spring boot 集成sleuth
git地址
https://github.com/a18792721831/studySpringCloud.git
1. 理论
1.1 sleuth是什么
sleuth是spring cloud的一个组件,主要的功能是在分布式系统中提供服务链路追踪的解决方案。
简单来讲,就是,展示微服务调用过程。
1.2 sleuth有哪些
常见的链路追踪组件有Google的Dapper,Twitter的Zipkin,以及阿里的Eagleeye
1.3 链路追踪的一些基本概念
-
- Span 基本工作单元,每次一个远程调度任务就会产生一个Span,Span是用一个64位ID唯一标识的。Span包含了摘要、时间戳标记、Span的ID以及进程ID.
-
- Trace: 有一系列的Span组成,呈现树状结构。在一个微服务请求中,每次一个新的调用都会产生一个Span,这些所有的Span组成了Trace.
-
- Annotation:用于记录一个事件,一些核心的注解用于定义一个请求的开始和结束:
- cs-Client Sent:客户端发送一个请求,这个注解描述了Span的开始。
- sr-Server Received:服务端获得请求并准备开始处理。sr-cs的时间差就是网络请求的时间。
- ss-Server Sent:服务端发送响应,该注解表明请求处理的完成(请求的结果开始返回客户端)ss-sr的时间差就是服务器处理请求的真正时间
- cr-Client Received:客户端接收响应,此时整个Span结束,cr-cs的时间差就是整个请求的时间。
1.4 zipkin的组成

zipkin由4部分组成:
- Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为 Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
- Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
- RESTful API:API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。
- Web UI:UI 组件,基于 API 组件实现的上层应用。通过 UI 组件用户可以方便而有直观地查询和分析跟踪信息。
2. zipkin 实例
2.1 zipkin server
这里有一个坑,现在好多书上或者资料上说怎么怎么搭建zipkin server工程。
但是你根据数据或者网上的步骤一步一步的完成,但是会出现各种各样的问题。
这是因为从19年左右开始,zipkin server已经被集成到jar包里面了,不需要再搭建了,只需要java -jar启动就可以了。
首先,zipkin server在搭建的时候都需要依赖zipkin-ui的,也就是说,我们搭建zipkin server只是为了展示数据。
那么,数据的展示是稳定的,不需要频繁的更改,所以zipkin就将zipkin server(依赖的了ui)打成jar包,下载后启动即可使用。
注意,jar包有jdk版本依赖。

latest传送门

下载完成后启动,会出现如下界面


访问9411端口,可以进入zipkin的界面

这个界面一般不会修改的,所以为了方便起见,将zipkin在服务器的docker上启动。

访问

2.2 zipkin client
zipkin server是负责将数据展示出去,而zipkin client则是收集数据,并将收集到的数据传给zipkin server,然后完成数据的收集与展示。
2.2.1 创建

2.2.2 配置

最上面配置eureka server的地址
中间是日志级别
然后指定服务名是zipkin-client-user-service
然后指定zipkin server的地址
最后的spring.sleuth.sampler.percentage是上传到zipkin server的信息的百分比
1.0 表示将所有的链路信息全部上传。
2.2.3 注解

2.2.4 对外接口 controller

2.2.5 启动
首先启动eureka server,然后启动zipkin client.

然后尝试请求zipkin client对外开放的接口

然后刷新zipkin server

我有一次地址写错了,所以这里是两条记录。
点击其中一个还可以进去

这个图怎么看?
1.系统的展示了微服务请求的时间以及微服务的深度和这次微服务调用的唯一标识traceID
2.表示这次微服务调用的入口以及请求方式restful
3.选择的请求的span id以及这个span的父亲。
4.这个事件
5.记录了微服务请求的结果以及来源信息。

对于事件还可以展示更多信息,记得我们在理论里面说事件有4个注解:cs、sr、ss、cr
上面只展示了sr、ss
我们再来看一个成功的

2.3 gateway service
上面我们看了1层深度的微服务的调用,我们之前了解过zuul,基于zuul实现微服务的转发,进而实现多层微服务的调用。
2.3.1 创建

