概述
- 大数据计算的核心思想:移动计算比移动数据更划算
- MapReduce既是一个编程模型,又是一个计算框架
- 包含Map和Reduce两个过程
- 终极目标:用SQL语句分析大数据(Hive、SparkSQL,将SQL语句转换为MR程序)
特性
- 序列化
- java序列化:实现序列化接口(标识接口)
Student.java


1 package serializable; 2 3 import java.io.Serializable; 4 5 public class Student implements Serializable{ 6 private int stuID; 7 private String stuName; 8 public int getStuID() { 9 return stuID; 10 } 11 public void setStuID(int stuID) { 12 this.stuID = stuID; 13 } 14 public String getStuName() { 15 return stuName; 16 } 17 public void setStuName(String stuName) { 18 this.stuName = stuName; 19 } 20 }
TestMain.java
1 package serializable; 2 3 import java.io.FileOutputStream; 4 import java.io.ObjectOutputStream; 5 import java.io.OutputStream; 6 7 import serializable.Student; 8 9 public class TestMain { 10 11 public static void main(String[] args) throws Exception{ 12 // 创建学生对象 13 Student s = new Student(); 14 s.setStuID(1); 15 s.setStuName("Tom"); 16 17 // 输出对象到文件 18 OutputStream out = new FileOutputStream("F:\\eclipse-workspace\\student.ooo"); 19 ObjectOutputStream oos = new ObjectOutputStream(out); 20 oos.writeObject(s); 21 22 oos.close(); 23 out.close(); 24 } 25 }
-
- MapReduce序列化:核心接口Writable,实现了Writeble的类的对象可作为MapReduce的key和value
- 读取员工数据,生成员工对象,直接输出到HDFS
- hadoop jar s2.jar /scott/emp.csv /output/0910/s2
- MapReduce序列化:核心接口Writable,实现了Writeble的类的对象可作为MapReduce的key和value
EmpInfoMain.java
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.mapreduce.Job; 5 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 6 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 7 8 public class EmpInfoMain { 9 10 public static void main(String[] args) throws Exception { 11 Job job = Job.getInstance(new Configuration()); 12 job.setJarByClass(EmpInfoMain.class); 13 14 job.setMapperClass(EmpInfoMapper.class); 15 job.setMapOutputKeyClass(IntWritable.class); 16 job.setMapOutputValueClass(Emp.class); 17 18 job.setOutputKeyClass(IntWritable.class); 19 job.setOutputKeyClass(Emp.class); 20 21 FileInputFormat.setInputPaths(job, new Path(args[0])); 22 FileOutputFormat.setOutputPath(job, new Path(args[1])); 23 24 job.waitForCompletion(true); 25 } 26 }
EmpInfoMapper.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Mapper; 7 8 public class EmpInfoMapper extends Mapper<LongWritable, Text, IntWritable, Emp>{ 9 10 @Override 11 protected void map(LongWritable key1, Text value1, 12 Context context) 13 throws IOException, InterruptedException { 14 //数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30 15 String data = value1.toString(); 16 17 // 分词 18 String[] words = data.split(","); 19 20 // 生成员工对象 21 Emp emp = new Emp(); 22 emp.setEmpno(Integer.parseInt(words[0])); 23 emp.setEname(words[1]); 24 emp.setJob(words[2]); 25 emp.setMgr(Integer.parseInt(words[3])); 26 emp.setHiredate(words[4]); 27 emp.setSal(Integer.parseInt(words[5])); 28 emp.setComm(Integer.parseInt(words[6])); 29 emp.setDeptno(Integer.parseInt(words[7])); 30 31 // 输出员工对象 32 context.write(new IntWritable(emp.getEmpno()), emp); 33 } 34 }
