一、CDH搭建
1.CM数据库初始化报错:
/opt/cm-5.13.1/share/cmf/schema/scm_prepare_database.sh mysql cm -hnode01 -uroot -pMysql#123 --scm-host node168 scm scm scm
错误一:
java.sql.SQLException: Access denied for user ‘root’@‘localhost’ (using password: YES)
在/etc/hosts 文件中,加上
127.0.0.1 localhost.node168
错误二:cm库已存在
Drop database cm
**错误三:**ERROR Exception when creating/dropping database with user ‘root’ and jdbc url ‘jdbc:mysql://node01/?useUnicode=true&characterEncoding=UTF-8’
重新授权:
grant all privileges on *.* to 'root'@'localhost' identified by 'Mysql#123' with grant option;
grant all privileges on *.* to 'root'@'node01' identified by 'Mysql#123' with grant option;
grant all privileges on *.* to 'root'@'127.0.0.1' identified by 'Mysql#123' with grant option;
grant all privileges on *.* to 'root'@'%' identified by 'Mysql#123' with grant option;
grant all privileges on *.* to 'scm'@'localhost' identified by 'scm' with grant option;
grant all privileges on *.* to 'scm'@'node01' identified by 'scm' with grant option;
grant all privileges on *.* to 'scm'@'127.0.0.1' identified by 'scm' with grant option;
grant all privileges on *.* to 'scm'@'%' identified by 'scm' with grant option;
flush privileges;
**错误四:**ERROR Unable to create/drop a table.java.sql.SQLException: Statement violates GTID consistency: CREATE TABLE … SELECT.
连接成功,但是不能建表
解决方法:
若my.cnf中存在gtid_mode、enforce_gtid_consistency字段,需修改为如下内容:
gtid_mode = OFF
enforce_gtid_consistency = OFF
要两个参数一起改,然后重启mysql,问题解决
注意:GTID很简单,就是一个事务一个标记。create table as select被认为是两个事务。所有不行
2.未在已配置的存储库中找到任何 parcel。尝试在更多选项下添加一个自定义存储库。否则,您可能只能继续使用包。
注意: Parcle默认存储目录 /opt/cloudera/parcels
本地存放目录: 默认/opt/cloudera/parcel-repo
重启server和agent
3.报错pstree 命令无法找到
yum -y install psmisc
4.CDH常用的hive配置可进行优化的配置项
例如:hive.metastore.warehouse.dir
Hive 仓库目录是在 HDFS 中存储 Hive 表格的位置。注意此仓库目录的 Hive 默认值为“/user/hive/warehouse”。
具体其他配置项参照博文:CDH常用优化配置_Hive配置
二、HDFS
重要:CDH版的hdfs命令
//查看目录
#hdfs dfs -ls /
//切换hdfs用户
#su hdfs
//创建文本并上传到hdfs
# vim hello
# hdfs dfs -put hello /hello
//hdfs下查看hello
# hdfs dfs -text /hello
//将所有目录指定为root用户
#hdfs dfs -chown -R root:supergroup /
//将cdh目录指定给cdh用户
#hdfs dfs -chown -R cdh:supergroup /cdh
更多命令,可参考博主博文《HDFS常用命令整理》
1. HDFS中的namenode和datanode如何理解
HDFS集群有两类节点以管理节点-工作节点模式运行,即一个namenode(管理节点)和多个datanode(工作节点)。一个HDFS集群包含一个NameNode和若干的DataNode(start-dfs命令就启动了NameNode和DataNode), NameNode是管理者,主要负责管理hdfs文件系统,具体包括namespace命名空间管理(即目录结构)和block管理。DataNode主 要用来存储数据文件,举个例子:如果客户端client程序发起了读hdfs上的某个文件的指令, NameNode首先将找到这个文件对应的block,然后NameNode告知client,这些block数据在哪些DataNode上,之后, client将直接和DataNode交互。
namenode的文件目录可以在core-site.xml中设置:
2.HDFS启动权限问题:exec: /data/jdk/jdk1.8.0_231/bin/java: cannot execute: Permission denied
修改:修改JDK权限为777
3.HDFS的user和temp路径在服务器什么物理位置?如何查看HDFS文件目录结构?
物理地址文件:
vi /etc/hadoop/conf/hdfs-site.xml //hdfs配置文件和存放地址
vi /etc/hive/conf/hive-site.xml //hive配置文件
hdfs 位置:file:///data/dfs/nn
hive存储在hdfs的位置:/user/hive/warehouse
查看HDFS目录结构
【注意】dfs 命令已经取代hadoop;
管理员运行:su hdfs
退出:exit
查看hdfs文件位置: hdfs dfs -ls /
4.HDFS运行不良:‘No portmap or rpcbind service is running on this host. Please start portmap or rpcbind service before attempting to start the NFS Gateway role on this host.’