2.3.2 配置

指定端口、eureka server的地址,日志级别,以及服务名称zipkin server的地址,上报比例以及zuul转发路由。
2.3.3 注解

2.3.4 启动

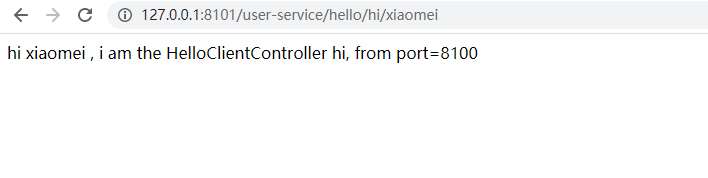
此时访问zipkin server

这个时候,搜索结果就有不一样了
1.表示微服务调用入口微服务
2.表示那些微服务参与,其顺序
点击进去查看详细信息

这是gateway-service的调用信息,可以看到这是调用入口微服务,因为其span的父亲是空的。

这是user-service的调用详细信息,也是gateway的下一级调用的服务。因为user-service的span的父亲是gateway的span.
而且这个事件的节点信息就与我们理论中的所有都有了。
当然,下面遮住的是user-service的返回信息。
当然,这是微服务请求调用其他微服务比较少的时间,如果调用的微服务比较多的时候,查看起来就非常的不方便了。幸好,zipkin server还可以以更加简单明了的方式查看微服务调用链路

而且这图还可以动,连接线上的小圆点会指明调用的方向的。
2.4 自定义链路数据
在了解zuul的时候,我们知道了zuul有4种filter
我们在2.3种的gateway-service中实现post过滤器
在过滤器中我们加入请求者信息(打印一些信息)

注意导入的tracer包是zipkin的包里的类。
我们通过之前看traceID和SpanID以及tag基本上就能知道其树状关系。
接下来重启访问

查看zipkin server



很奇怪,为什么没有我们的tag,难道没有走posty过滤器》?
我们在过滤器里面打印控制台输出

然后重试
但是还是没有打印我们想要的输出

仔细查看,重新梳理,发现是因为没有将过滤器注册到spring容器中
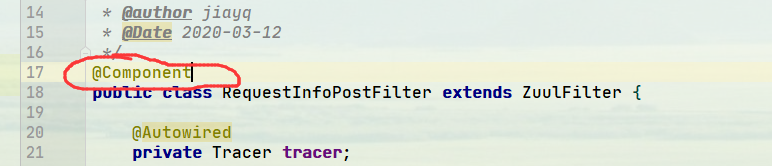
重试

打印了。
接下来看看zipkin server


与我们想象中的一样,至于访问不到主机名,然后异常的情况就不试了。
3. zipkin 集成 rabbitmq
在我们之前的实例中,zipkin client收集到信息是通过http将数据传输到zipkin server的,使用http请求传输数据比较性能差,所以zipkin 可以集成rabbitmq进行数据的传输。
3.1 rabbitmq的搭建
rabbitmq的搭建参考这里:
https://blog.csdn.net/a18792721831/article/details/104737243

所以我们是有rabbitmq的

3.2 zipkin server rabbitmq
我们可以通过环境变量让 Zipkin 从 RabbitMQ 中读取信息,就像这样:
RABBIT_ADDRESSES=localhost java -jar zipkin.jar
可配置的环境变量如下表所示:
| 属性 | 环境变量 | 描述 |
|---|---|---|
| zipkin.collector.rabbitmq.concurrency | RABBIT_CONCURRENCY | 并发消费者数量,默认为 1 |
| zipkin.collector.rabbitmq.connection-timeout | RABBIT_CONNECTION_TIMEOUT | 建立连接时的超时时间,默认为 60000 毫秒,即 1 分钟 |
| zipkin.collector.rabbitmq.queue | RABBIT_QUEUE | 从中获取 span 信息的队列,默认为 zipkin |
| zipkin.collector.rabbitmq.uri | RABBIT_URI | 符合 RabbitMQ URI 规范 的 URI,例如 amqp://user:pass@host:10000/vhost |
如果设置了 URI,则以下属性将被忽略。
| 属性 | 环境变量 | 描述 |
|---|---|---|
| zipkin.collector.rabbitmq.addresses | RABBIT_ADDRESSES | 用逗号分隔的 RabbitMQ 地址列表,例如 localhost:5672,localhost:5673 |
| zipkin.collector.rabbitmq.password | RABBIT_PASSWORD | 连接到 RabbitMQ 时使用的密码,默认为 guest |
| zipkin.collector.rabbitmq.username | RABBIT_USER | 连接到 RabbitMQ 时使用的用户名,默认为 guest |
| zipkin.collector.rabbitmq.virtual-host | RABBIT_VIRTUAL_HOST | 使用的 RabbitMQ virtual host,默认为 / |
| zipkin.collector.rabbitmq.use-ssl | RABBIT_USE_SSL | 设置为 true 则用 SSL 的方式与 RabbitMQ 建立链接 |
但是我们是使用docker启动的,所以需要使用-e实现指定环境变量
我们重新启动zipkinserver
我们之前启动的是简化版的,只能用于内存和elasticsearch存储。
如果要使用kafka或者rabbitmq,则需要启动完整版的。