Emp.java
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.Writable; 6 7 public class Emp implements Writable{ 8 private int empno; 9 private String ename; 10 private String job; 11 private int mgr; 12 private String hiredate; 13 private int sal; 14 private int comm; 15 private int deptno; 16 17 @Override 18 public void readFields(DataInput input) 19 throws IOException { 20 // 实现反序列化,从输入流中读取对象(与输出流顺序一样) 21 this.empno = input.readInt(); 22 this.ename = input.readUTF(); 23 this.job = input.readUTF(); 24 this.mgr = input.readInt(); 25 this.hiredate = input.readUTF(); 26 this.sal = input.readInt(); 27 this.comm = input.readInt(); 28 this.deptno = input.readInt(); 29 } 30 31 @Override 32 public void write(DataOutput output) throws IOException { 33 // 实现序列化,把对象输出到输出流 34 output.writeInt(this.empno); 35 output.writeUTF(this.ename); 36 output.writeUTF(this.job); 37 output.writeInt(this.mgr); 38 output.writeUTF(this.hiredate); 39 output.writeInt(this.sal); 40 output.writeInt(this.comm); 41 output.writeInt(this.deptno); 42 } 43 44 public int getEmpno() { 45 return empno; 46 } 47 48 public void setEmpno(int empno) { 49 this.empno = empno; 50 } 51 52 public String getEname() { 53 return ename; 54 } 55 56 public void setEname(String ename) { 57 this.ename = ename; 58 } 59 60 public String getJob() { 61 return job; 62 } 63 64 public void setJob(String job) { 65 this.job = job; 66 } 67 68 public int getMgr() { 69 return mgr; 70 } 71 72 public void setMgr(int mgr) { 73 this.mgr = mgr; 74 } 75 76 public String getHiredate() { 77 return hiredate; 78 } 79 80 public void setHiredate(String hiredate) { 81 this.hiredate = hiredate; 82 } 83 84 public int getSal() { 85 return sal; 86 } 87 88 public void setSal(int sal) { 89 this.sal = sal; 90 } 91 92 public int getComm() { 93 return comm; 94 } 95 96 public void setComm(int comm) { 97 this.comm = comm; 98 } 99 100 public int getDeptno() { 101 return deptno; 102 } 103 104 public void setDeptno(int deptno) { 105 this.deptno = deptno; 106 } 107 108 @Override 109 public String toString() { 110 return "Emp [empno=" + empno + ", ename=" + ename 111 + ", sal=" + sal + ", deptno=" + deptno 112 + "]"; 113 } 114 115 }

-
-
- 求部门工资总额
- 由于实现了序列化接口,员工可作为key和value
- 相比之前的程序更加简洁
- 对于大对象可能产生性能问题
- 求部门工资总额
-
EmpInfoMain.java
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.mapreduce.Job; 5 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 6 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 7 8 public class EmpInfoMain { 9 10 public static void main(String[] args) throws Exception { 11 Job job = Job.getInstance(new Configuration()); 12 job.setJarByClass(EmpInfoMain.class); 13 14 job.setMapperClass(EmpInfoMapper.class); 15 job.setMapOutputKeyClass(IntWritable.class); 16 job.setMapOutputValueClass(Emp.class); // 输出就是员工对象 17 18 job.setOutputKeyClass(IntWritable.class); 19 job.setOutputValueClass(Emp.class); 20 21 FileInputFormat.setInputPaths(job, new Path(args[0])); 22 FileOutputFormat.setOutputPath(job, new Path(args[1])); 23 24 job.waitForCompletion(true); 25 } 26 27 }
