Java中的集合(五)继承Collection的List接口
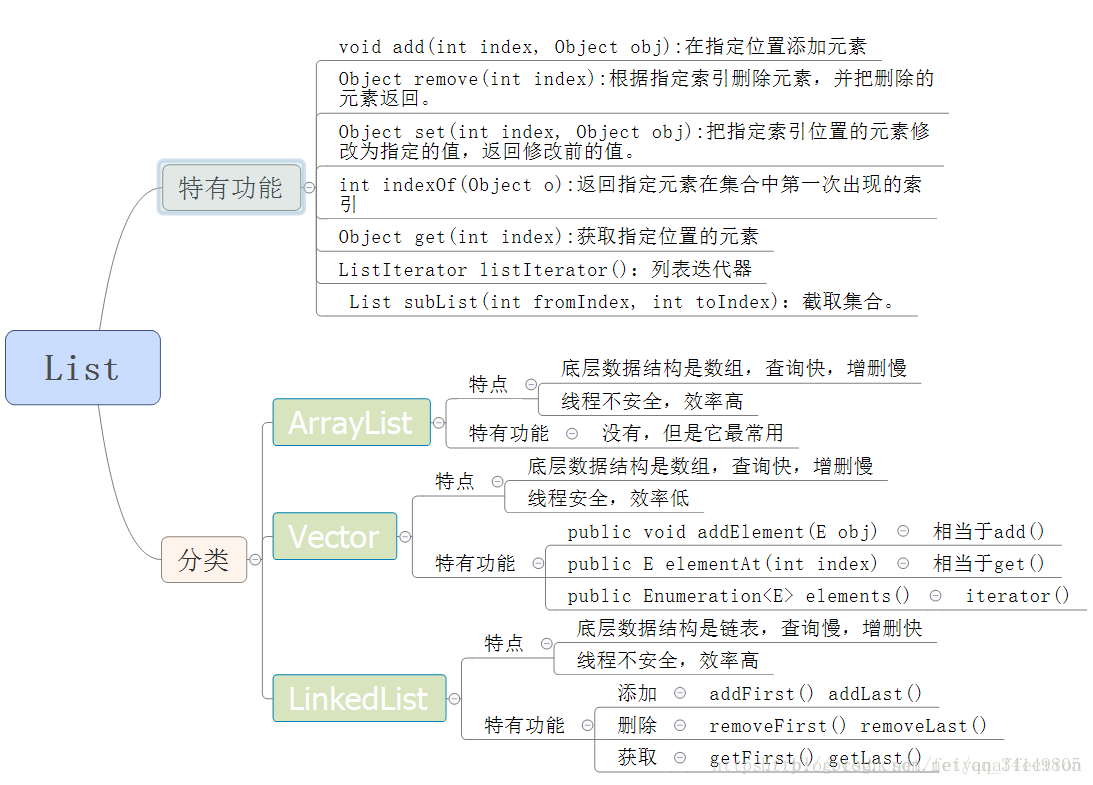
一、List接口简介
List是有序的Collection的,此接口能够精确的控制每个元素插入的位置。用户能够根据索引(元素在List接口的中位置)访问List中的元素,类似于Java中的数组。
List接口有如下特点:
-
- 有序的集合。存储顺序和获取元素的顺序都是一致的;
- 可重复。允许存储重复的元素;
- 提供索引。提供一些索引的方法,供用户操作。
二、List类图结构

通过上面类图可用看出,List接口下有4个实现类,分别为:LinkedList、ArrayList、Vector和Stack。

三、List接口中带索引的方法(特有):

需要注意的是:操作索引时,一定要注意防止索引越界异常提示。
- IndexOutOfBoundsException:索引越界异常,集合会报;
- ArrayIndexOutOfBoundsException:数组索引越界异常;
- StringIndexOutOfBoundsException:字符串索引越界异常。
四、ArrayList
(一)、简介、继承结构
ArrayList是List接口的实现类,也是最常用的集合类。底层数据结构是一个可变的动态数组,它允许任何符合规则的元素插入(包括null)。每一个ArrayList都有一个初始容量(10),该容量代表了数组的大小。随着容器中的元素不断增加,容器的大小也会随着增加。在每次向容器中增加元素的同时都会进行容量检查,当快溢出时,就会进行扩容操作。
如果我们明确所插入元素的多少,最好指定一个初始容量值,避免过多的进行扩容操作而浪费时间、效率。
1、ArrayList继承结构