docker run -d -p 9411:9411 -e "RABBIT_ADDRESSES=10.0.228.93:30672" --name=zipkin-server openzipkin/zipkin

3.3 zipkin client rabbitmq
3.3.1 创建

3.3.2 配置

我们注释掉了zipkin的base-url的配置
3.3.3 注解

3.3.4 启动
首先启动eureka server,然后启动zipkin-rabbitmq




4. zipkin 集成oracle
目前zipkin官方没有实现oracle的集成,只支持mysql,由于我本机没有安装mysql,所以这部分不做深入。
详细介绍见 https://github.com/openzipkin/brave/tree/master/instrumentation
不过,基于zipkin的实现原理,可以用其他方式实现对普遍数据库的支持,需要自己实现数据的存储于插入到span中。
详细实现见 Zipkin原理学习–日志追踪 MySQL 执行语句
5. zipkin集成 elasticsearch
5.1 安装 elasticsearch
我们需要在服务器上的docker环境下安装elasticsearch。

我们根据docker hub 上给出的教程,安装elasticsearch

使用的镜像如下:


访问验证

这里借用一张图片

很明白。
我们安装的是单机版,如果需要集群安装,参考这里
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/docker.html
5.2 安装 kibana
elasticsearch只是存储了数据,那么数据的展示是通过kibana展示的。
我们在docker hub上搜索elasticsearch时,kibana会一起展示,这两个基本上都是一块使用的。

安装过程也是一样的


访问验证

kibana启动比较慢
要做好多的操作才能成功启动

5.3 zipkin 使用 elasticsearch

基于此,我们需要重新创建一个docker 容器,之前创建的容器是基于rabbitmq的,现在重新创建一个基于elasticsearch的容器
docker run -d -p 9412:9411 -e "STORAGE_TYPE=elasticsearch" -e "ES_HOSTS=10.0.251.180:9200" --name=zipkin-elsearch openzipkin/zipkin

访问验证

5.5 zipkin client 使用 elasticsearch
5.5.1 创建
和普通的一样,直接创建。
我是这样理解,也不知道是否正确,大家当做参考就行。
- zipkin server集成了elasticsearch,当zipkin client 通过http或者mq将链路信息上传至zipkin server后,zipkin server会将信息存储到elasticsearch而不是内存中,此时,elasticsearch就拥有了zipkin client的链路信息。
- zipkin client通过http或者mq将链路信息上传到zipkin server.
- elasticsearch接收到zipkin server的信息后,存储到elasticsearch然后提供给其他组件进行使用
- kibana连接elasticsearch,并且根据定义的查询进行信息的展示。
这里有一个误区:
网上或者书上的许多资料,都是基于本地的zipkin server进行集成elasticsearch的。很容易给人一种错觉:zipkin client直接将链路信息上传给elasticsearch的。实际上,zipkin client也可以直接将链路信息上传给elasticsearch,只不过需要进行手动的上传。
而将信息上传给zipkin server,且指定zipkin server的存储方式后,这些就都不需要了,zipkin server会将这些都处理完成的。
(这一块花费了我大概4小时才意识到这个思想误区)
5.5.2 配置

5.5.3 注解

5.5.4 启动

5.5.5 验证

5.6 kibana 连接 elasticsearch


输入zipkin-*会显示匹配到一个index

选择第一个就行,根据名字来看是和时间有关的,具体没有研究。。。。




这里有一个比较坑的地方
点击展示面板可能不会展示上图,而是提示没有信息可以展示。(巨坑无比:因为展示的是默认的index,而不是我们需要的zipkin-*的index)


我们在请求一次,看看效果:



当然kibana还提供更强大的展示面板






还有统计个数的


随便定制。强大,还不太会用。。
