海量数据:数量非常大的数据
1、哈希切割top k问题:给一个超过100G大小的log file,log中储存着ip地址,设计算法找到出现次数最多的ip地址?
法一、取文件中的第一个ip地址,后遍历整个文件;然后统计下一个ip地址按找前面的方法继续执行,统计次数。
如果第一个ip地址比第二个ip地址多,则忽略第二个,继续比较直到比完所有的ip地址;但是这种方法的时间复杂度为O(n^2)
一个循环用于统计ip地址,一个循环用于比较影响最大的因素为:100G的文件不可能一次加载到内存,放在磁盘上,分段进行加载,必须读磁盘。一般的磁盘都为机械磁盘,加载时非常消耗时间。时间几乎全部消耗在读取磁盘操作上了,而不是方法上。
法二、将100G大小的文件,切分成1000分,统计没个文件中ip地址出现的次数,在比较出现次数最多的ip地址。从上往下顺序切割,但也会导致:不容易统计一个ip地址,同一个ip地址可能跨多个文件,还得遍历每一个小文件
法三、将100G大小的文件,切分成1000分,将相同的ip地址放在同一个文件中,用哈希桶的方式实现
1、哈希切割top k问题:给一个超过100G大小的log file,log中储存着ip地址,设计算法找到出现次数最多的ip地址?
法一、取文件中的第一个ip地址,后遍历整个文件;然后统计下一个ip地址按找前面的方法继续执行,统计次数。
如果第一个ip地址比第二个ip地址多,则忽略第二个,继续比较直到比完所有的ip地址;但是这种方法的时间复杂度为O(n^2)
一个循环用于统计ip地址,一个循环用于比较影响最大的因素为:100G的文件不可能一次加载到内存,放在磁盘上,分段进行加载,必须读磁盘。一般的磁盘都为机械磁盘,加载时非常消耗时间。时间几乎全部消耗在读取磁盘操作上了,而不是方法上。
法二、将100G大小的文件,切分成1000分,统计没个文件中ip地址出现的次数,在比较出现次数最多的ip地址。从上往下顺序切割,但也会导致:不容易统计一个ip地址,同一个ip地址可能跨多个文件,还得遍历每一个小文件
法三、将100G大小的文件,切分成1000分,将相同的ip地址放在同一个文件中,用哈希桶的方式实现
统计单个文件中的ip地址:借助哈希表:拿到一个哈希地址,查找是否在哈希表出现中,若是没有在哈希表中,则创建一个键值对,以此ip作为key,以出现的次数作为value,若出现过,则不用插入,直接将出现的次数加1。这种发法使效率达到O(1)
缺陷:为何划分为1000份,一般应划分为多少份?算出文件的个数,在此基础上将分数增加
与上题条件相同,如何找到topk的ip?如何直接用linux系统命令实现?
按照次数创建小堆,进行查找,用次数作为key,用ip地址作为value。先取k个ip地址,建立堆,在取ip往堆中插入。
依次处理知道ip地址全部被处理,这k条ip地址为出现次数最多的k条IP。
缺陷:为何划分为1000份,一般应划分为多少份?算出文件的个数,在此基础上将分数增加
与上题条件相同,如何找到topk的ip?如何直接用linux系统命令实现?
按照次数创建小堆,进行查找,用次数作为key,用ip地址作为value。先取k个ip地址,建立堆,在取ip往堆中插入。
依次处理知道ip地址全部被处理,这k条ip地址为出现次数最多的k条IP。

2、位图应用:给定100亿个整数,设计算法找到只出现一次的整数。给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件的交集?
