@article{wang2019orthogonal,
title={Orthogonal Convolutional Neural Networks.},
author={Wang, Jiayun and Chen, Yubei and Chakraborty, Rudrasis and Yu, Stella X},
journal={arXiv: Computer Vision and Pattern Recognition},
year={2019}}
概
本文提出了一种正交化CNN的方法.
主要内容
符号说明
\(X \in \mathbb{R}^{N \times C \times H \times W}\): 输入
\(K \in \mathbb{R}^{M \times C \times k \times k}\): 卷积核
\(Y \in \mathbb{R}^{N \times M \times H' \times W'}\): 输出
\(Y=Conv(K,X)\)的俩种表示
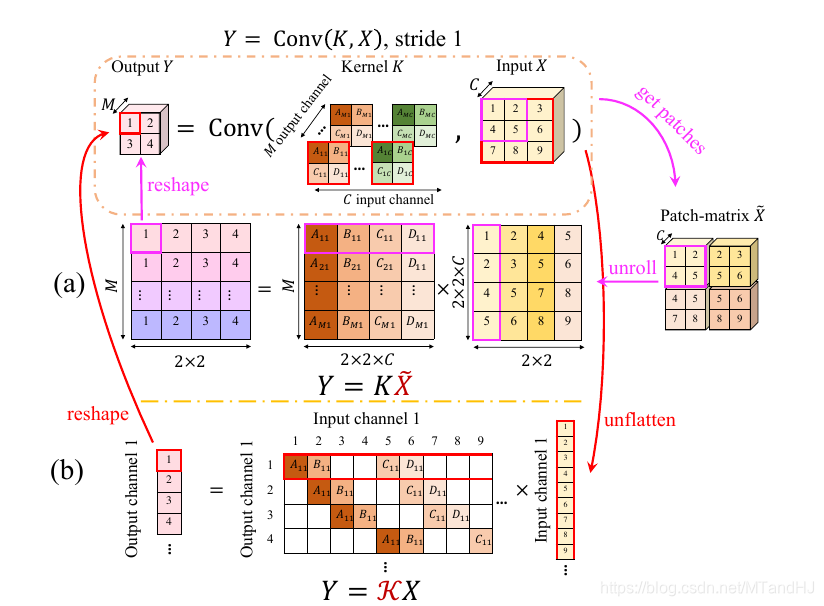
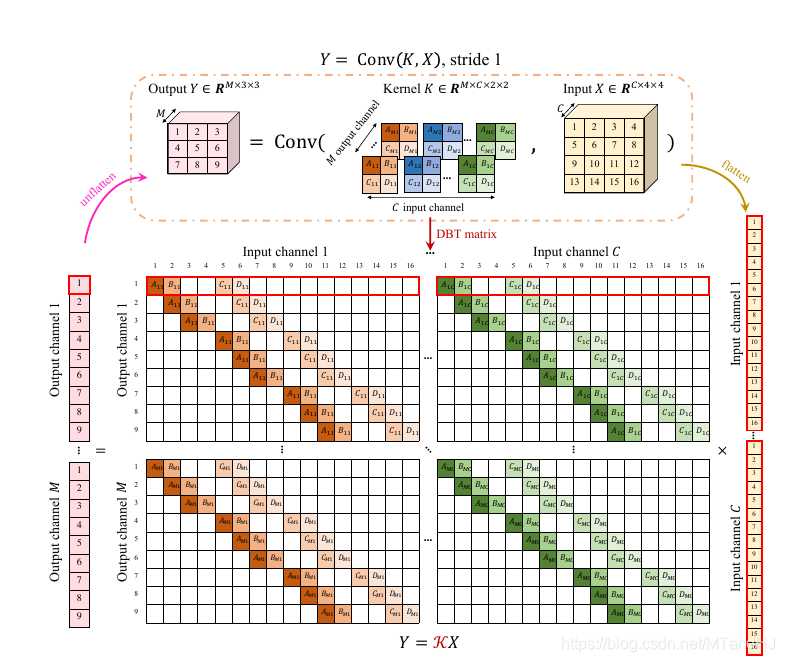
\(Y=K\tilde{X}\)
此时\(K\in \mathbb{R}^{M \times Ck^2}\), 每一行相当于一个卷积核, \(\tilde{X} \in \mathbb{R}^{Ck^2 \times H'W'}\), \(Y \in \mathbb{R}^{M \times H'W'}\).
