一、线性回归中梯度下降法的向量化:

正规方程:
import numpy as np
from sklearn import datasets
from playML.model_selection import train_test_split
from playML.LinearRegression import LinearRegression
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
lin_reg1 = LinearRegression()
%time lin_reg1.fit_normal(X_train, y_train)
lin_reg1.score(X_test, y_test)
Output:

使用梯度下降法:
接上面的代码
lin_reg2 = LinearRegression()
lin_reg2.fit_gd(X_train, y_train)
lin_reg2.coef_
X_train[:10,:]
Output:

lin_reg2.fit_gd(X_train, y_train, eta=0.000001)
lin_reg2.score(X_test, y_test)
Output:

%time lin_reg2.fit_gd(X_train, y_train, eta=0.000001, n_iters=1e6)
lin_reg2.score(X_test, y_test)
Output:


二、梯度下降法与数据归一化:
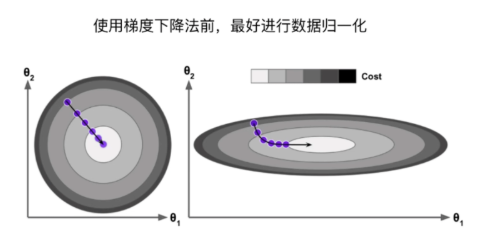
对数据进行归一化有助于提高梯度下降法的收敛速度。
from sklearn.preprocessing import StandardScaler # 归一化
from playML.LinearRegression import LinearRegression
standardScaler = StandardScaler()
standardScaler.fit(X_train) # 特征缩放
X_train_stadard = standardScaler.transform(X_train)
lin_reg3 = LinearRegression()
%time lin_reg3.fit_gd(X_train_stadard, y_train)
# Wall time: 187 ms
X_test_standard = standardScaler.transform(X_test)
lin_reg3.score(X_test_standard, y_test)
# 0.8129873310487505
三、梯度下降法的优势
m = 1000
n = 5000
big_X = np.random.normal(size=(m, n))
true_theta = np.random.uniform(0.0, 100.0, size=n+1)
big_y = big_X[:].dot(true_theta[1:]) + true_theta[0] + np.random.normal(0., 10., size=m) # 添加噪声
特征量大于样本量
big_reg1 = LinearRegression()
%time big_reg1.fit_normal(big_X, big_y)
# Wall time: 5.85 s
big_reg2 = LinearRegression()
%time big_reg2.fit_gd(big_X, big_y)
# Wall time: 3.69 s
参考资料:bobo老师机器学习教程
