什么是Hive?
hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言‘查询、汇总和分析数据。而mapreduce开发人员可以把自己写的mapper和reducer作为插件来支持hive做更复杂的数据分析。它与关系型数据库的SQL略有不同,但支持了绝大多数的语句如DDL、DML以及常见的聚合函数、连接查询、条件查询。它还提供了一系列的操作:进行数据提取转化加载,用来存储、查询和分析存储在Hadoop中的大规模数据集,并支持UDF(User-Defined Function)、UDAF(User-Defnes AggregateFunction)和USTF(User-Defined Table-Generating Function),也可以实现对map和reduce函数的定制,为数据操作提供了良好的伸缩性和可扩展性。
hive不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。hive的特点包括:可伸缩(在Hadoop的集群上动态添加设备)、可扩展、容错、输入格式的松散耦合。
Hive的由来
-
MapReduce编程带来的不便性
MapReduce编程十分繁琐,在大多情况下,每个MapReduce程序需要包含Mapper、Reduceer和一个Driver,之后需要打成jar包扔到集群上运 行。如果mr写完之后,且该项目已经上线,一旦业务逻辑发生了改变,可能就会带来大规模的改动代码,然后重新打包,发布,非常麻烦(这种方式,也是最古老的方式) -
当大量数据都存放在HDFS上,如何快速的对HDFS上的文件进行统计分析操作?
一般来说,想要做会有两种方式:
1).学Java、学MapReduce(十分麻烦)2).做DBA的:写SQL(希望能通过写SQL这样的方式来实现,这种方式较好),然而,HDFS中最关键的一点就是,数据存储HDFS上是没有schema的概念的 (schema:相当于表里面有列、字段、字段名称、字段与字段之间的分隔符等,这些就是schema信息) ,然而HDFS上的仅仅只是一个纯的文本文件而已 那么,没有schema,就没办法使用sql进行查询 。
为了让非Java编程者也能做MapReduce操作,Hive应运而生。
Hive架构
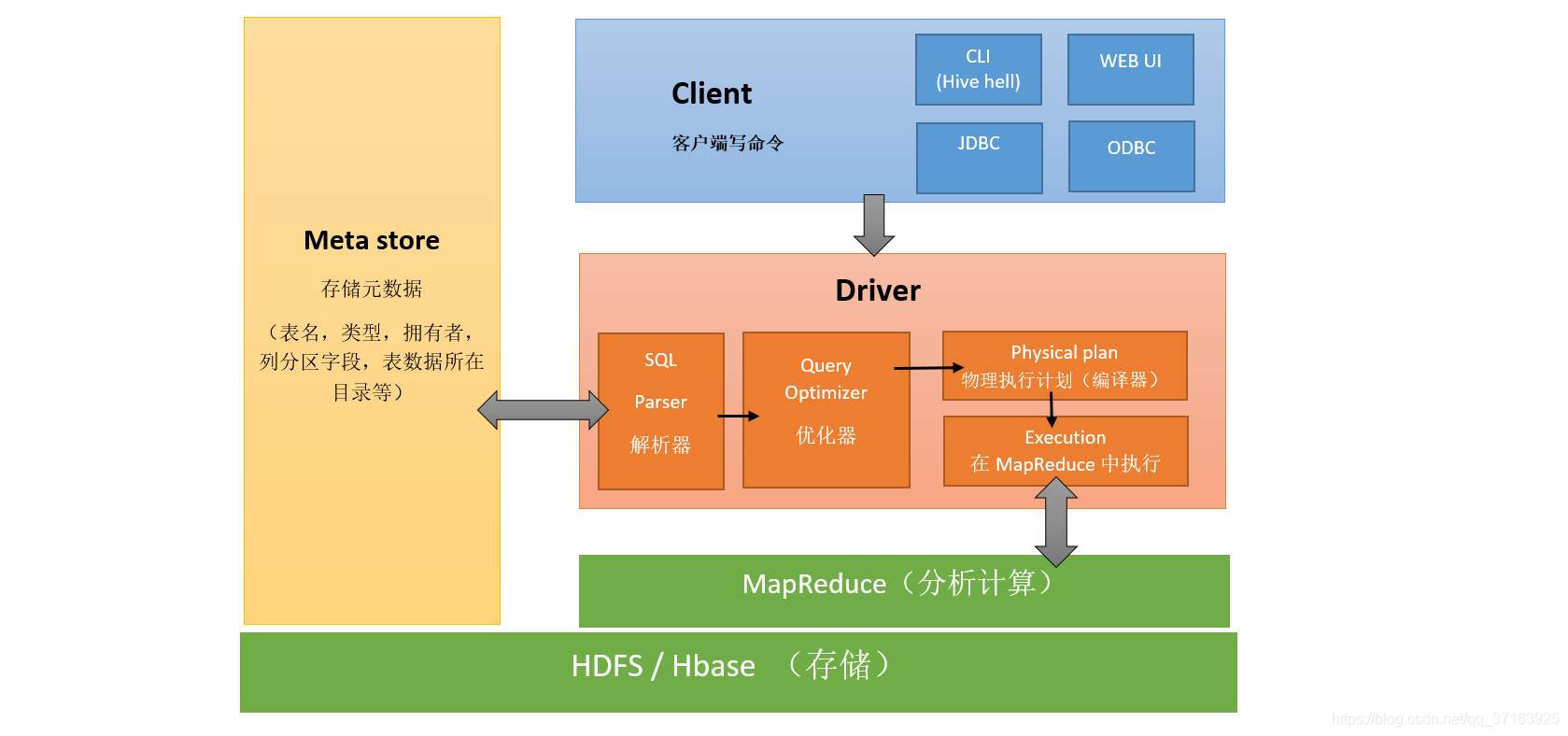
Hive的架构中主要包含以下几个角色。
-
用户接口
用户接口主要有三个:CLI(Command line interface),WUI(web UI)和JDBC/ODBC。其中最常用的是 Cli,Cli 启动的时候,会同时启动一个 hive 副本。Client 是 Hive 的客户端,用户连接至 hive Server。在启动 Client 模式的时候,需要指出 hive Server 所在节点,并且在该节点启动 Hive Server。JDBC/ODBC是Hive连接Hive Server的驱动程序,客户端可以通过这些程序去访问Hive Server。 WUI 是Hive提供的管理页面(类似于hdfs的50070,yarn的8088),通过浏览器访问 hive,值得一提的是,在2.2版本之后,WebUI已经被淘汰掉了(界面不美观,实用性低)。
