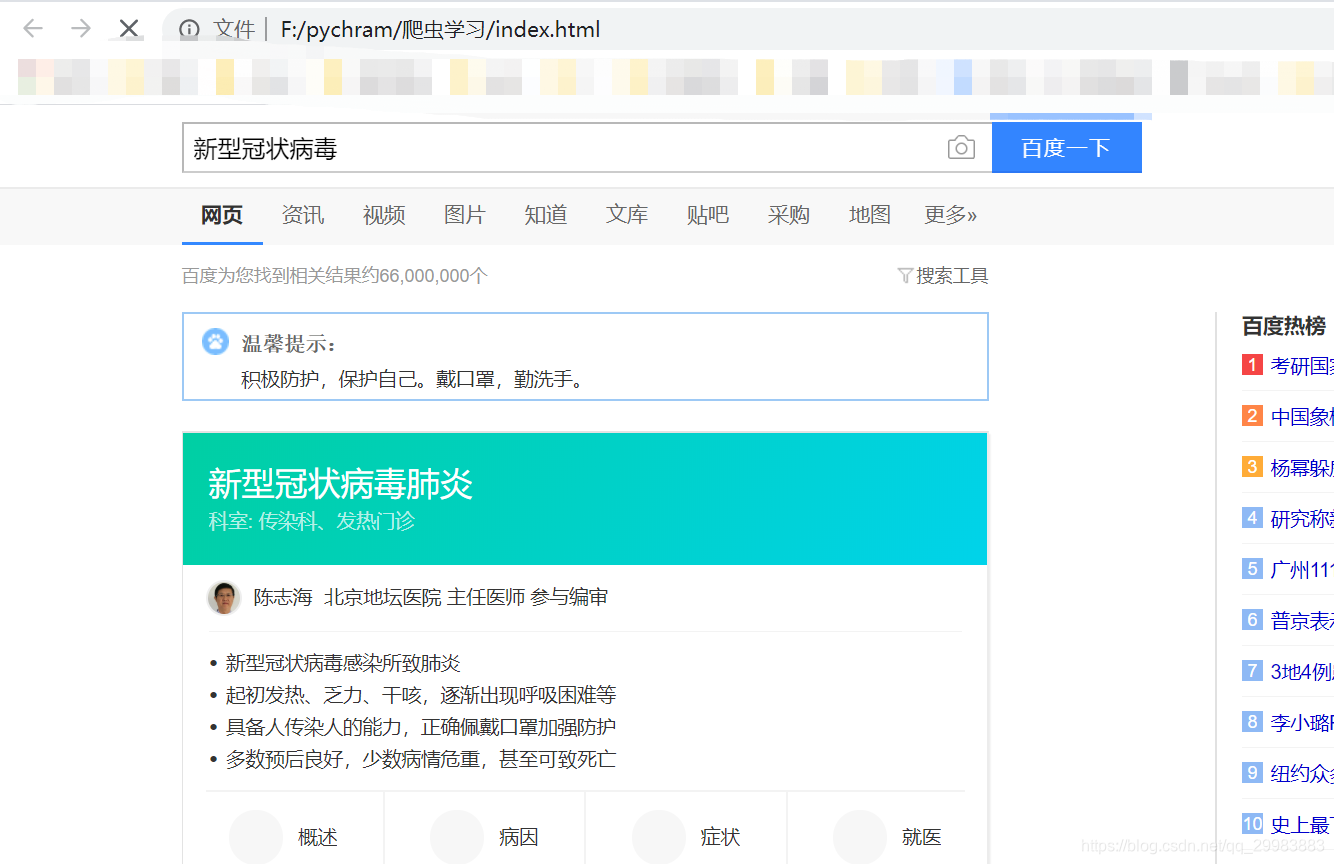
当我们在headers参数中加入Cookie时,就可以了。
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36",
"Cookie": "BIDUPSID=41BB40B30F5505BBAFB383EC2890356C; PSTM=1582981521; BAIDUID=41BB40B30F5505BB1B849015D5D91E79:FG=1; BD_UPN=12314753; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDUSS=hpSllZUVQ5U1JnZkVzdVBJMVp1MmZhUGd0OG9KVTYwTnJvY1dpTVlpeVpyN0plRVFBQUFBJCQAAAAAAAAAAAEAAACXS39dw7u07V-088nxvN21vQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJkii16ZIoteeE; H_PS_PSSID=1464_31124_21090_31187_30903_31271_31228_30823_31085_26350_31164_22159; sugstore=1; H_PS_645EC=6b05Ik9MKkAEZv4IFslxBo9KEklxQ1OO4z81AbF42RTzgtIiyvevJEQieyM; BDSVRTM=0; WWW_ST=1586850915148"
}
data = {
"wd":"新型冠状病毒"
}
url = "http://www.baidu.com/s"
re = requests.get(url,params=data,headers= headers)
print(re.url)
with open("index.html","w",encoding="utf-8") as f:
count = f.write(re.content.decode("utf-8"))
print(count)
打开刚刚写入的文件,和我们平时百度的一样
至于post方法以及使用requests库实现代理部分,我将在python爬虫之requests库(二)介绍