SalaryTotalMapper.java
1 import java.io.IOException; 2 import org.apache.hadoop.io.IntWritable; 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Mapper; 6 7 // k2:部门号 v2:员工对象 8 public class SalaryTotalMapper extends Mapper<LongWritable, Text, IntWritable, Emp> { 9 10 @Override 11 protected void map(LongWritable key1, Text value1, Context context) 12 throws IOException, InterruptedException { 13 // 数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30 14 String data = value1.toString(); 15 16 // 分词 17 String[] words = data.split(","); 18 19 // 生成员工对象 20 Emp emp = new Emp(); 21 emp.setEmpno(Integer.parseInt(words[0])); 22 emp.setEname(words[1]); 23 emp.setJob(words[2]); 24 emp.setMgr(Integer.parseInt(words[3])); 25 emp.setHiredate(words[4]); 26 emp.setSal(Integer.parseInt(words[5])); 27 emp.setComm(Integer.parseInt(words[6])); 28 emp.setDeptno(Integer.parseInt(words[7])); 29 30 // 输出员工对象 k2:部门号 v2:员工对象 31 context.write(new IntWritable(emp.getDeptno()), emp); 32 } 33 }
SalaryTotalReducer.java
1 import java.io.IOException; 2 import org.apache.hadoop.io.IntWritable; 3 import org.apache.hadoop.mapreduce.Reducer; 4 5 public class SalaryTotalReducer extends Reducer<IntWritable, Emp, IntWritable, IntWritable> { 6 7 @Override 8 protected void reduce(IntWritable k3, Iterable<Emp> v3,Context context) throws IOException, InterruptedException { 9 int total = 0; 10 11 //取出员工薪水,并求和 12 for(Emp e:v3){ 13 total = total + e.getSal(); 14 } 15 context.write(k3, new IntWritable(total)); 16 } 17 }
![]()
- 排序
- 规则:按照Key2排序
- 基本数据类型
- 数字:默认升序
- 自定义比较器:MyNumberComparator.java
- 主程序中添加比较器:job.setSortComparatorClass(MyNumberCompatator.class)
- 数字:默认升序
MyNumberComparator.java
1 import org.apache.hadoop.io.IntWritable; 2 3 //针对数字创建自己的比较规则,执行降序排序 4 public class MyNumberComparator extends IntWritable.Comparator { 5 6 @Override 7 public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { 8 // TODO Auto-generated method stub 9 return -super.compare(b1, s1, l1, b2, s2, l2); 10 } 11 }
-
- 字符串:默认字典顺序
MyTextComparator.java
1 import org.apache.hadoop.io.Text; 2 3 // 针对Text定义比较规则 4 public class MyTextComparator extends Text.Comparator{ 5 6 @Override 7 public int compare(byte[] b1, int s1, int l1, byte[] b2, 8 int s2, int l2) { 9 return -super.compare(b1, s1, l1, b2, s2, l2); 10 } 11 }
-
- 对象
- SQL排序:order by + 列名 / 表达式 / 列的别名 / 序号 / 多个列(desc作用于最近一列)
- 前提:对象必须是Key2;必须实现Writable接口;必须是可排序对象(类似Java对象排序,要实现Comparable<T>)
- 对象
Student.java
1 //学生对象:按照学生的age年龄进行排序 2 public class Student implements Comparable<Student>{ 3 4 private int stuID; 5 private String stuName; 6 private int age; 7 8 @Override 9 public String toString() { 10 return "Student [stuID=" + stuID + ", stuName=" + stuName + ", age=" + age + "]"; 11 } 12 13 @Override 14 public int compareTo(Student o) { 15 // 定义排序规则:按照学生的age年龄进行排序 16 if(this.age >= o.getAge()){ 17 return 1; 18 }else{ 19 return -1; 20 } 21 } 22 23 public int getStuID() { 24 return stuID; 25 } 26 public void setStuID(int stuID) { 27 this.stuID = stuID; 28 } 29 public String getStuName() { 30 return stuName; 31 } 32 public void setStuName(String stuName) { 33 this.stuName = stuName; 34 } 35 public int getAge() { 36 return age; 37 } 38 public void setAge(int age) { 39 this.age = age; 40 } 41 42 }
