代码 https://github.com/backstopmedia/tensorflowbook.git
1、监督学习简介
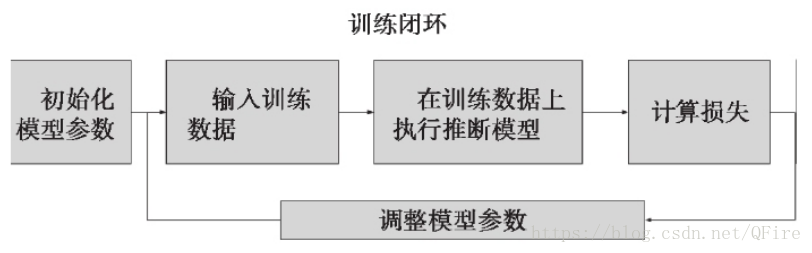
数据流图的高层、通用训练闭环:一种常用的方法是将原始数据集一分为二,将70%的样本用于训练,30%用于评估。
2、保存训练检查点
防止突然断电
3、 线性回归
目标是找到一个与这些数据最为吻合的线性函数
y(x1, x2, ... , xk) = w1*x1 + w2*x2 + ... + wk * xk + b
其矩阵(或张量)形式为
Y = X*W^T + b, 其中X=(x1, x2, ... , xk) , W = (w1, w2, ... , wk)
如何计算损失:总平方误差
loss = Sum(Y - Y_predicted)^2
def loss(X, Y):
Y_prediected = inference(X)
return tf.reduce_sum(tf.squared_difference(Y, Y_predicted))
数据集http://people.sc.fsu.edu/~jburkardt/datasets/regression/x09.txt
import tensorflow as tf
W = tf.Variable(tf.zeros([2,1]), name="weights")
b = tf.Variable(0., name="bias")
def inference(X): #计算推断模型的数据X上的输出
return tf.matmul(X, W) + b
def loss(X, Y):
Y_predicted = inference(X)
return tf.reduce_sum(tf.squared_difference(Y, Y_predicted))
def inputs():
weight_age = [ [84,46],[73,20],[65,52],[70,30],[76,57],
[69,25],[63,28],[72,36],[79,57],[75,44],
[27,24],[89,31],[65,52],[57,23],[59,60],
[69,48],[60,34],[79,51],[75,50],[82,34],
[59,46],[67,23],[85,37],[55,40],[63,30] ]
blood_fat_content = [354, 190, 405, 263, 451, 302, 288,
385, 402, 365, 209, 290, 346, 254,
395, 434, 220, 374, 308, 220, 311,
181, 274, 303, 244]
return tf.to_float(weight_age), tf.to_float(blood_fat_content)
def train(total_loss):
learning_rate = 0.0000001
return tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
def evaluate(sess, X, Y):
print sess.run(inference([[80., 25.]])) # ~ 303
print sess.run(inference([[65., 25.]])) # ~ 256
saver = tf.train.Saver()
with tf.Session() as sess:
tf.initialize_all_variables().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
training_steps = 1000
for step in range(training_steps):
sess.run([train_op])
if step % 10 == 0:
print "loss: ", sess.run([total_loss])
#saver.save(sess, 'my-model', global_step=step)
evaluate(sess, X, Y)
coord.request_stop()
coord.join(threads)
saver.save(sess, 'my-model', global_step=training_steps)
sess.close()
4、对数几率回归
sigmoid函数,能够回答Yes-No类型的问题(是否为垃圾邮件)
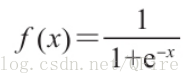
损失函数:logistic函数会计算回答为"Yes"的概率,损失是模型为那个样本所分配的概率值,并取平方。
采用交叉熵(cross entropy)损失函数会更为有效:输出与期望越接近,熵会越小。

数据集https://www.kaggle.com/c/titanic/data
import tensorflow as tf
import os
W = tf.Variable(tf.zeros([5, 1]), name="weights")
b = tf.Variable(0., name="bias")
def combine_inputs(X):
return tf.matmul(X, W) + b
def inference(X):
return tf.sigmoid(combine_inputs(X))
def loss(X, Y):
return tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=combine_inputs(X), labels=Y))
def read_csv(batch_size, file_name, record_defaults):
filename_queue = tf.train.string_input_producer([os.path.join(os.getcwd(), file_name)])
reader = tf.TextLineReader(skip_header_lines=1)
key, value = reader.read(filename_queue)
decoded = tf.decode_csv(value, record_defaults=record_defaults)
return tf.train.shuffle_batch(decoded, batch_size=batch_size,
capacity=batch_size*50, min_after_dequeue=batch_size)
def inputs():
passenger_id, survived, pclass, name, sex, age, sibsp, parch, ticket, fare, cabin, embarked = \
read_csv(100, "train.csv", [[0.0], [0.0], [0], [""], [""], [0.0], [0.0], [0.0], [""], [0.0], [""], [""]])
