用过滤法对以下数据进行特征选择:
[[0,2,0,3],
[0,1,4,3],
[0,1,1,3]]
要求:
1、Variance Threshold(threshold =1.0)
2、将结果截图放上来(没有条件的备注说明原因)注意:每个人的电脑ID是不一样的


# 非监督:降维:减少要考虑的特征数量,维度就相当于特征 # 两种:1、特征选择、2、主成分分析 # 1、特征选择,包括:A过滤式 B嵌入式 优中选优,在选出来的数据特征中找到更好的数据特征 # A过滤式:删除低方差特征 # B嵌入式:正则化、决策树、神经网络
# 解析作业要求:用过滤式方法减少要考虑的特征
# 步骤:找到其特征中方差较低的特征,原因:这样的特征的数据值差不多,会造成数据冗余或者对数据预测结果有影响
# threshold可以取0-9之内的数
# 库和模型:sklearn.feature_selection.VarianceThreshold 删除低方差特征
# 流程:初始化->赋值->调用fit_transform
from sklearn.feature_selection import VarianceThreshold import numpy as np def var(): data=[[0,2,0,3], [0,1,4,3], [0,1,1,3]] print("原样本数据:",data) var=VarianceThreshold(threshold=1.0) #初始化+指定阈值方差,方差<1就会被删掉 data_fit=var.fit_transform(data) print("过滤式选择特征后数据\n",data_fit) return None if __name__=="__main__": var()
运行结果:

验证其方差小于1的特征是否真的被删除了
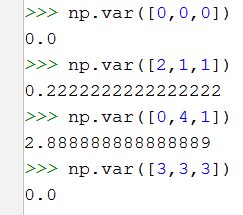
从上图可知:除了第三列的特征值的方差大于1之外,其他的都小于1,所以最后小于1的被删除了,大于1的被留下了。