StudentMain.java
1 import java.util.Arrays; 2 3 public class StudentMain { 4 5 public static void main(String[] args) { 6 //创建几个学生对象 7 Student s1 = new Student(); 8 s1.setStuID(1); 9 s1.setStuName("Tom"); 10 s1.setAge(24); 11 12 Student s2 = new Student(); 13 s2.setStuID(2); 14 s2.setStuName("Mary"); 15 s2.setAge(26); 16 17 Student s3 = new Student(); 18 s3.setStuID(3); 19 s3.setStuName("Mike"); 20 s3.setAge(25); 21 22 //生成一个数组 23 Student[] list = {s1,s2,s3}; 24 25 //排序 26 Arrays.sort(list); 27 28 //输出 29 for(Student s:list){ 30 System.out.println(s); 31 } 32 } 33 }
-
-
- 一个/多个列排序
-
Emp.java
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.Writable; 6 import org.apache.hadoop.io.WritableComparable; 7 8 //代表员工 9 //数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30 10 public class Emp implements WritableComparable<Emp>{ 11 12 private int empno;//员工号 13 private String ename; //员工姓名 14 private String job; //职位 15 private int mgr; //经理的员工号 16 private String hiredate;//入职日期 17 private int sal; //月薪 18 private int comm; //奖金 19 private int deptno; //部门号 20 21 // @Override 22 // public int compareTo(Emp o) { 23 // // 定义自己的排序规则:一个列的排序 24 // // 按照薪水进行排序 25 // if(this.sal >= o.getSal()){ 26 // return 1; 27 // }else{ 28 // return -1; 29 // } 30 // } 31 32 @Override 33 public int compareTo(Emp o) { 34 // 定义自己的排序规则:多个列的排序 35 // 先按照部门号进行排序,再按照薪水进行排序 36 if(this.deptno > o.getDeptno()){ 37 return 1; 38 }else if(this.deptno < o.getDeptno()){ 39 return -1; 40 } 41 42 //再按照薪水进行排序 43 if(this.sal >= o.getSal()){ 44 return 1; 45 }else{ 46 return -1; 47 } 48 } 49 50 @Override 51 public String toString() { 52 return "Emp [empno=" + empno + ", ename=" + ename + ", sal=" + sal + ", deptno=" + deptno + "]"; 53 } 54 55 @Override 56 public void readFields(DataInput input) throws IOException { 57 //实现反序列化,从输入流中读取对象 58 this.empno = input.readInt(); 59 this.ename = input.readUTF(); 60 this.job = input.readUTF(); 61 this.mgr = input.readInt(); 62 this.hiredate = input.readUTF(); 63 this.sal = input.readInt(); 64 this.comm = input.readInt(); 65 this.deptno = input.readInt(); 66 } 67 68 @Override 69 public void write(DataOutput output) throws IOException { 70 // 实现序列化,把对象输出到输出流 71 output.writeInt(this.empno); 72 output.writeUTF(this.ename); 73 output.writeUTF(this.job); 74 output.writeInt(this.mgr); 75 output.writeUTF(this.hiredate); 76 output.writeInt(this.sal); 77 output.writeInt(this.comm); 78 output.writeInt(this.deptno); 79 } 80 81 82 public int getEmpno() { 83 return empno; 84 } 85 public void setEmpno(int empno) { 86 this.empno = empno; 87 } 88 public String getEname() { 89 return ename; 90 } 91 public void setEname(String ename) { 92 this.ename = ename; 93 } 94 