\(Y=\mathcal{K}X\)
此时\(X \in \mathbb{R}^{CHW}\)相当于将一张图片拉成条, \(\mathcal{K} \in \mathbb{R}^{MHW' \times CHW}\), 同样每一次行列作内积相当于一次卷积操作, \(Y \in \mathbb{R}^{MH'W'}\).
kernel orthogonal regularization
相当于要求\(KK^T=I\)(行正交) 或者\(K^TK=I\)(列正交), 正则项为
作者在最新的论文版本中说明了, 这二者是等价的.
orthogonal convolution
作者期望的便是\(\mathcal{K}\mathcal{K}^T=I\)或者\(\mathcal{K}^T\mathcal{K}=I\).
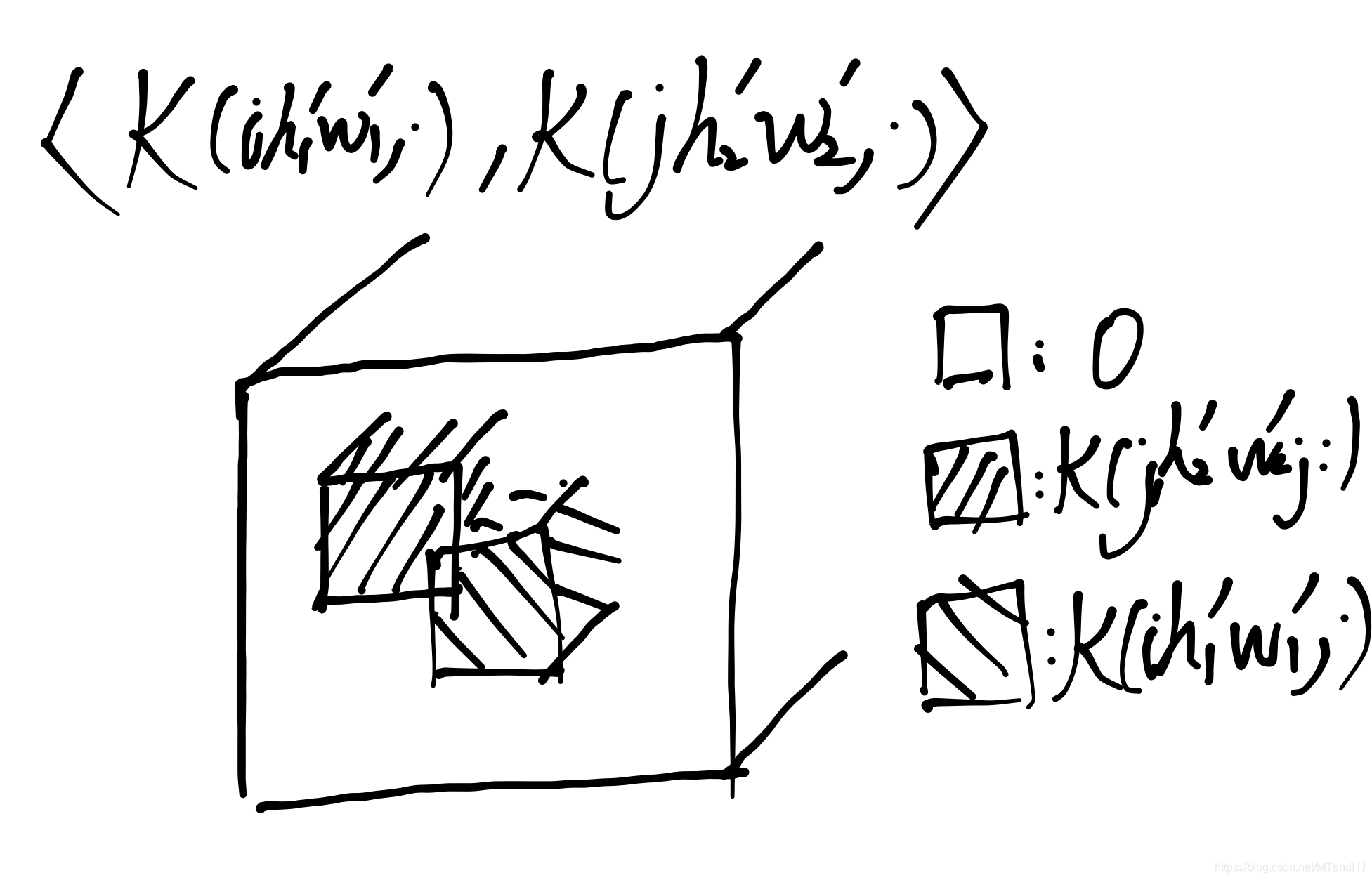
用\(\mathcal{K}(ihw,\cdot)\)表示第\((i-1) H'W'+(h-1)W'+w\)行, 对应的\(\mathcal{K}(\cdot, ihw)\)表示\((i-1) HW+(h-1)W+w\)列.
