我们先来接受几个概念:
质数分解定律,任何一个数都可以分解为几个不同素数额乘积P1,P2,P3...到Pn;
质数分辨定理:
定理一:
我们选择n个互不相同的素数p1,p2,p3,p4,p5,....pn;我们定义:
M=p1*p2*p3*...*pn,m<k1<k2<=m+M,则,对于任意一个pi,(k1 mod Pi)=(k2 mod Pi)总成立;
我们来简单的正面一下,
设K=k1-k2;如果(k1 mod pi)=(k2 mod pi) 恒成立,则存在K%pi==0恒成立,所以K=M*s(s>=1)与结论不符
余数分辨定理:
定理2,选取任意n个互不相同的自然数:I1,I2,I3,I4,I5...In;定义LCM为他们的最小公倍数,则存在m<k1<k2<=m+M,则,对于任意一个pi,(k1 mod Pi)=(k2 mod Pi)总成立;这个证明过程模仿定理一。
我们通过分辨定理可以分辨M个连续的数。

分辨算法的评价标准:
状态和特征:
分辨也即分辨不同的状态。分辨一般是先定义一组不同的状态,然后将这些状态记录下来形成特征。由这些特征所形成的空间是特征空间。特征空间的维度就是特征数列的长度。
2.分辨能力:
分辨能力D,也成分辨范围,就是可以分辨多少个连续的状态。在这个范围内,不存在完全相同的特征数。这些信息既可以用数列记录下来,也可以通过数据结构记录下来。
3.冲突概率:
对于任意一个数,他可能是D范围内的任意一种状态,所以冲突的概率为 k=1/D<=1,当D越大,冲突的概率越小。
4.分辨效率
我 们可以定义分辨效率G=(分辨能力)/(所有特征数的成积)=LCM/M;
由定理1和2可知,当余数分辨定理的一系列整数互质时G=1,如果有两个数存在公约数则G<1;
我们可以对一直数列进行处理,让他G=1,如果Ik,IJ的最大公约数为GCD,则我们可以用(Ik/GCD) 和Ij代替原来的数,使他分辨效率变高。
5.简化度 H
我们定义H=1/(特征数之和),特征数之和越小简化度越高。
综合评价指数:
Q=D*H/特征维度。
我们
哈希树的组织结构:
使用不同的分辨算法可以组织不同的哈希树,一般来说,每一个哈希树的节点下的子节点数是和分辨数列一致的。哈希树的最大深度就是特征空间的维度。
为了方便研究我们用质数分辨算法建立一颗哈希树。第一层位给节点,根节点下有2个节点;第二层的每一个节点下有3个节点;以此例推,即每层节点的子节点的数目为连续的素数。单量地市层每个节点下面有29个节点(2-29有10个连续的素数)。
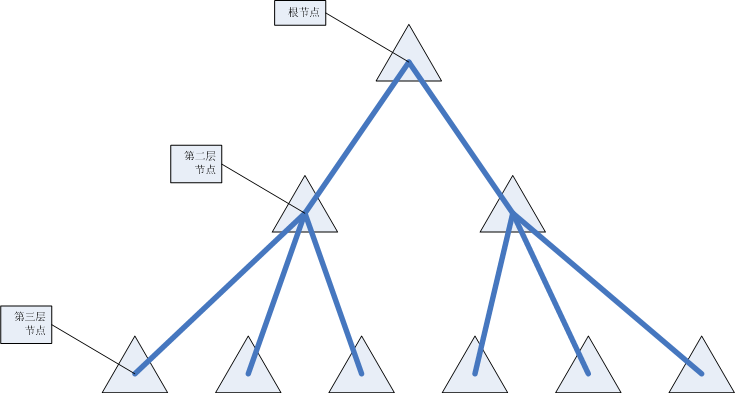
1.设置几个参数,prime数列,0位2,level层数,0,层位根节点;
2.如果当前的位置没有被占领,我们改变这个节点的key和value 然后标记为true
3.如果当前的节点被占领了,我们就模这一层的prime[level],如果这个节点不存在,我们就往下建一个节点然后到下一层去比较。
4.比较两个数不同的标准是特征编码是否相同(长度和内容)
1 #include<iostream> 2 hashnode 的结构 3 首先要key 和value值, 4 还要申请子节点的个数的地址值,初始化为NULL,noise[] 5 该节点是否被占领 occupied 6 void insert(HashNode entry int level, int key,int value) 7 { 8 if(this.occupied==false) 9 { 10 this->key=key; 11 this->value=value; 12 this->occupied=true; 13 return; 14 } 15 int index=key%prime[level]; 16 if(node[index]==NULL) 17 { 18 nodes[index]=new hashNode(); 19 } 20 level+=1; 21 insert(nodes[index],level,key,value); 22 }
查找操作:
1.如果当前节点没有被占领,执行第五步;
2.如果当前节点已经被占领,比较key的值;
3.如果关键值相同,返回value;
4.如果不等,执行第五步
5.计算index=key%prime[level];
6.如果nodes[index]=NULL,返回查找失败;
7.如果nodes[index]为一个已经存在的子节点,我们递归下去往下找,重复第一步操作
1 伪代码; 2 int find(HashNode entry,int level,int key/*,int value*/) 3 { 4 if(this->occupied==true) 5 { 6 if(this->key==key) 7 return this->value 8 } 9 int index=key%prime[level++]; 10 //level+=1; 11 if(nodes[index]==NULL) 12 return fail; 13 return find(nodes[index],level,key); 14 }
1.如果当前节点没有被占领,执行第五步;
2.如果当前节点已经被占领,比较key的值;
3.如果关键值相同,将这一步设为为占领occupied=false;//在找到的基础上可以选择设为false,我们也可以选择直接删除这个节点,然后将这个指针设为空,同时我们也可以选择返回查找的地址
4.如果不等,执行第五步
5.计算index=key%prime[level];
6.如果nodes[index]=NULL,返回查找失败;
7.如果nodes[index]为一个已经存在的子节点,我们递归下去往下找,重复第一步操作
1 RemoveNode(HashNode entry,int level,int key) 2 { 3 if(this->occupied==true) 4 { 5 if(this->key==key) 6 { 7 this->occpuied=false; 8 return ; 9 //delete this; 10 //this=NUll 11 //return; 12 } 13 int index=key MOD prime[level++] 14 //level+=1; 15 if(nodes[index]==NULL) 16 return fail; 17 /*return*/ RemoveNode(nodes[index],int level,int key); 18 } 19 }
hashtree的特点,每次查找的复杂度为lg,而且合理利用指针可以避免不必要的空间浪费
初始化树需要时间nlogn,没有必要建齐整棵树
操作简单
查找迅速
结构不变,不会退化成链表
哈希数的退化问题;
面对相同的数我们可以增加节点的信息,time代表出现的次数;
同时这两个数相差k*D,我么就可以继续往下建一层一般不会数据报表的大
字符串关键字hash化;
我们mod两个比较大的质数就,D=s1*s2;(数据不太大无敌)