public String getJob() { 95 return job; 96 } 97 public void setJob(String job) { 98 this.job = job; 99 } 100 public int getMgr() { 101 return mgr; 102 } 103 public void setMgr(int mgr) { 104 this.mgr = mgr; 105 } 106 public String getHiredate() { 107 return hiredate; 108 } 109 public void setHiredate(String hiredate) { 110 this.hiredate = hiredate; 111 } 112 public int getSal() { 113 return sal; 114 } 115 public void setSal(int sal) { 116 this.sal = sal; 117 } 118 public int getComm() { 119 return comm; 120 } 121 public void setComm(int comm) { 122 this.comm = comm; 123 } 124 public int getDeptno() { 125 return deptno; 126 } 127 public void setDeptno(int deptno) { 128 this.deptno = deptno; 129 } 130 131 }
EmpSortMapper.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.NullWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Mapper; 8 9 /* 10 * 一定要把Emp作为key2 11 * 没有value2,返回null值 12 */ 13 14 public class EmpSortMapper extends Mapper<LongWritable, Text, Emp, NullWritable> { 15 16 @Override 17 protected void map(LongWritable key1, Text value1, Context context) 18 throws IOException, InterruptedException { 19 // 数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30 20 String data = value1.toString(); 21 22 //分词 23 String[] words = data.split(","); 24 25 //生成员工对象 26 Emp emp = new Emp(); 27 emp.setEmpno(Integer.parseInt(words[0])); 28 emp.setEname(words[1]); 29 emp.setJob(words[2]); 30 emp.setMgr(Integer.parseInt(words[3])); 31 emp.setHiredate(words[4]); 32 emp.setSal(Integer.parseInt(words[5])); 33 emp.setComm(Integer.parseInt(words[6])); 34 emp.setDeptno(Integer.parseInt(words[7])); 35 36 //输出员工对象 k2:员工对象 v2:空值 37 context.write(emp, NullWritable.get()); 38 } 39 }
EmpSortMain.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.NullWritable; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 11 public class EmpSortMain { 12 13 public static void main(String[] args) throws Exception { 14 Job job = Job.getInstance(new Configuration()); 15 job.setJarByClass(EmpSortMain.class); 16 17 job.setMapperClass(EmpSortMapper.class); 18 job.setMapOutputKeyClass(Emp.class); //k2 是员工对象 19 job.setMapOutputValueClass(NullWritable.class); // v2:是空值 20 21 job.setOutputKeyClass(Emp.class); 22 job.setOutputValueClass(NullWritable.class); 23 24 FileInputFormat.setInputPaths(job, new Path(args[0])); 25 FileOutputFormat.setOutputPath(job, new Path(args[1])); 26 27 job.waitForCompletion(true); 28 29 } 30 31 }
- 分区(Partition)
- 关系型数据库分区
- 分区1:sal<=3000,分区2:3000<sal<=5000,分区3:sal>5000
- 查询薪水1000~2000的员工,只扫描分区1即可
- Hash分区:根据数值的Hash结果进行分区,如果一样就放入同一个分区中(数据尽量打散,避免热块)
- Redis Cluster、Hive 桶表、MongoDB 分布式路由
- MR分区
- 根据Map的输出<key2 value2>进行分区
- 默认情况下,MR的输出只有一个分区(一个分区就是一个文件)
- 按部门号分区:不同部门的员工放到不同文件中
- 关系型数据库分区
Emp.java