则\(\mathcal{K}\mathcal{K}^T=I\)等价于
\(\mathcal{K}^T\mathcal{K}=I\)等价于
实际上这么作是由很多冗余的, 可以进一步化为更简单的形式.
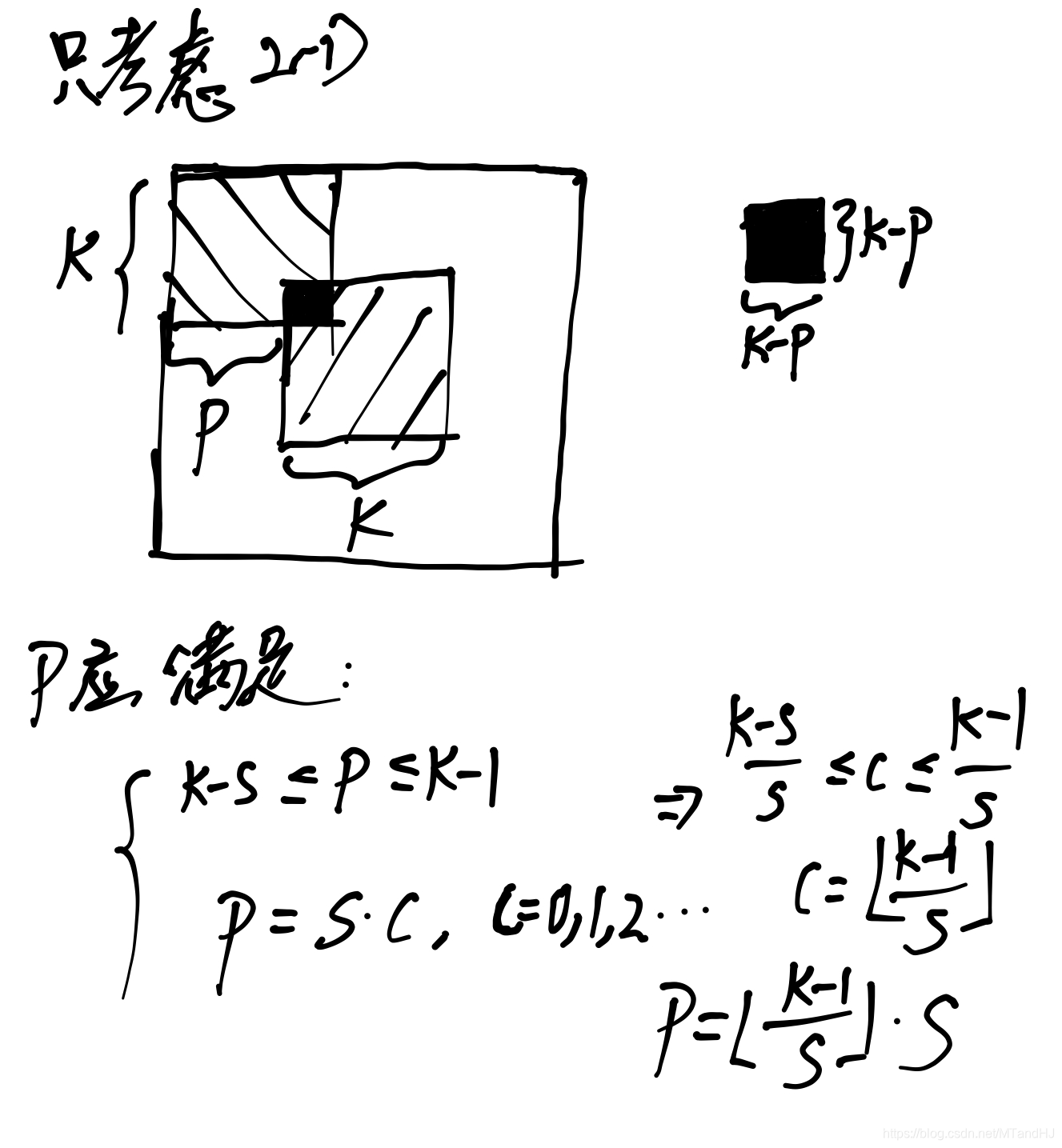
(5)等价于
其中\(I_{r0}\in \mathbb{R}^{M\times M \times (2P/S+1) \times (2P/S+1)}\)仅在\([i,i,\lfloor \frac{k-1}{S} \rfloor+1,\lfloor \frac{k-1}{S} \rfloor+1], i=1,\ldots, M\)处为\(1\)其余元素均为\(0\).