is_first_class = tf.to_float(tf.equal(pclass, [1]))
is_second_class = tf.to_float(tf.equal(pclass, [2]))
is_third_class = tf.to_float(tf.equal(pclass, [3]))
gender = tf.to_float(tf.equal(sex, ["female"]))
features = tf.transpose(tf.stack([is_first_class, is_second_class, is_third_class, gender, age]))
survived = tf.reshape(survived, [100, 1])
return features, survived
def train(total_loss):
learning_rate = 0.01
return tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
def evaluate(sess, X, Y):
predicted = tf.cast(inference(X) > 0.5, tf.float32)
print sess.run(tf.reduce_mean(tf.cast(tf.equal(predicted, Y), tf.float32)))
with tf.Session() as sess:
tf.initialize_all_variables().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
training_steps = 1000
for step in range(training_steps):
sess.run([train_op])
if step % 10 == 0:
print "loss: ", sess.run([total_loss])
evaluate(sess, X, Y)
import time
time.sleep(5)
coord.request_stop()
coord.join(threads)
sess.close()
5、softmax分类
希望能够回答具有多个选项的问题,使用softmax
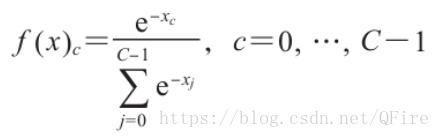
数据集https://archive.ics.uci.edu/ml/datasets/Iris,包含4个特征及3个可能的输出类
import tensorflow as tf
import os
import os.path
import sys
W = tf.Variable(tf.zeros([4,3]), name="weights")
b = tf.Variable(tf.zeros([3]), name="bias")
def combine_inputs(X):
return tf.matmul(X, W) + b
def inference(X):
return tf.sigmoid(combine_inputs(X))
def loss(X, Y):
return tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=combine_inputs(X), labels=Y))
def read_csv(batch_size, file_name, record_defaults):
filename_queue = tf.train.string_input_producer([os.path.dirname(os.path.abspath(sys.argv[0])) + "/" + file_name])
reader = tf.TextLineReader(skip_header_lines=1)
key, value = reader.read(filename_queue)
decoded = tf.decode_csv(value, record_defaults=record_defaults)
return tf.train.shuffle_batch(decoded,
batch_size=batch_size,
capacity=batch_size*50,
min_after_dequeue=batch_size)
def inputs():
sepal_length, sepal_width, petal_length, petal_width, label = \
read_csv(100, "iris.data", [[0.0], [0.0], [0.0], [0.0], [""]])
label_number = tf.to_int32(tf.argmax(tf.to_int32(tf.stack([
tf.equal(label, ["Iris-setosa"]),
tf.equal(label, ["Iris-versicolor"]),
tf.equal(label, ["Iris-virginica"]),
]))))
print(sepal_length)
features = tf.transpose(tf.stack([sepal_length, sepal_width, petal_length, petal_width]))
return features, label_number
def train(total_loss):
learning_rate = 0.01
return tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
def evaluate(sess, X, Y):
predicted = tf.cast(tf.arg_max(inference(X), 1), tf.float32)
print sess.run(tf.reduce_mean(tf.cast(tf.equal(predicted, Y), tf.float32)))
with tf.Session() as sess:
tf.initialize_all_variables().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
training_steps = 1000
for step in range(training_steps):
sess.run([train_op])
if step % 10 == 0:
print "loss: ", sess.run([total_loss])
evaluate(sess, X, Y)
import time
time.sleep(5)
coord.request_stop()
coord.join(threads)
sess.close()
6、多层神经网络
线性回归模型和对数几率回归模型本质上多是单个神经元,输入加权和,激活函数(恒等式或sigmoid)
对于softmax分类,为含C个神经元的网络
异或运算的网络
7、梯度下降法与误差反向传播算法
寻找损失函数的极值点。用tf.gradients方法
BP是一种高效计算数据流图中梯度的技术