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.Writable; 6 7 //代表员工 8 //数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30 9 public class Emp implements Writable{ 10 11 private int empno;//员工号 12 private String ename; //员工姓名 13 private String job; //职位 14 private int mgr; //经理的员工号 15 private String hiredate;//入职日期 16 private int sal; //月薪 17 private int comm; //奖金 18 private int deptno; //部门号 19 20 21 @Override 22 public String toString() { 23 return "Emp [empno=" + empno + ", ename=" + ename + ", sal=" + sal + ", deptno=" + deptno + "]"; 24 } 25 26 @Override 27 public void readFields(DataInput input) throws IOException { 28 //实现反序列化,从输入流中读取对象 29 this.empno = input.readInt(); 30 this.ename = input.readUTF(); 31 this.job = input.readUTF(); 32 this.mgr = input.readInt(); 33 this.hiredate = input.readUTF(); 34 this.sal = input.readInt(); 35 this.comm = input.readInt(); 36 this.deptno = input.readInt(); 37 } 38 39 @Override 40 public void write(DataOutput output) throws IOException { 41 // 实现序列化,把对象输出到输出流 42 output.writeInt(this.empno); 43 output.writeUTF(this.ename); 44 output.writeUTF(this.job); 45 output.writeInt(this.mgr); 46 output.writeUTF(this.hiredate); 47 output.writeInt(this.sal); 48 output.writeInt(this.comm); 49 output.writeInt(this.deptno); 50 } 51 52 53 public int getEmpno() { 54 return empno; 55 } 56 public void setEmpno(int empno) { 57 this.empno = empno; 58 } 59 public String getEname() { 60 return ename; 61 } 62 public void setEname(String ename) { 63 this.ename = ename; 64 } 65 public String getJob() { 66 return job; 67 } 68 public void setJob(String job) { 69 this.job = job; 70 } 71 public int getMgr() { 72 return mgr; 73 } 74 public void setMgr(int mgr) { 75 this.mgr = mgr; 76 } 77 public String getHiredate() { 78 return hiredate; 79 } 80 public void setHiredate(String hiredate) { 81 this.hiredate = hiredate; 82 } 83 public int getSal() { 84 return sal; 85 } 86 public void setSal(int sal) { 87 this.sal = sal; 88 } 89 public int getComm() { 90 return comm; 91 } 92 public void setComm(int comm) { 93 this.comm = comm; 94 } 95 public int getDeptno() { 96 return deptno; 97 } 98 public void setDeptno(int deptno) { 99 this.deptno = deptno; 100 } 101 }
MyPartitionerMain.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.mapreduce.Job; 7 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 8 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 9 10 public class MyPartitionerMain { 11 12 public static void main(String[] args) throws Exception { 13 Job job = Job.getInstance(new Configuration()); 14 job.setJarByClass(MyPartitionerMain.class); 15 16 job.setMapperClass(MyPartitionerMapper.class); 17 job.setMapOutputKeyClass(IntWritable.class); //k2 是部门号 18 job.setMapOutputValueClass(Emp.class); // v2输出就是员工对象 19 20 //加入分区规则 21 job.setPartitionerClass(MyPartitioner.class); 22 //指定分区的个数 23 job.setNumReduceTasks(3); 24 25 job.setReducerClass(MyPartitionerReducer.class); 26 job.setOutputKeyClass(IntWritable.class); 27 job.setOutputValueClass(Emp.class); 28 29 FileInputFormat.setInputPaths(job, new Path(args[0])); 30 FileOutputFormat.setOutputPath(job, new Path(args[1])); 31 32 job.waitForCompletion(true); 33 } 34 }