其推导过程如下(这个实在不好写清楚):
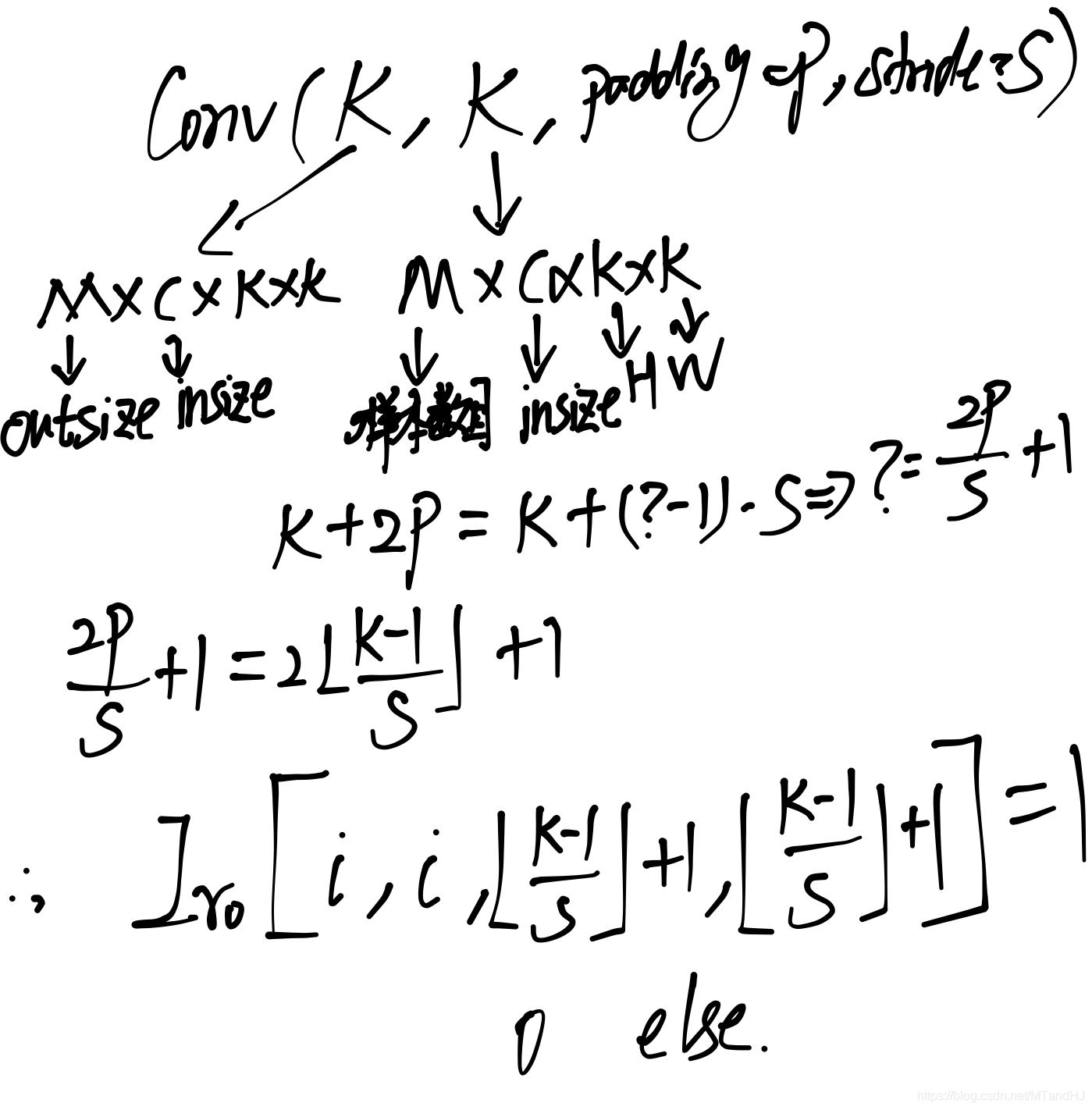
\(\mathcal{K}^T\mathcal{K}\)在\(S=1\)特殊情况下的特殊情况下, (10)等价于
其中\(I_{c0} \in \mathbb{R}^{C \times C \times (2k-1) \times (2k-1)}\), 同样仅在\((i,i,k,k)\)处为1, 其余非零.\(K^T \in \mathbb{R}^{C \times M \times k \times k}\)是\(K\)的第1, 2坐标轴进行变换.