3、位图变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
答:
法一:两个位图,一个位图中找到此数据,置为1,另一个同理。若是只有一个位图中为1,则没有交集,若两个位图中都为1,则有交集。
法二:遍历
法三:两个比特位表示(表示四种状态):00表示不存在;01表示只出现了一次;10表示一个数据出现了多次
采用法三:100亿个整数用2个比特位表示,需要1G空间
法四:按照数据的比特位进行划分,直到该数据只剩下一个比特位;检查还剩下几个数据,若只剩下一个数据则只出现一次,否则出现多次
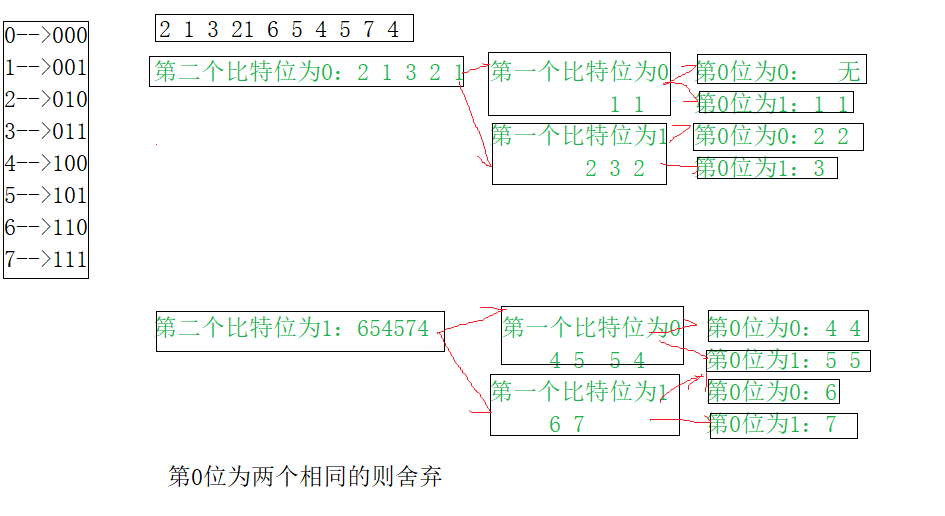
4、有40亿个整型数据,快速确认某个数据是否在集合中
答:4*4000000000(字节)=4*4000000000/1024(k)=(4*4000000000/1024(k))/1024(M)=(4*4000000000/1024(k))/1024)/1024(G)~=16G。。int有42亿多比特,用0,1两个比特位表示在与不在的两种状态
答:4*4000000000(字节)=4*4000000000/1024(k)=(4*4000000000/1024(k))/1024(M)=(4*4000000000/1024(k))/1024)/1024(G)~=16G。。int有42亿多比特,用0,1两个比特位表示在与不在的两种状态

位图的操作
.h
.h
# pragma once
# include<stdio.h>
# include<string.h>
# include<stdlib.h>
# include<assert.h>
# include<malloc.h>
typedef struct BitMap
{
int *_bitset;//位的集合,整型空进的比特位32位
int _capacity;//空间容量有多少个整型空间
int _size;//有效比特位的个数
}BitMap;
//初始化
void BitMapInit(BitMap *bmp, int totalBit);
//比特位置1
void BitMapSet(BitMap *bmp, int pos);
//置0
void BitMapReSet(BitMap *bmp, int pos);
//检验bitMap中为1还是0
int BitMapTest(BitMap *bmp, int pos);
//bitmap中总共有多少比特位
int BitMapSize(BitMap *bmp);
//位图中有多少比特位为1
int BitMapCount(BitMap *bmp);
//销毁位图(因为为动态的)
void BitMapDestroy(BitMap *bmp, int pos);
.c
# define _CRT_SECURE_NO_WARNINGS 1
# include"bulong.h"
//初始化
//除以32后向下取整,如:24/32=0不正确,加上1即可
void BitMapInit(BitMap *bmp, int totalBit)
{
assert(bmp);
//计算容量空间
bmp->_capacity = (totalBit >> 5) + 1;
bmp->_bitset = (int *)calloc(bmp->_capacity, sizeof(int));
if (NULL == bmp->_bitset)
{
assert(0);
return;
}
bmp->_size = totalBit;
}
//将位图which位置的比特位置1
void BitMapSet(BitMap *bmp, int which)
{
//0110 1001
//0000 0100
//0110 1101
int index = (which >> 5);//在那个字节
int pos = which % 32;//在那个位置
if (which > bmp->_size)//不能超过有效位
return;
bmp->_bitset[index] |= (1 << pos);
}
//置0
void BitMapReSet(BitMap *bmp, int which)
{
int index = (which >> 5);
int pos = which % 32;
if (which > bmp->_size)//不能超过有效位
return;
bmp->_bitset[index] &= ~(1 << pos);
}
//检验bitMap中为1还是0
int BitMapTest(BitMap *bmp, int which)
{
int index = (which >> 5);
int pos = which % 32;
if (which > bmp->_size)//不能超过有效位
return;
return bmp->_bitset[index] & (1 << pos);
}
//bitmap中总共有但是比特位
int BitMapSize(BitMap *bmp, int pos)
{
return bmp->_size;
}

//位图中有多少比特位为1
int BitMapCount(BitMap *bmp)
{
int i = 0;
int count = 0;//统计为1的个数
const char *bitCount = "\0\1\1\2\1\2\2\3\1\2\2\3\2\3\3\4";
for (; i < bmp->_capacity; ++i)//capacity表示有多少整型
{
int value = bmp->_bitset[i];
int j = 0;
