GloVe: Global Vectors for Word Representation
J. Pennington, R. Socher, C. D. Manning, GloVe: Global Vectors for Word Representation, EMNLP (2014)
摘要
现有单词向量空间表示学习(learning vector space representations of words)通过向量运算(vector arithmetic)获取精细语义和语法规则(fine-grained semantic and syntactic regularities),但这些规则可解释性很差(these regularities has remained opaque)。
本文对能够生成融合语义、语法规则词向量的模型所需属性进行分析(analyze and make explicit the model properties needed for such regularities to emerge in word vectors),得到全局对数双线性回归模型(global log-bilinear regression model)。该模型兼具全局矩阵分解(global matrix factorization)和局部上下文窗口方法(local context window methods)的优点。
本文模型训练只使用词-词共现矩阵中的非零元素(efficiently leverages statistical information by training only on the nonzero elements in a word-word co-occurrence matrix),模型生成的词向量空间具有语义结构(a vector space with meaningful substructure)。
1 引言
语义向量空间模型使用实值向量表示词条(semantic vector space models of language represent each word with a real-valued vector)。
词表示质量评价方法:词向量对之间的距离或角度(most word vector methods rely on the distance or angle between pairs of word vectors as the primary method for evaluating the intrinsic quality of such a set of word representations)
词向量(word vectors)的学习方法:(1)全局矩阵分解(global matrix factorization methods),如隐含语义分析(latent semantic analysis,LSA);(2)局部上下文窗口(local context window methods),如skip-gram。
全局矩阵分解能够充分利用统计信息(leverage statistical information),但在词类比任务(the word analogy task)上表现较差,即其向量空间结构非最优(a sub-optimal vector space structure);局部上下文窗口在词类比任务表现更好,但却忽视了语料库(corpus)的统计信息(poorly utilize the statistics of the corpus since they train on separate local context windows instead of on global co-occurrence counts)
2 相关工作
矩阵分解(Matrix Factorization Methods):分解语料库统计信息矩阵(decompose large matrices that capture statistical information about a corpus),使用低秩近似(low-rank approximations)生成维单词表示(generating low-dimensional word representations)。