原因:缺少rpcbind服务,需要安装并启动
查看服务状态:systemctl status rpcbind.service
安装命令:yum install nfs-utils rpcbind
启动命令:systemctl start rpcbind.service
5.HDFS的超级用户和owner和group如何理解
启动namenode服务的用户就是超级用户, 该用户的组是supergroup
文件或者目录被创建之时,服从BSD规则,owner是客户端进程的用户,group是父目录的group
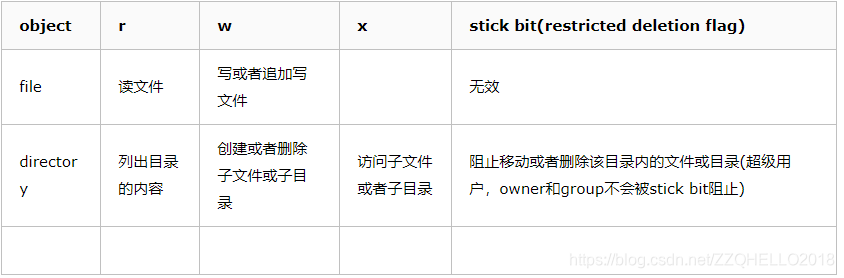
【访问权限说明】
三、Hive
1.hive创建 Hive Metastore 数据库表失败: ERROR Unable to find the MySQL JDBC driver. Please make sure that you have installed it as per instruction in the installation guide.’
步骤一:包放到:/usr/share/java/和/opt/cloudera/parcels/CDH/lib/hive/lib目录和/opt/cm-5.13.1/share/cmf/lib/ 下,统一命名mysql-connector-java.jar
一定要将版本号删除掉
cp /data/jdbc/mysql-connector-java.jar /usr/share/java/
cp /usr/share/java/mysql-connector-java.jar /opt/cloudera/parcels/CDH/lib/hive/lib/
cp /usr/share/java/mysql-connector-java.jar /opt/cm-5.13.1/share/cmf/lib/
2.创建 Hive Metastore 报错:ignoring option MaxPermSize=512M; support was removed in 8.0 org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
(1)一定要放到lib下
(2)架包改名,添加版本号
(3)权限改为777
3.Hive建表报错:user=hive, access=WRITE, inode="/":hdfs:supergroup:drwxr-
这是由于hdfs的操作权限不够
// 以超级管理员访问hdfs
[root@node01 bin]# su hdfs
//更改权限为777
[hdfs@node01 bin]$ hdfs dfs -chmod 777 /
//建表用户和用户权限
[hdfs@node01 root]$ hdfs dfs -ls /
建表成功,问题解决
四、sqoop
1. 权限问题:
方式一:前端控制台调整:
hdfs配置,搜索dfs.permissions---->检查 HDFS权限(dfs.permissions)取消勾选(默认是勾上的)
方式二:后端调整HDFS权限(推荐)
第一步:su hdfs,以管理员身份进入hdfs。
第二步:hdfs dfs -ls /,看一下user的权限。
第三步:修改权限 hdfs -chmod 777 /user
退出hdfs:exit
2. Oracle或sqlsever驱动问题
RuntimeException: Could not load db driver class: oracle.jdbc.OracleDriver
Could not load db driver class: com.microsoft.sqlserver.jdbc.SQLServerDriver
解决方法:
下载oracle、sqlsever对应版本驱动
将驱动,例如ojdbc6.jar移动到sqoop目录下,修改权限
cd /data/jdbc/oracle
cp * /opt/cloudera/parcels/CDH/lib/sqoop/lib/
其它
一、Hadoop2.0 动态增加节点
01.1 怎样添加节点
01.2 添加新的服务器节点
01.3 新节点操作系统配置
01.4 新节点Hadoop配置
01.5 调整新节点副本数二、Hadoop2.0 动态删除节点
02.1 怎样删除节点
02.2 删除Hadoop2.0集群节点
02.3 测试监控删除节点后的集群三、Hadoop2.0 HDFS HA部署
03.1 HDFS HA的实现方式
03.2 HDFS HA的实现步骤
03.3 HA集群环境配置
03.4 HA hdfs-site.xml参数配置
03.5 HA其他参数配置
03.6 JournalNode服务启动及初始化
03.7 HDFS HA服务启动及手工切换
03.8 基于ZK自动切换模式的实现
03.9 HDFS HA中ZooKeeper部署
03.10 配置HDFS HA自动切换模式
03.11 HDFS HA自动故障切换测试四、Hadoop2.0 HDFS HA+Federation部署
04.1 HDFS Federation的实现方式及规划
04.2 HDFS Federation的配置步骤
04.3 配置HDFS Federation
04.4 HDFS Federation服务启动及测试
04.5 HDFS HA+Federation实现及配置步骤
04.6 HDFS HA+Federation的配置及服务启动
04.7 HDFS HA+Federation集群故障模拟测试五、Hadoop升级