MyPartitionerMapper.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Mapper; 7 8 // k2 部门号 v2 员工 9 public class MyPartitionerMapper extends Mapper<LongWritable, Text, IntWritable, Emp> { 10 11 @Override 12 protected void map(LongWritable key1, Text value1, Context context) 13 throws IOException, InterruptedException { 14 // 数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30 15 String data = value1.toString(); 16 17 //分词 18 String[] words = data.split(","); 19 20 //生成员工对象 21 Emp emp = new Emp(); 22 emp.setEmpno(Integer.parseInt(words[0])); 23 emp.setEname(words[1]); 24 emp.setJob(words[2]); 25 emp.setMgr(Integer.parseInt(words[3])); 26 emp.setHiredate(words[4]); 27 emp.setSal(Integer.parseInt(words[5])); 28 emp.setComm(Integer.parseInt(words[6])); 29 emp.setDeptno(Integer.parseInt(words[7])); 30 31 //输出员工对象 k2:部门号 v2:员工对象 32 context.write(new IntWritable(emp.getDeptno()), emp); 33 } 34 }
MyPartitionerReducer.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.mapreduce.Reducer; 5 6 //就是同一个部门的员工 7 public class MyPartitionerReducer extends Reducer<IntWritable, Emp, IntWritable, Emp> { 8 9 @Override 10 protected void reduce(IntWritable k3, Iterable<Emp> v3,Context context) throws IOException, InterruptedException { 11 // 直接输出 12 for(Emp e:v3){ 13 context.write(k3, e); 14 } 15 } 16 }
- 合并(Combiner)
- 一种特殊的Reducer,部署在Mapper端
- 在Mapper端执行一次合并,用于减少Mapper输出到Reducer的数据量,提高效率
- 在wordCountMain.java中添加job.setCombinerClass(WordCountReducer.class)
- 谨慎使用Combiner,有些情况不能使用(如求平均值)
- 不管有没有Combiner,都不能改变Map和Reduce对应的数据类型
- 程序出错,可将Reducer的k3 类型改为DoubleWritable
AvgSalaryMain.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.DoubleWritable; 6 import org.apache.hadoop.io.IntWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 10 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 11 12 public class AvgSalaryMain { 13 14 public static void main(String[] args) throws Exception { 15 //1、创建任务、指定任务的入口 16 Job job = Job.getInstance(new Configuration()); 17 job.setJarByClass(AvgSalaryMain.class); 18 19 //2、指定任务的map和map输出的数据类型 20 job.setMapperClass(AvgSalaryMapper.class); 21 job.setMapOutputKeyClass(Text.class); 22 job.setMapOutputValueClass(IntWritable.class); 23 24 //加入Combiner 25 job.setCombinerClass(AvgSalaryReducer.class); 26 27 //3、指定任务的reducer和reducer输出的类型 28 job.setReducerClass(AvgSalaryReducer.class); 29 job.setOutputKeyClass(Text.class); 30 job.setOutputValueClass(DoubleWritable.class); 31 32 //4、指定任务输入路径和输出路径 33 FileInputFormat.setInputPaths(job, new Path(args[0])); 34 FileOutputFormat.setOutputPath(job, new Path(args[1])); 35 36 //5、执行任务 37 job.waitForCompletion(true); 38 39 } 40 }
AvgSalaryMapper.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Mapper; 7 8 // k2 常量 v2:薪水 9 public class AvgSalaryMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 10 11 @Override 12 protected void map(LongWritable key1, Text value1, Context context) 13 throws IOException, InterruptedException { 14 // 数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30 15 String data = value1.toString(); 16 17 //分词 18 String[] words = data.split(","); 19 20 //输出 k2 常量 v2 薪水 21 context.write(new Text("salary"), new IntWritable(Integer.parseInt(words[5]))); 22 } 23 }