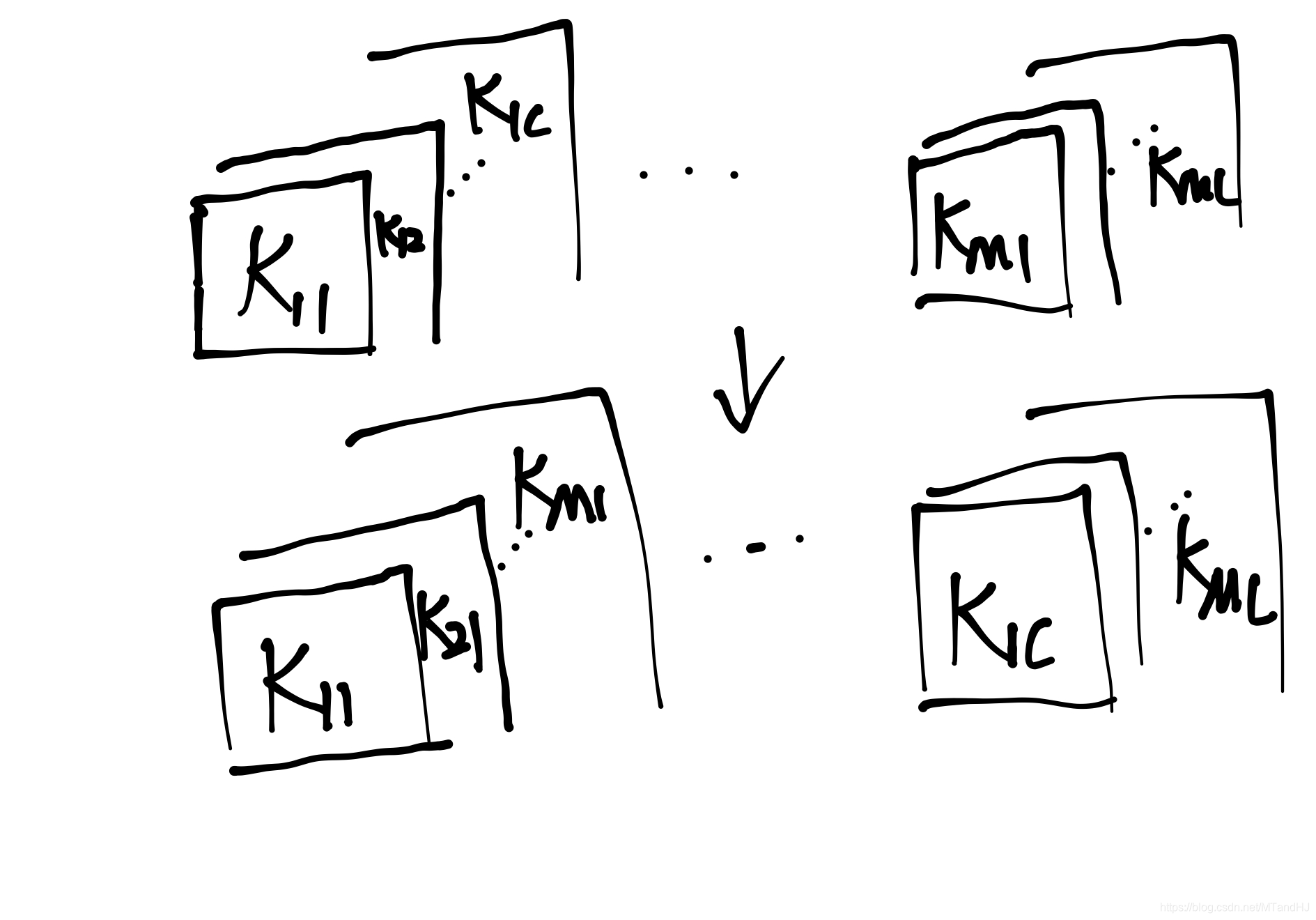
同样的
与
是等价的.
另一方面, 最开始提到的kernel orthogonal regularization是orthogonal convolution的必要条件(但不充分)\(KK^T=I\), \(K^TK=I\)分别等价于:
其中\(I_{r0} \in \mathbb{R}^{M \times M \times 1 \times 1}\), \(I_{c0} \in \mathbb{R}^{C \times C \times 1 \times 1}\).