通过结构图可以看出,ArrayList继承自AbstractList,实现了List, RandomAccess, Cloneable, java.io.Serializable这些接口。
-
- 继承AbstractList,实现了List接口:它是一个动态数组,提供了相关添加,删除,修改和遍历等功能;
- 实现RandomAccess接口:提供随机访问的能力;RandmoAccess是Java中用来被List接口实现,为List提供快速访问功能的。在ArrayList中,可以通过元素的序号快速获取元素对象,这就是快速随机访问。
- 实现Cloneable接口:覆盖函数clone(),可以被克隆;
- 实现Serializable接口:支持序列化和反序列化,可以通过序列化传输数据。
2、ArrayList的特性:
- 增删慢,查询快(底层数据结构是数组);
- 效率高,线程不安全的(非同步);
- 擅长随机访问(实现了RandomAccess接口);
(二)、ArrayList构造方法

(三)、ArrayList的两个重要的属性:elementData 和 size
1、elementData:Object[]的数组,保存了添加到ArrayList中的元素。
- 通过ArrayList()初始化ArrayList时,elementData的大小为默认值10,即Object[10];
- 通过ArrayList(int initialCapacity)初始化ArrayList时,elementData的大小为指定值initialCapacity,即Object[initialCapacity];
- ArrayList(Collection<? extends E> c)初始化ArrayList时,elementData的大小为参数集合的大小,即Object[c.length];
2、size:动态数组的实际大小
(四)、ArrayList的遍历方式
1、Iterator迭代器遍历方式
ArrayList类中封装了Iterator接口,调用Iterator()方法获得Iterator对象,Iterator对象调用hashNext()、next()方法进行迭代遍历。


1 Integer value = null; 2 Iterator iter = list.iterator(); 3 while (iter.hasNext()) { 4 value = (Integer)iter.next(); 5 }
2、随机访问。通过索引值遍历
由于ArrayList实现了RandomAccess接口,它支持通过索引值去随机访问元素,通过调用public E get(int index)方法遍历。
1 Integer value = null; 2 for (int i=0; i<list.size(); i++) { 3 value = (Integer)list.get(i); 4 }
3、for-each循环遍历
1 Integer value = null; 2 for (Integer integ : list) { 3 value = integ; 4 }
4、三种遍历方式的性能
遍历ArrayList时,在性能方面:随机访问,通过索引值遍历> for-each遍历 > Iterator迭代器遍历。
(五)、使用toArray()异常
ArrayList提供了两个“toArray“方法,分别是: Object[] toArray() 和 <T> T[] toArray(T[] contents) 。
当我们调用“toArray()”方法时会抛““java.lang.ClassCastException”异常,但是调用"toArray(T[] t)"可以返回正常的T[]。
调用“toArray()”方法时会抛“java.lang.ClassCastException”异常是因为返回值类型是“Object[]”,Object是Java中最顶层的对象,且Java不支持对象向下转型,比如当Object[]转成Integer[]时,就会抛“java.lang.ClassCastException”异常。
使用另一个<T> T[] toArray(T[] contents)可以解决该异常问题。
调用 toArray(T[] contents) 返回T[]的可以通过以下几种方式实现。
1 // toArray(T[] contents)调用方式一 2 public static Integer[] vectorToArray1(ArrayList<Integer> v) { 3 Integer[] newText = new Integer[v.size()]; 4 v.toArray(newText); 5 return newText; 6 } 7 8 // toArray(T[] contents)调用方式二。最常用! 9 public static Integer[] vectorToArray2(ArrayList<Integer> v) { 10 Integer[] newText = (Integer[])v.toArray(new Integer[0]); 11 return newText; 12 } 13 14 // toArray(T[] contents)调用方式三 15 public static Integer[] vectorToArray3(ArrayList<Integer> v) { 16 Integer[] newText = new Integer[v.size()]; 17 Integer[] newStrings = (Integer[])v.toArray(newText); 18 return newStrings; 19 }
(六)、总结
1、ArrayList是基于动态数组的集合,当使用默认构造方法ArrayList()时,则ArrayList的默认容量大小是10;
2、当ArrayList容量不足时,ArrayList会动态扩容大小:新的容量 = (原始容量 * 3 / 2) + 1;
3、ArrayList的克隆复制是将全部元素克隆至新的数组中;
4、ArrayList实现了Serializable接口,当写入输出流时,先写入“容量”,再依次写入“每一个节点的值”,当读取输入流时,先读取“容量”,再依次读取“每个节点的元素”;
五、Vector
(一)、简介
Vector同ArrayList类似,底层数据结构是数组,特性即功能与ArrayList类似,也具有增删慢,查询快的特点,不同的是,Vector是同步的,线程安全的,所以在多线程环境下,使用Vector比ArrayList更合适。
Vector的特性:
-
- 增删慢,查询快;
- 效率低,线程安全(与ArrayList相反);
- 擅长随机访问,通过索引值遍历;
(二)、Vector构造方法