while (j < sizeof(bmp->_bitset[0]))//循环四次,int有4个字节
{
char c = value;
count+=bitCount[c & 0x0f];//一个字节的高四位清0
c >>= 4;
bitCount[c & 0x0f];//计算高四位
value += 8;//计算下一个字节
++j;
}
}
return count;
}
//销毁位图(因为为动态的)
void BitMapDestroy(BitMap *bmp, int pos)
{
if (bmp->_bitset)
{
free(bmp->_bitset);
bmp->_capacity = 0;
bmp->_size = 0;
}
}
test.c
# include"bulong.h"
void TestBitMap()
{
int i = 0;
BitMap bmp;
int arr[] = { 1, 3, 7, 4, 12, 16, 19,13, 22, 18 };
BitMapInit(&bmp, 24);
for (; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
BitMapSet(&bmp, arr[i]);
}
printf("位图中总的比特个数:%d\n", BitMapSize(&bmp));
printf("位图中比特位为1的个数:%d\n", BitMapCount(&bmp));
if (BitMapTest(&bmp, 16))
printf("位图中第%d个比特位是1\n", 16);
else
printf("位图中第%d个比特位是0\n", 16);
if (BitMapTest(&bmp, 16))
printf("位图中第%d个比特位是1\n", 17);
else
printf("位图中第%d个比特位是0\n", 17);
BitMapReSet(&bmp, 16);
if (BitMapTest(&bmp, 16))
printf("位图中第%d个比特位是1\n", 16);
else
printf("位图中第%d个比特位是0\n", 16);
}
int main()
{
TestBitMap();
system("pause");
return 0;
}
结果:

5、布隆过滤器:给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
5、布隆过滤器:给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
查询记录可能为字符串,如若按照位图的方式,需要先转换为整型数字,将整型数字放入位图中但是同时有可能两条记录转为同一个整型数字,产生错误。
精确算法:找出的交集不允许出错;近似算法:找出的交集大概相同就可以,不必完全精确。
查找文件
法一:取一个文件为查找文件,在另一个文件里取一个记录进行查找:效率低(进行大量查找,而且要操纵大量的磁盘)
法二:通过哈希切割的方式,topk:把第一个文件切割成1000个小文件,把发生哈希冲突的放进同一个文件里去。在当前切割的文件中查找另一个文件的内容,拿一条记录到可能出现的文件中查找两个文件的大小都为100G,将文件一进行切割,切割为1000份(通过哈希的方式),计算将文件二中的记录应存放在文件一的哪一个小文件处。效率高,且不会产生误差,但是还是有点慢。不如位图快
法三:位图的方法:一条记录对应多个比特位,先把一个文件里面的数据映射到位图上(在文件一中取出一条记录,通过多个哈希函数计算出位置,把这多个位置置一);然后将第二个文件中的数据,通过这多个哈希函数计算,并且置一。通过这种方式将文件中所有的位图放到文件中去。找两个文件的交集:在第二个文件里取出一条记录,在位图中查找(通过这多个哈希函数计出几个位置,若这几个位置全部都为1,说明这条记录为交集。如果,这几个位置有任一个
记录不为一,则这条记录不是交集。),查询结束后,即可判断哪些记录存在交集。哈希函数越多,精确度越高。
缺陷:若第二条记录中计算出的比特位为
精确算法:找出的交集不允许出错;近似算法:找出的交集大概相同就可以,不必完全精确。
查找文件
法一:取一个文件为查找文件,在另一个文件里取一个记录进行查找:效率低(进行大量查找,而且要操纵大量的磁盘)
法二:通过哈希切割的方式,topk:把第一个文件切割成1000个小文件,把发生哈希冲突的放进同一个文件里去。在当前切割的文件中查找另一个文件的内容,拿一条记录到可能出现的文件中查找两个文件的大小都为100G,将文件一进行切割,切割为1000份(通过哈希的方式),计算将文件二中的记录应存放在文件一的哪一个小文件处。效率高,且不会产生误差,但是还是有点慢。不如位图快
法三:位图的方法:一条记录对应多个比特位,先把一个文件里面的数据映射到位图上(在文件一中取出一条记录,通过多个哈希函数计算出位置,把这多个位置置一);然后将第二个文件中的数据,通过这多个哈希函数计算,并且置一。通过这种方式将文件中所有的位图放到文件中去。找两个文件的交集:在第二个文件里取出一条记录,在位图中查找(通过这多个哈希函数计出几个位置,若这几个位置全部都为1,说明这条记录为交集。如果,这几个位置有任一个
记录不为一,则这条记录不是交集。),查询结束后,即可判断哪些记录存在交集。哈希函数越多,精确度越高。
缺陷:若第二条记录中计算出的比特位为

布隆过滤器,若是说这个数据都满足这几个哈希函数,则不一定存在;若是说不满足,则一定不存在
函数实现::
.h
//搭载位图实现
//包含位图的头文件
# pragma once
# include"BitMap.h"
# include"common.h"
# include<stdio.h>
# include<stdlib.h>
# include<assert.h>
typedef char* DataType;
