查找当前解压文件之后,hadoop2.7.3的默认配置文件, 四个文件的.xml,
1.core-default.xml common\hadoop-common-2.7.3.jar2.hdfs-default.xml hdfs\hadoop-hdfs-2.7.3
3.mapred-default.xml mapreduce\hadoop-hdfs-2.7.3.jar
4.yarn-default.xml yarn\hadoop-yarn-common-2.7.3.jar

三种启动方式介绍
方式一:逐一启动(实际生产环境中的启动方式)
hadoop-daemon.sh start|stop namenode|datanode| journalnode
yarn-daemon.sh start |stop resourcemanager|nodemanager
方式二:分开启动
start-dfs.sh
start-yarn.sh
方式三:一起启动
start-all.sh
start-all.sh脚本:
说明:start-all.sh实际上是调用sbin/start-dfs.sh脚本和sbin/start-yarn.sh脚本
脚本解读
start-dfs.sh脚本:
(1) 通过命令bin/hdfs getconf –namenodes查看namenode在那些节点上
(2) 通过ssh方式登录到远程主机,启动hadoop-deamons.sh脚本
(3) hadoop-deamon.sh脚本启动slaves.sh脚本
(4) slaves.sh脚本启动hadoop-deamon.sh脚本,再逐一启动
注意:为什么要使用SSH??
当执行start-dfs.sh脚本时,会调用slaves.sh脚本,通过ssh协议无密码登陆到其他节点去启动进程。三种启动方式的关系
start-all.sh :其实调用start-dfs.sh和start-yarn.sh
start-dfs.sh:调用hadoop-deamon.sh
start-yarn.sh:调用yarn-deamon.sh
如下图:
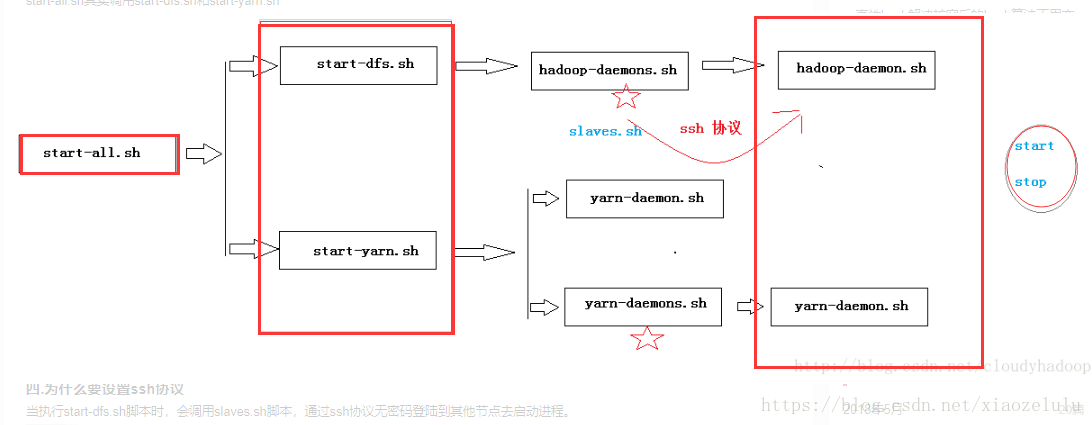
hadoop-daemon.sh 和Hadoop-daemons.sh 的区别
Hadoop-daemon.sh:用于启动当前节点的进程
Hadoop-daemons.sh:用于启动所有节点的进程
有时候我们可能/hyxy/hadoop/etc/hadoop文件夹会宕机,找不到,一般我们会备份这个文件,这里备份为hadoop_pseudo ,之后启动服务(或关闭),会提示:找不到路径,
所以,这个时候我们就可以:分别启动服务进程,达到目的。
分别动守护进程--启动顺序不重要
假如:mv ~/soft/hadoop/etc/hadoop hadoop_pseudo提示: 可能会出现文件被更名,启动服务找不到路径,我们可以单独去启动某个服务启动的路径。
1) 直接输入
etc$>1.namenode进程
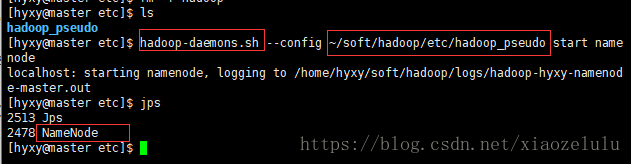
hadoop-daemons.sh --config ~/soft/hadoop/etc/hadoop_pseudo start namenode
守护进程 配置项 传这个配置路径 可能/etc/hadoop更名为hadoop_pseudo,找不到路径,我们可以配置后来的路径,
去开启服务。
2.启动datanode进程
hadoop-daemons.sh --config ~/soft/hadoop/etc/hadoop_pseudo start datanode
3.启动secondarynamenode进程
hadoop-daemons.sh --config ~/soft/hadoop/etc/hadoop_pseudo start secondarynamenode
[hyxy@master etc]$ hadoop-daemons.sh --config ~/soft/hadoop/etc/hadoop_pseudo start namenode
localhost: starting namenode, logging to /home/hyxy/soft/hadoop/logs/hadoop-hyxy-namenode-master.out
[hyxy@master etc]$ jps
2513 Jps
2478 NameNode
注:杀掉某个进程:kill 2478,如下,杀掉namenode进程了。