-
元数据存储
hive 将元数据存储在数据库中,如 mysql、derby。hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
-
Driver
Driver中主要包含了解释器、编译器、优化器、执行器四个组件,它们共同完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
-
HBase/HDFS
用于存储Hive的数据以及在Driver端生成的查询计划。也可用于存储Hive的外部表。
Hive存储模型
hive中包含以下四类数据模型:内部表(Table)、外部表(External Table)、分区(Partition)、桶(Bucket)。
-
内部表(Table)
hive中的Table和数据库中的Table在概念上是类似的。在hive中每一个Table都有一个相应的目录存储数据。创建普通表的操作分为两个步骤,即表的创建步骤和数据装入步骤(可以分开也可以同时完成)。在数据的装入过程中,实际数据会移动到数据表所在的hive数据仓库文件目录中,其后对该数据表的访问将直接访问装入所对应文件目录中的数据。删除内部表时,该表的元数据和在数据仓库目录下的实际数据将同时删除。
-
外部表(External Table)
外部表是一个已经存储在HDFS中,并具有一定格式的数据。使用外部表意味着hive表内的数据不在hive的数据仓库内,它会到仓库目录以外的位置访问数据。外部表的创建只有一个步骤,创建表和装人数据同时完成。外部表的实际数据存储在创建语句LOCATION参数指定的外部HDFS文件路径中,但这个数据并不会移动到hive数据仓库的文件目录中。删除外部表时,仅删除其元数据,保存在外部HDFS文件目录中的数据不会被删除。
-
分区(Partition)
分区对应于数据库中的分区列的密集索引,但是hive中分区的组织方式和数据库中的很不相同。在hive中,表中的一个分区对应于表下的一个目录,所有的分区的数据都存储在对应的目录中。
-
桶(Bucket)
桶对指定列进行哈希(hash)计算,会根据哈希值切分数据,目的是为了并行,每一个桶对应一个文件。
Hive 执行计划
Hive的执行计划主要分为7个阶段。
-
parser:进来一个SQL字符串,将SQL解析,解析的结果是AST(抽象语法树见官网详细解释以及使用),会进行语法校验,AST本质还是字符串。
-
Analyzer:语法分析,这里面还要去Meta Info里面关联查找校验,比如表存不存在、字段对不对等。然后生成QB(query block)。
-
Logicl Plan:逻辑执行计划解析,进来是QB,生成一堆Opertator Tree(操作,比如select)。
-
Logicl Optimizer:进行逻辑执行计划优化,生成的还是一堆Opertator Tree。
-
Phsical plan:物理执行计划解析,生成 tasktree。
-
Phsical Optimizer:进行物理执行计划优化,生成tasktree。
-
生成TaskTree:根据类别比如,是Hive SQL还是SparkSQL还是其它的,会各自提交到集群上去运行
Hive 搭建
Hive搭建可以参考这篇文章,里面详细介绍了Hive安装与配置说明。