(三)、Vector的三个重要的属性:elementData , elementCount, capacityIncrement
elementData的特性与ArrayList中的elementData一致,这里不再赘述,这里主要讲一下elementCount和capacityIncrement。
1、elementCount:动态数组的大小,同ArrayList的size
2、capacityIncrement:扩容数组大小的增长系数。
在创建Vector时如指定了capacityIncrement的系数,则在Vector需要扩容时,扩容的大小总是capacityIncrement的系数大小。
(四)、Vector的遍历方式
Vector一共有4种遍历方式:Iterator迭代器遍历、通过索引值的随机方法、for-each遍历和Enumeration遍历。
Iterator迭代器遍历、通过索引值的随机方法、for-each遍历和ArrayList类似不再赘述,这里讲一下Enumeration遍历。
1、Enumeration遍历
1 Integer value = null; 2 Enumeration enu = vector.elements(); 3 while (enu.hasMoreElements()) { 4 value = (Integer)enu.nextElement(); 5 }
2、4种遍历方式的性能
遍历Vector时,在性能方面:随机访问,通过索引值遍历 > for-each遍历 > Enumeration遍历 > Iterator迭代器遍历
所以,无论是ArrayList还是Vector遍历,推荐使用随机访问,通过索引值遍历 。
(五)、ArrayList与Vector的区别
1、线程安全。ArrayList是线程不安全的,Vector是线程安全的;
2、扩容不同。ArrayList默认扩容是(原始容量 * 3 / 2) + 1,Vector默认扩容是原始容量 * 2;
3、遍历方式不同,ArrayList有3种,Vector有4种,多的一种是Enumeration遍历;
(六)、总结
1、Vector实际上是通过一个数组去保存数据的。当我们构造Vecotr时;若使用默认构造函数,则Vector的默认容量大小是10。
2、 当Vector容量不足以容纳全部元素时,Vector的容量会增加。若容量增加系数 >0,则将容量的值增加“容量增加系数”;否则,将容量大小增加一倍。
3、 Vector的克隆函数,即是将全部元素克隆到一个数组中;
4、Vector默认扩容是原始容量 * 2;
六、LinkedList
(一)、简介及继承结构
1、简介
LinkedList是List接口的另一种实现方式,底层数据结构是链表,具有增删快,查询慢的特性。自定义了操作头部和尾部元素的方法,可以当做“栈”使用,同时又是Deque的实现类,所以有具有双端队列的特性。所以LinkedList既可以当做“栈”,也可以当做双端队列。
LinkedList的特性:
- 元素增删快,查询慢(基于链表的数据结构);
- 效率高,线程不安全(非同步);
- 既可以当作“栈”使用,又可以当作队列使用。
2、继承结构
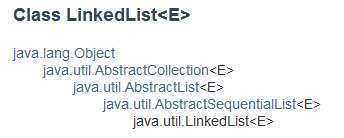
通过结构图可以看出,ArrayList继承自AbstractList,实现了List, RandomAccess, Cloneable, java.io.Serializable、Deque这些接口。
-
-
- 继承AbstractList,实现了List接口:它是一个动态链表,提供了相关添加,删除,修改和遍历等功能;
- 实现RandomAccess接口:提供随机访问的能力;
- 实现Cloneable接口:覆盖函数clone(),可以被克隆;
- 实现Serializable接口:支持序列化和反序列化,可以通过序列化传输数据。
-
(二)、LinkedList的构造方法