2)可以不指定路径,在命令行上export 或者在.bash_profile
执行下列:~/soft/hadoop/etc/hadoop_pseudo
etc$> hadoop-daemons.sh start secondarynamenode会报错,解决:
etc$> export HADOOP_CONF_DIR=~/soft/hadoop/etc/hadoop_pseudo 只在本次页面有用
etc$> hadoop-daemons.sh start secondarynamenode
[hyxy@master etc]$ export HADOOP_CONF_DIR=~/soft/hadoop/etc/hadoop_pseudo
[hyxy@master etc]$ hadoop-daemons.sh start secondarynamenode
localhost: starting secondarynamenode, logging to /home/hyxy/soft/hadoop/logs/hadoop-hyxy-secondarynamenode-master.out
[hyxy@master etc]$ jps
2983 Jps
2942 SecondaryNameNode

命令:hadoop-daemon.sh
etc$> hadoop-daemon.sh
Usage: hadoop-daemon.sh [--config <conf-dir>] [--hosts hostlistfile] [--script script] (start|stop) <hadoop-command> <args...>前提【:三者之一均可:
①/etc/hadoop文件没有改名, ②/etc/hadoop_pseudo,改名了, 在.bash_profile配置了HADOOP_CONF_DIR=
~/soft/hadoop/etc/hadoop_pseudo 的绝对路径了。 (直接export也行)③改名后,创建软链接:ln -s hadoop_pseudo hadoop 到时候找路径,还是原先那样的路径,只不过本质变成软连接了。】
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start namenode
hadoop-daemons.sh start datanode 要加s,datanode是复数
hadoop默认查找{HADOOP_HOME}/etc/hadoop
sbin$> hadoop-daemons.sh start namenode
直接启动也可以
命令: hadoop-daemons.sh
Usage: hadoop-daemons.sh [--config confdir] [--hosts hostlistfile] [start|stop] command args...配置目录
笔记:
Hadoop的瓶颈是:物理存储!!而绝非网络、内核 CPU、内存;
last connect:最后连接的时间;
datanode:宕机是常态,不是一种异常;
伪分布是完全分布的一种特例;
关于软链接小总结:
最就算我们/etc/hadoop文件不见,我们还有备份的hadoop_pseudo,我们创建一个软链接:ln -s hadoop_pseudo hadoop
指向原先失去的hadoop,同样对我们开启服务没有影响,不用指定--config的路径了。
也许在以后,我们要用的配置项不一定是原先的/etc/hadoop文件,或许是hadoop_pseuso等其他配置文 件,这下,可以利用软链接去指向我们想配置的的哪个配置文件。只需要改下软链接,不用再麻烦修改其他配置文件或环境变量参数了。