//函数指针数组
typedef size_t (*pStrToInt)(const char *str);
typedef struct BloomFilter
{
BitMap _bmp;//给定位图
int _size;//位图中放多少元素
pStrToInt _pSTInt[5];//需要传类型名
}BloomFilter;
//初始化
//pStrToInt *STInt等同于(pStrToInt STInt1,pStrToInt STInt2,pStrToInt STInt3,pStrToInt STInt4,pStrToInt STInt5)
void BloomFilterInit(BloomFilter *bf, int size, pStrToInt *STInt);//capacity:表示放的元素
//插入
void BloomFilterInsert(BloomFilter *bf, char *str);
//判断某一个数据在不在布隆过滤器上面
int IsIn(BloomFilter *bf, char *data);
//表格中有多少元素
int BloomFilterSize(BloomFilter *bf);.c
#include"bulongFilter.h"
void BloomFilterInit(BloomFilter *bf, int size, pStrToInt *STInt)//capacity:表示放的元素
{
int i = 0;
assert(bf);
//初始化位图
BitMapInit(&bf->_bmp, size * 5);//size*5:总的比特位,因为我们给定5个哈希函数
bf->_size = 0;
for (; i < sizeof(bf->_pSTInt) / sizeof(bf->_pSTInt[0]); ++i)
//把地址传过来
bf->_pSTInt[i] = STInt[i];
}
void BloomFilterInsert(BloomFilter *bf, char *str)
{
//把那个比特位置一,计算哈希地址
int hashAddr1, hashAddr2, hashAddr3, hashAddr4, hashAddr5;
//位图中总的个数
int totalBits = bf->_bmp._size;
//给哈希地址处的比特位置1(5个哈希函数)
hashAddr1 = bf->_pSTInt[0](str) % totalBits;
BitMapSet(&bf->_bmp, hashAddr1);
hashAddr2 = bf->_pSTInt[1](str) % totalBits;
BitMapSet(&bf->_bmp, hashAddr2);
hashAddr3 = bf->_pSTInt[2](str) % totalBits;
BitMapSet(&bf->_bmp, hashAddr3);
hashAddr4 = bf->_pSTInt[3](str) % totalBits;
BitMapSet(&bf->_bmp, hashAddr4);
hashAddr5 = bf->_pSTInt[4](str) % totalBits;
BitMapSet(&bf->_bmp, hashAddr5);
//给定哈希函数,一个占5个比特位
//字符串需要转换成整型元素
bf->_size++;
}
int IsIn(BloomFilter *bf, char *data)
{
int hashAddr1, hashAddr2, hashAddr3, hashAddr4, hashAddr5;
int totalBits = bf->_bmp._size;
hashAddr1 = bf->_pSTInt[0](data) % totalBits;
if (0 == BitMapTest(&bf->_bmp, hashAddr1))//第一个哈希函数不在,那么后面的都不在
return 0;
hashAddr2 = bf->_pSTInt[1](data) % totalBits;
if (0 == BitMapTest(&bf->_bmp, hashAddr2))//第二个哈希函数不在,那么后面的都不在
return 0;
hashAddr3 = bf->_pSTInt[2](data) % totalBits;
if (0 == BitMapTest(&bf->_bmp, hashAddr3))//第三个哈希函数不在,那么后面的都不在
return 0;
hashAddr4 = bf->_pSTInt[3](data) % totalBits;
if (0 == BitMapTest(&bf->_bmp, hashAddr4))//第四个哈希函数不在,那么后面的都不在
return 0;
hashAddr5 = bf->_pSTInt[4](data) % totalBits;
if (0 == BitMapTest(&bf->_bmp, hashAddr5))//第五个哈希函数不在,那么后面的都不在
return 0;
return 1;
}
int BloomFilterSize(BloomFilter *bf)
{
assert(bf);
return bf->_size;
}
common.h