(三)、LinkedList三个重要属性:size,first、last
1、size:双向链表节点的个数;
2、first:双向链表的头部节点;
3、last:双向链表的尾部节点。
1 transient Node<E> first; 2 3 transient Node<E> last; 4 5 private static class Node<E> { 6 E item; 7 Node<E> next; 8 Node<E> prev; 9 10 Node(Node<E> prev, E element, Node<E> next) { 11 this.item = element; 12 this.next = next; 13 this.prev = prev; 14 } 15 }
从部分源码中可以看出,first和last是Node的实体实例,Node是LinkedList内部的私有静态类,Node定义了三个变量:item、next和prev。
- item:保存当前节点的值;
- next:指向下一个节点的值;
- prev:指向上一个节点的值;
(四)、LinkedList的遍历方式
LinkedList支持多种遍历方式。建议不要采用随机访问的方式去遍历LinkedList,而采用逐个遍历的方式。
1、Iterator迭代器遍历
Integer integer = null; Iterator iterator = list.iterator(); while(iterator.hasNext()){ integer = (Integer) iterator.next(); }
2、快速随机访问遍历
1 Integer integer = null; 2 3 for (int i=0; i<list.size(); i++) { 4 integer = (Integer) list.get(i); 5 }
3、for-each方式遍历
1 Integer integer = null; 2 3 for (Object object : list) { 4 integer = (Integer) object; 5 }
4、pollFirst()遍历
while(list.pollFirst() != null) {}
5、pollLast()遍历
while(list.pollLast() != null) {}
6、removeFirst()遍历
while(list.removeFirst() != null) {}
7、removeLast()遍历
while(list.removeLast() != null) {}
8、遍历方式的性能
遍历LinkedList时,removeFirst()和removeLast()效率最高,但是使用这两种方式会在遍历时删除数据。如果只想单独读取数据,不删除数据,推荐使用for-each方式遍历。
(五)、LinkedList常用方法
1、add(E e)和 add(int index, E element)
add(E e)的添加方式:
1 // 添加元素,以添加最后一个元素为例 2 public boolean add(E e) { 3 linkLast(e); 4 return true; 5 } 6 7 void linkLast(E e) { 8 final Node<E> l = last; 9 final Node<E> newNode = new Node<>(l, e, null); 10 last = newNode; 11 if (l == null) 12 first = newNode; 13 else 14 l.next = newNode; 15 size++; 16 modCount++; 17 }
情况1:假设LinkedList集合为空的情况,看如下图解:

情况2:假设LinkedList集合不为空,看如下图解:

如果LinkedList不为空,那么添加进来的元素2就是last,元素2的prev指向以前的最后一个元素,即元素1,元素2的next为null;
注意:如果只在头部或尾部添加元素,可以直接调用addFirst(E e)或addLast(E e);
add(int index,E element)添加方式:
1 //在指定位置添加一个元素 2 public void add(int index, E element) { 3 checkPositionIndex(index); 4 if (index == size) 5 linkLast(element); 6 else 7 linkBefore(element, node(index)); 8 } 9 10 private void checkPositionIndex(int index) { 11 if (!isPositionIndex(index)) 12 throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); 13 } 14 15 private boolean isPositionIndex(int index) { 16 return index >= 0 && index <= size; 17 } 18 19 void linkBefore(E e, Node<E> succ) { 20 // assert succ != null; 21 final Node<E> pred = succ.prev; 22 final Node<E> newNode = new Node<>(pred, e, succ); 23 succ.prev = newNode; 24 if (pred == null) 25 first = newNode; 26 else 27 pred.next = newNode; 28 size++; 29 modCount++; 30 }
从代码中看到和add(E e)的代码实现没有本质区别,都是通过新建一个Node实体,同时指定其prev和next来实现,不同点在于需要调用node(int index)通过传入的index来定位到要插入的位置,这个也是比较耗时的。
如下图解:

LinkedList插入效率高是相对的,因为它省去了ArrayList插入数据可能的数组扩容和数据元素移动时所造成的开销,但数据扩容和数据元素移动却并不是时时刻刻都在发生的。
2、remove(Object o) 和 remove(int index)
//删除某个对象 public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } //删除某个位置的元素 public E remove(int index) { checkElementIndex(index); return unlink(node(index)); } //删除某节点,并将该节点的上一个节点(如果有)和下一个节点(如果有)关联起来 E unlink(Node<E> x) { final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; }
先找到要删除的节点,remove(Object o)方法遍历整个集合,通过 == 或 equals方法进行判断;remove(int index)通过node(index)方法。
(六)、LinkedList与ArrayList的区别
1、底层数据结构不同。ArrayList底层数据结构是数组。LinkedList底层数据结构是链表;
2、性能不同。ArrayList增删慢,查询快。LinkedLIst增删快,查询慢(底层数据结构不同);
3、内存不同。LinkedList比ArrayList更占内存(因为LinkedList每个节点存储两个引用,一个指向前元素,一个指向后元素)。
(七)、总结
1、LinkedList是基于链表结构的集合。内部定义了一个私有的Node实体实例,Node是双向链表节点对应数据的数据结构,其定义了三个属性:item(保存该节点的值)、prev(指向前一个元素的节点)、next(指向后一个元素的节点);
2、LinkedList不存在容量不足的问题;
3、LinkedList克隆时,是将全部元素克隆到新的LinkedLIst对象中;
4、LinkedList实现了Serializable接口,当写入输出流时,先写入“容量”,再依次写入“每一个节点的值”,当读取输入流时,先读取“容量”,再依次读取“每个节点的元素”;
5、LinkedList实现了Deque,而Deque接口定义了在双端队列两端访问元素的方法,提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false)。
七、Stack
(一)、简介及继承结构
1、Stack是继承自Vector,所以它的底层数据结构也是动态数组。实现了一个“先进后出(FILO, First In Last Out)”的栈结构。
2、Stack的继承结构

由于继承了Vector,所以具有了Vector的相关特性,这里不再赘述。
(二)、Stack的构造方法
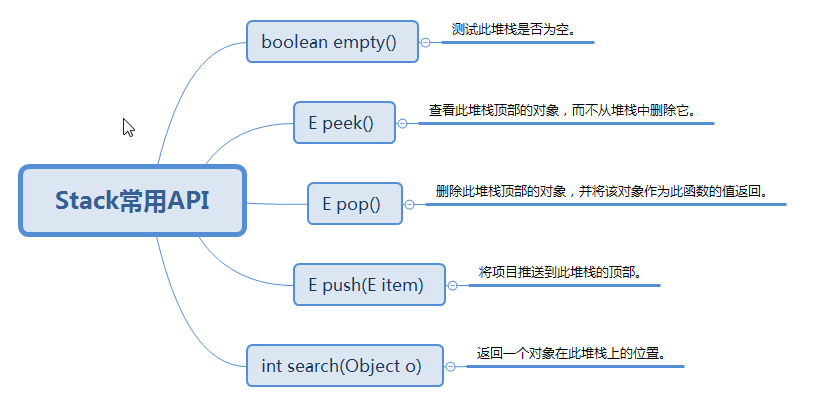
(三)、常用的API方法
(四)、总结
1、Stack实际上也是通过数组去实现的。
执行push时(即,将元素推入栈中),是通过将元素追加的数组的末尾中。
执行peek时(即,取出栈顶元素,不执行删除),是返回数组末尾的元素。
执行pop时(即,取出栈顶元素,并将该元素从栈中删除),是取出数组末尾的元素,然后将该元素从数组中删除。
2、Stack继承于Vector,意味着Vector拥有的属性和功能,Stack都拥有。
八、List与实现类的扩展