AvgSalaryReducer.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.DoubleWritable; 4 import org.apache.hadoop.io.IntWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Reducer; 7 8 // v4:平均工资 9 public class AvgSalaryReducer extends Reducer<Text, IntWritable, Text, DoubleWritable> { 10 11 @Override 12 protected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException { 13 int total = 0; 14 int count = 0; 15 16 for(IntWritable salary:v3){ 17 //工资求和 18 total = total + salary.get(); 19 //人数加一 20 count ++; 21 } 22 23 //输出 24 context.write(new Text("The avg salary is :"), new DoubleWritable(total/count)); 25 } 26 27 }

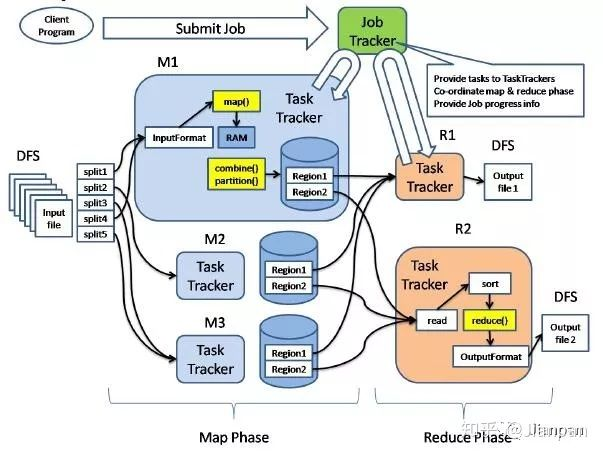
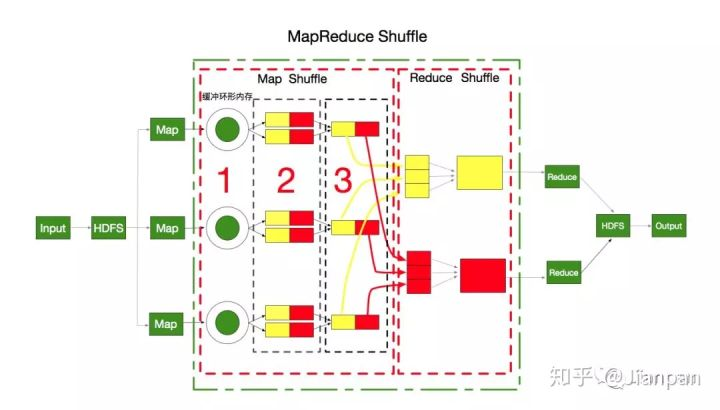
Shuffle
- MapReduce的核心
- map输出后到reduce接收前
- Hadoop 3.x以前: 会有数据落地(I/O操作)
- Spark只有两次I/O操作(读+写),中间运算在内存中完成
例题
- 词频统计(word count)
- 一篇文章用哈希表统计即可
- 对互联网所有网页的词频进行统计(Google搜索引擎的需求),无法将所有网页读入内存
- 过程
- map:将单词提取出来,对每个单词输入一个<word,1>这样的<k,v>对,进而将相同的数据放在一起,形成<word,<1,1,1,...>>这样的<k,v集合>
- reduce:将集合里的1求和,再将单词和这个和组成<word,sum>输出
- 一个map函数仅对一个HDFS数据块上的数据进行计算,从而实现大数据的分布式计算
- 在分布式集群中调度执行MapReduce程序的计算框架也叫MapReduce
- 求部门工资总额
- SQL:select deptno,sum(sal) from emp gruop by deptno;
- 分析数据类型,套用模板重写map()、reduce()
- 导出jar包,指定main class
- 把数据保存在hdfs中
- hadoop jar s1.jar /input/emp.csv /output/0910/s1


SalaryTotalMapper.java
View Code
SalaryTotalReducer.java
View Code
SalaryTotalMain.java
View Code
- 数据去重
- select distinct depno, job from emp;
- 用MR实现
- 只有Mapper没有Reducer(排序)
DistinctMain.java
View Code
DistinctMapper.java
View Code
DistinctReducer.java
View Code
- 多表查询
- select dname,ename from dept, emp where emp.deptno=dept.deptno;
- 关系型数据库的子查询会转换成多表查询(通过执行计划看SQL语句的执行过程和效率)
- 笛卡尔积:列数相加,行数相乘,得到全集
- 用连接条件(如 emp.deptno=dept.deptno)去掉全集中的错误数据
- 连接条件至少N-1个(N为表的个数)
- 根据连接条件不同,分为:
- 等值连接 / 不等值连接
- 外连接 / 自连接



-
- 通过MR实现连接
EqualJoinMain.java
View Code
EqualJoinMapper.java
View Code
EqualJoinReducer.java
View Code

- 自连接
- 通过表的别名,将同一张表视为多张表
- 一个人是下级的老板,同时是上级的员工
- 同一条数据输出两次,一次作为老板,一次作为员工(看作两张表)
- 相同的k2,其value2会被同一个reducer处理
- 存在非法数据需进行清洗(如把大老板的老板编号置为-1)
- 老板和员工同时存在才输出(员工树的根节点和叶子节点不显示)


SelfJoinMain.java
View Code
SelfJoinMapper.java
View Code
SelfJoinReducer.java
View Code


- 倒排索引
- 关系型数据库的索引

-
- 数据存储在HDFS后会建立索引,提高查找效率


- MR实现倒排索引
- 记录一个单词在一个文件中出现的次数
- Combiner对同一文件中重复出现的单词进行求和
- Reducer对不同文件中出现的单词进行汇总
- 保证有无Combiner前后数据类型一样


RevertedIndexMain.java
View Code
RevertedIndexMapper.java
View Code
RevertedIndexCombiner.java
View Code
RevertedIndexReducer.java
View Code
- Hadoop自带例题
- start-all.sh
- /root/training/hadoop-2.7.3/share/hadoop/mapreduce
- hadoop jar hadoop-mapreduce-examples-2.7.3.jar
- wordcount: A map/reduce program that counts the words in the input files.
- hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount
- Usage: wordcount <in> [<in>...] <out>
- hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /output/0402/wc