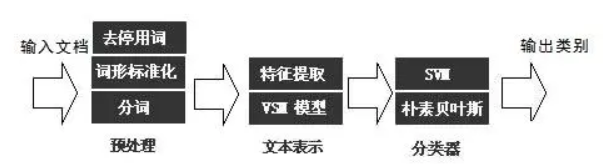
import pandas as pd
import random
import jieba
import pandas as pd
stopwords = pd.read_csv('stopword.txt',index_col=False,quoting=3,sep='\t',names=['stopwords'],encoding='utf-8')
stopwords = stopwords['stopwords'].values
data = pd.read_csv('data.csv',encoding='utf-8',seq=',')
data.dropna(inplace=True)
data = data.segment.values.tolist()
def preprocess(data):
for line in data:
try:
segs = jieba.lcut(line)
segs = [v for v in segs if not str(v).isdigit()]
segs = list(filter(lambda x:x.strip(),segs))
segs = list(filter(lambda x:len(x)>1,segs))
segs = list(filter(lambda x:x not in stopwords,segs))
sentences.append("".join(segs))
except Exception:
print(line)
continue
return sentences
segs = preprocess(data)
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(analyzer='word',max_features=4000)
for sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(data,random_state=42)
vec.fit(x_train)
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(x_train), y_train)
print(classifier.score(vec.transform(x_test), y_test))
pre = classifier.predict(vec.transform(x_test))