语料库统计信息矩阵组织形式分为:(1)词条-文档(term-document)类型,行对应词条、列对应文档(the rows correspond to words or terms, and the columns correspond to different documents in the corpus);(2)词条-词条(term-term)类型,行、列均对应词条,矩阵元素对应给定词在目标词上下文中出现的频次(the rows and columns correspond to words and the entries correspond to the number of times a given word occurs in the context of another given word)。
局部窗口(Shallow Window-Based Methods):学习在局部上下文窗口中预测的词表示(learn word representations that aid in making predictions within local context windows),如skip-gram和CBOW(continuous bag-of-words)、vLBL和ivLBL(closely-related vector log-bilinear models)。
skip-gram、ivLBL模型的目标为根据给定词预测上下文(predict a word’s context given the word itself);CBOW、vLBL模型的目标为根据上下文预测给定词(predict a word given its context)。
3 GloVe模型
语料库中词频统计信息(statistics of word occurrences in a corpus)是非监督单词表示学习(unsupervised methods for learning word representations)的主要信息源(source of information available),其核心问题在于:(1)如何根据统计信息生成词义(how meaning is generated from these statistics);(2)词向量如何表示词义(how the resulting word vectors might represent that meaning)。
GloVe模型:语料库全局统计信息(the global corpus statistics)词向量模型。
:词条共现矩阵(the matrix of word-word co-occurrence counts), :词条 出现在词条 的上下文中的次数, , 表示词条 出现在词条 的上下文中的概率(the probability that word appear in the context of word )。

由表(1)可知,使用共现概率比(ratios of co-occurrence probabilities)学习词向量应优于单纯使用概率,即
其中, 表示词向量、 表示上下文词向量(context word vectors)
-
函数 应对词向量空间(the word vector space)中表示比值 的信息编码(information present the ratio ),由于向量空间是线性的(vector spaces are inherently linear structures),因此可采用向量差形式(vector differences),
-
由于方程(2)的右端为标量(a scalar),因此函数 可采用点积形式(take the dot product of the arguments)
-
由于词条共现矩阵中的目标词条与上下文词条是任意的,即可相互交换(for word-word co-occurrence matrices, the distinction between a word and a context word is arbitrary and that we are free to exchange the two roles), 、 。假设函数 为群 与 间的同态(a homomorphism between the groups and ),即,
根据方程(3)有
满足方程(4),即
-
方程(6)不满足交换对称性(exchange symmetry),因此为 添加偏置项 ,
零输入会导致对数(logarithm)发散(diverge),因此方程(7)是病态的(ill-defined),可通过在对数项中添加偏移解决, 。