# pragma once typedef unsigned int size_t;//# include<stddef.h> size_t GetNextPrime(size_t capacity); //把元素转换为整型数据,默认方法(整型数据不需要转换,直接返回) size_t ElemToIntDef(int data); ////字符串转换为整型 size_t ElemToInt(const char * str); //给5个哈希函数,字符串转换为整型 size_t StrToInt1(const char *str); size_t StrToInt2(const char *str); size_t StrToInt3(const char *str); size_t StrToInt4(const char *str); size_t StrToInt5(const char *str);
common.c
//闭散列用的少,因为浪费空间
# define _CRT_SECURE_NO_WARNINGS 1
# include"Common.h"
#define _PrimeSize 28//enum{_PrimeSize =28};
// 使用素数表对齐做哈希表的容量,降低哈希冲突
const unsigned long _PrimeList[_PrimeSize] =
{//可将long换为long long获取更大的素数
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457u,
1610612711ul, 3221225473ul, 4294967291ul
};
//获取比容量大的第一个素数
size_t GetNextPrime(size_t capacity)
{
int i = 0;
for (; i < _PrimeSize; ++i)
{
if (_PrimeList[i]>capacity)//容量小于素数,直接返回该素数
return _PrimeList[i];
}
return _PrimeList[_PrimeSize - 1];//容量太大了,返回最后一个素数
}
size_t ElemToIntDef(int data)
{
return data;
}
unsigned int StrToInt(const char * str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
size_t StrToInt1(const char *str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
size_t StrToInt2(const char *str)
{
}
size_t StrToInt3(const char *str);
size_t StrToInt4(const char *str);
size_t StrToInt5(const char *str);
test.c
# include"bulongFilter.h"
void TestBloomFilter()
{
BloomFilter bf;
pStrToInt STInt[] = { StrToInt1, StrToInt2, StrToInt3, StrToInt4, StrToInt5};
BloomFilterInit(&bf, 100, STInt);
BloomFilterInsert(&bf, "会话");
BloomFilterInsert(&bf, "羊毛");
BloomFilterInsert(&bf, "总付");
BloomFilterInsert(&bf, "空");
BloomFilterInsert(&bf, "调度");
pintf("size=%d\n", BloomFilterSize(&bf));
if (IsIn(&bf, "会话"))
printf("在\n");
else
printf("不在\n");
if (IsIn(&bf, "不可"))
printf("在\n");
else
printf("不在\n");
}
int main()
{
TestBloomFilter();
system("pause");
return 0;
}
//缺点:1、多个哈希,有的比特位可能出现重叠,这样就会导致不准确,所以只能找出近似的结果,原理同上,方法三
// 2、得到最终结果,不能保证其准确性
// 3、将一个哈希文件删除,将比特位置为0。一条查询不一定能查询到,所以布隆过滤器不支持删除。
//好处:可能会告诉你,是否在表格上,但是不能确切的说是在哪一个位置。查询效果为O(1),效率高需要引用上面位图的实现的头文件,就不在冗余介绍了,直接翻看上面的部分即可。
缺点:1、多个哈希,有的比特位可能出现重叠,这样就会导致不准确,所以只能找出近似的结果,原理同上,方法三
2、得到最终结果,不能保证其准确性
3、将一个哈希文件删除,将比特位置为0。一条查询不一定能查询到,所以布隆过滤器不支持删除。
好处:可能会告诉你,是否在表格上,但是不能确切的说是在哪一个位置。查询效果为O(1),效率高
3、将一个哈希文件删除,将比特位置为0。一条查询不一定能查询到,所以布隆过滤器不支持删除。
好处:可能会告诉你,是否在表格上,但是不能确切的说是在哪一个位置。查询效果为O(1),效率高
如何扩展BloomFilter使得它支持删除元素的操作
如何扩展BloomFilter使得它支持计数操作
将用这个比特位的记录的个数统计起来,删除记录后,个数减一(但是使用计数的方法不能使用位图,位图只有一个比特位,应将位图换为数组。数组的每一个位置给定一个整型元素,计算位置,后直接减一,插入时,计算位置,后直接加一。
6、倒排索引:给上千个文件,每个文件大小为1K—100M。给n个词,设计算法对每个词找到所有包含它的文件,你只有100k内存