05.1 Hadoop内部升级的实现
05.2 Hadoop1.0升级到2.0步骤
05.3 HDFS升级配置操作
05.4 执行HDFS升级并测试验证
05.5 MapReduce升级六、Hadoop2.0 YARN HA部署
06.1 YARN HA的实现
06.2 YARN HA的配置步骤及其相关参数
06.3 Hadoop2.0 YARN HA配置操作
06.4 YARN HA服务启动及测试
06.5 YARN HA测试及错误处理
06.6 解决YARN HA启动错误的问题
06.7 HDFS+YARN HA故障模拟测试七、Hadoop安全管理深度剖析
07.1-Hadoop安全背景
07.2-Hadoop1.0安全问题及处理机制
07.3 Kerberos基本概念及授权认证过程
07.4 Kerberos在Hadoop中的应用
07.5 Hadoop1.0安全机制的具体实现
07.6 RPC安全之身份认证机制
07.7 RPC安全之服务访问控制机制
07.8 HDFS安全策略
07.9 Mapreduce安全策略
07.10 Hadoop上层服务的安全策略
07.11 Hadoop1.0安全机制的应用场景
07.12 Hadoop2.0安全认证机制的实现
07.13 Yarn中的各类令牌及其作用
07.14 Hadoop2.0授权机制的实现八、搭建本地yum安装CDH5 Hadoop集群
08.1 为什么选择CDH
08.2 CDH的体系架构
08.3 CDH的集群规划
08.4 CDH操作系统配置步骤
08.5 CDH集群主机名及网络配置
08.6 操作系统yum源配置
08.7 CDH5的yum源配置
08.8 主机间信任关系的建立
08.9 NTP时间同步服务配置
08.10 JDK安装
08.11 安装和配置HDFS步骤
08.12 YUM安装HDFS
08.13 CDH集群环境变量配置
08.14 CDH5 HDFS核心配置
08.15 HDFS其他重要配置及服务启动
08.16 安装和配置YARN的步骤
08.17 YARN的安装
08.18 YARN的核心参数配置
08.19 MapReduce相关参数配置
08.20 服务启动及验证
08.21 CDH5集群测试
08.22 webHDFS的使用九、基于Kerberos认证的Hadoop安全管理
09.1 Kerberos集群规划及配置步骤
09.2 Kerberos安装配置
09.3 Kerberos数据库创建及服务启动
09.4 Kerberos的使用及测试
09.5 Kerberos principal和keytab概念剖析
09.6 HDFS上配置Kerberos步骤
09.7 HDFS principal创建及生成keytab文件
09.8 HDFS keytab文件部署
09.9 HDFS安全参数配置
09.10 Namenode服务的安全启动
09.11 Datanode服务的安全启动
09.12 HDFS安全使用测试
09.13 YARN配置Kerberos步骤
09.14 YARN principal创建及keytab文件生成部署
09.15 YARN安全参数配置
09.16 YARN服务安全启动及测试
09.17 自动化集群管理十、Zookeeper&HIVE&HBASE&LDAP实现Kerberos认证
10.01 Zookeeper配置Kerberos步骤
10.02 通过Yum安装Zookeeper
10.03 Zookeeper Server配置Kerberos
10.04 Zookeeper Client配置kerberos
10.05 HBase相关概念深度解析
10.06 HBase配置Kerberos步骤
10.07 通过Yum安装HBase 01
10.08 通过Yum安装HBase 02
10.09 为HBase配置Kerberos
10.10 HBase启动错误诊断及测试
10.11 CDH Hive架构及配置Kerberos认证步骤
10.12 安装HIVE组件及配置PostgreSQL
10.13 Hive的基础配置
10.14 为Hive配置Kerberos认证
10.15 Hive shell及Beeline安全访问测试
10.16 hive与hbase集成原理
10.17 hive-hbase集成安装配置
10.18 hive-hbase映射表创建
10.19 LDAP基本概念
10.20 LDAP模式设计
10.21 LDAP集成Kerberos配置步骤
10.22 LDAP安装和基础配置
10.23 LDAP集成Kerberos及数据库创建
10.24 导入系统用户到LDAP
10.25 OpenLDAP客户端配置和使用十一、Impala大数据分析引擎
11.01 什么是Impala
11.02 Impala架构和进程
11.03 Impala安装配置步骤
11.04 Impala安装部署
11.05 Impala配置及服务启动
11.06 Impala配置Kerberos认证
11.07 Impala启停故障处理及测试
11.08 Impala的使用
11.09 Impala-shell基本功能的使用
11.10 Impala连接查询
11.11 Impala聚合及子查询
11.12 Impala分区表的使用
11.13 Impala的优化
11.14 Impala收集统计信息及生成查询计划
11.15 HDFS缓存池在Impala中的使用十二、Oozie&Hue的使用及安全认证管理
12.01 什么是oozie
12.02 Oozie安装和配置步骤
12.03 Oozie安装和基本配置
12.04 Oozie安全配置及服务启动