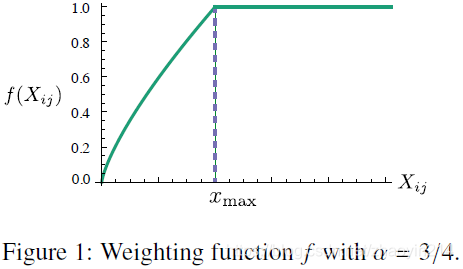
该模型的主要缺点为:所有共现权值相同(it weighs all co-occurrences equally),而稀有共现通常为噪声且信息量极小(rare co-occurrences are noisy and carry less information than the more frequent ones)。本文进而提出加权最小二乘回归模型(a weighted least squares regression model)。在损失函数(cost function)中,引入权值函数(a weighting function) ,
其中, 表示词典大小(the size of the vocabulary)。权值函数需满足:
-
,以保证 有界(finite);
-
非减(non-decreasing),以保证稀有共现(rare co-occurrences)不会被过度加权(overweighted);
-
很大时, 不应过大,以保证频繁共现(frequent co-occurrences)不会被过度加权。
本文中, , 。
3.1 与现有模型的关系(relationship to other models)
3.2 模型复杂度(complexity of the model)
4 实验
4.1 评估方法(evaluation methods)
单词类比(word analogies)
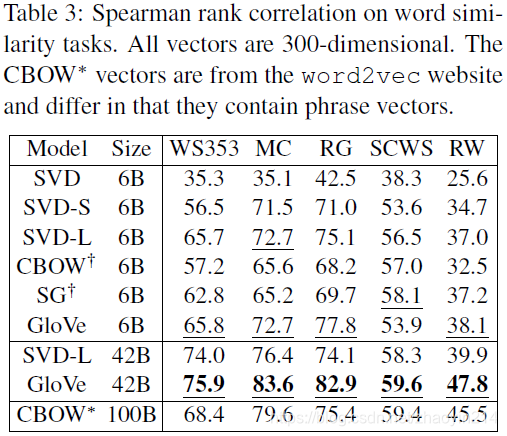
单词相似度(word similarity)
命名实体识别(named entity recognition)
4.2 语料库及训练细节(corpora and training details)
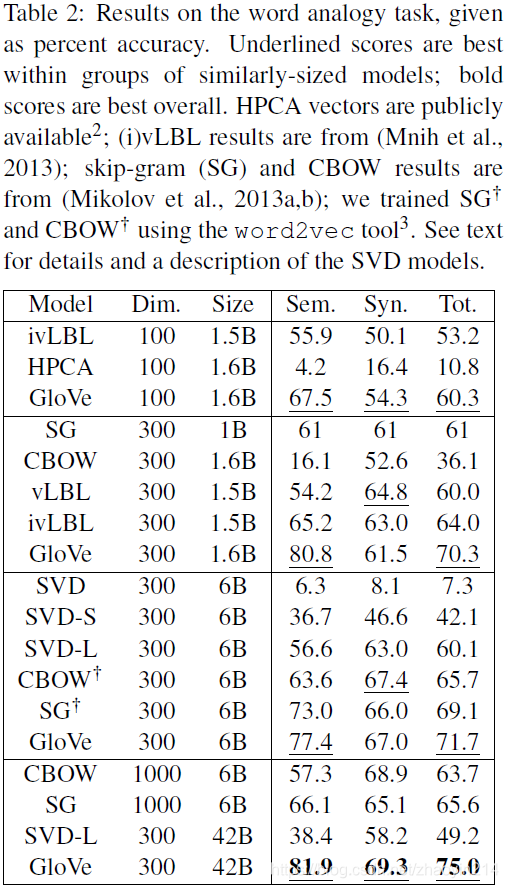
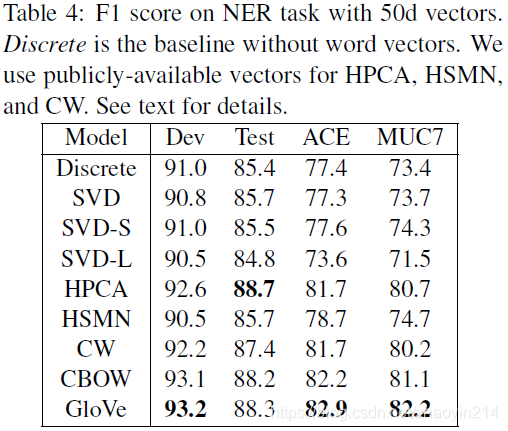
4.3 结果
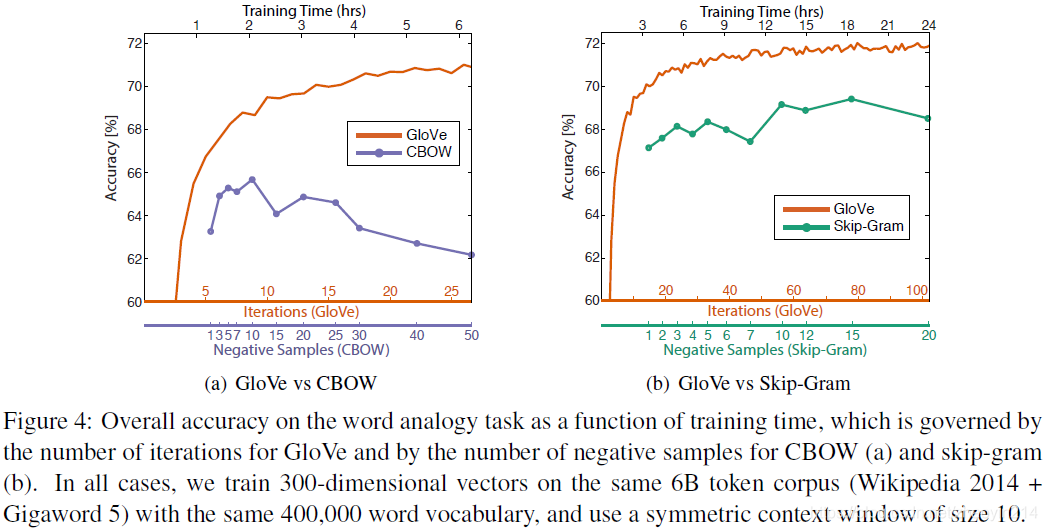
4.4 模型分析:向量长度、上下文范围(model analysis: vector length and context size)
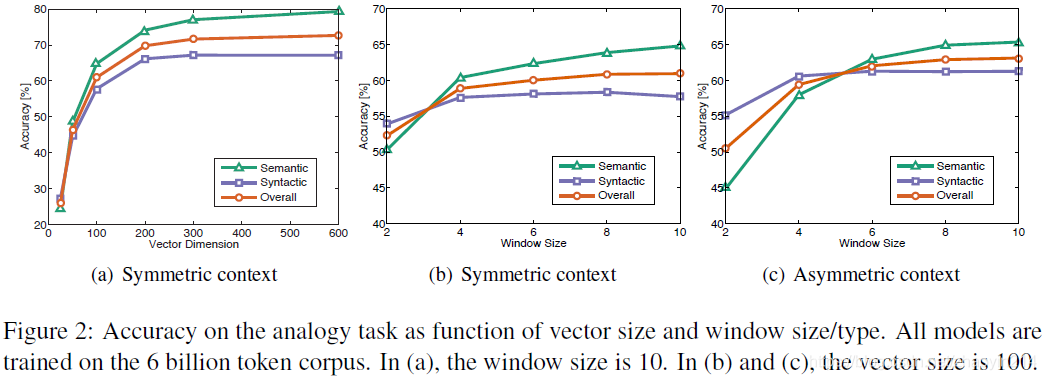
对称上下文窗口(a symmetric context window):目标词(a target word)位于窗口中间
非对称上下文窗口(an asymmetric context window):目标词(a target word)位于窗口右侧(a context window that extends only to the left of a target word)
非对称小尺寸上下文窗口在语法任务(syntactic subtask)上表现较好,其原因在于语法信息(syntactic information)主要源自(mostly drawn from)直接上下文(immediate context)且与词序(word order)强相关;而语义信息(semantic information)通常是全局的(more frequently non-local),需要较大尺寸的窗口捕获。
4.5 模型分析:语料库规模(model analysis: corpus size)
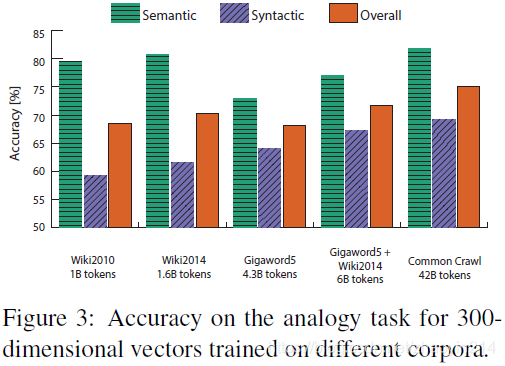
在语法任务上,模型表现随语料库规模增加而单调增加(a monotonic increase in performance as the corpus size increases),其原因在于大规模语料库能够生成更好的统计(better statistics)
在语义任务上,模型表现与语料库规模并非强相关,主要取决于语料库质量(the large number of city- and country- based analogies in the analogy dataset and the fact that Wikipedia has fairly comprehensive articles for most such locations)
4.6 模型分析:运行时间(model analysis: run-time)