广度优先遍历(BFS)
图的广度优先遍历可定义如下:首先访问出发点v,并将其标记为已访问过;然后从v出发依次访问v的每个未被访问的邻接点w。当v的所有邻接点全部访问完后,再对v的每个邻接点w继续进行广度优先遍历,直至图中所有和源点v有路径相通的顶点均已被访问为止。若此时图中仍有未访问的顶点,则另选一个尚未访问的顶点为新的源点重复上述过程,直至图中所有的顶点均已被访问为止。
如下代码只考虑无向连通图,即图中任意两个顶点均有路径相连。同时由于图的广度优先遍历不唯一,以下代码对于多邻点的顶点的遍历,按顶点值由低到高进行广度优先遍历。
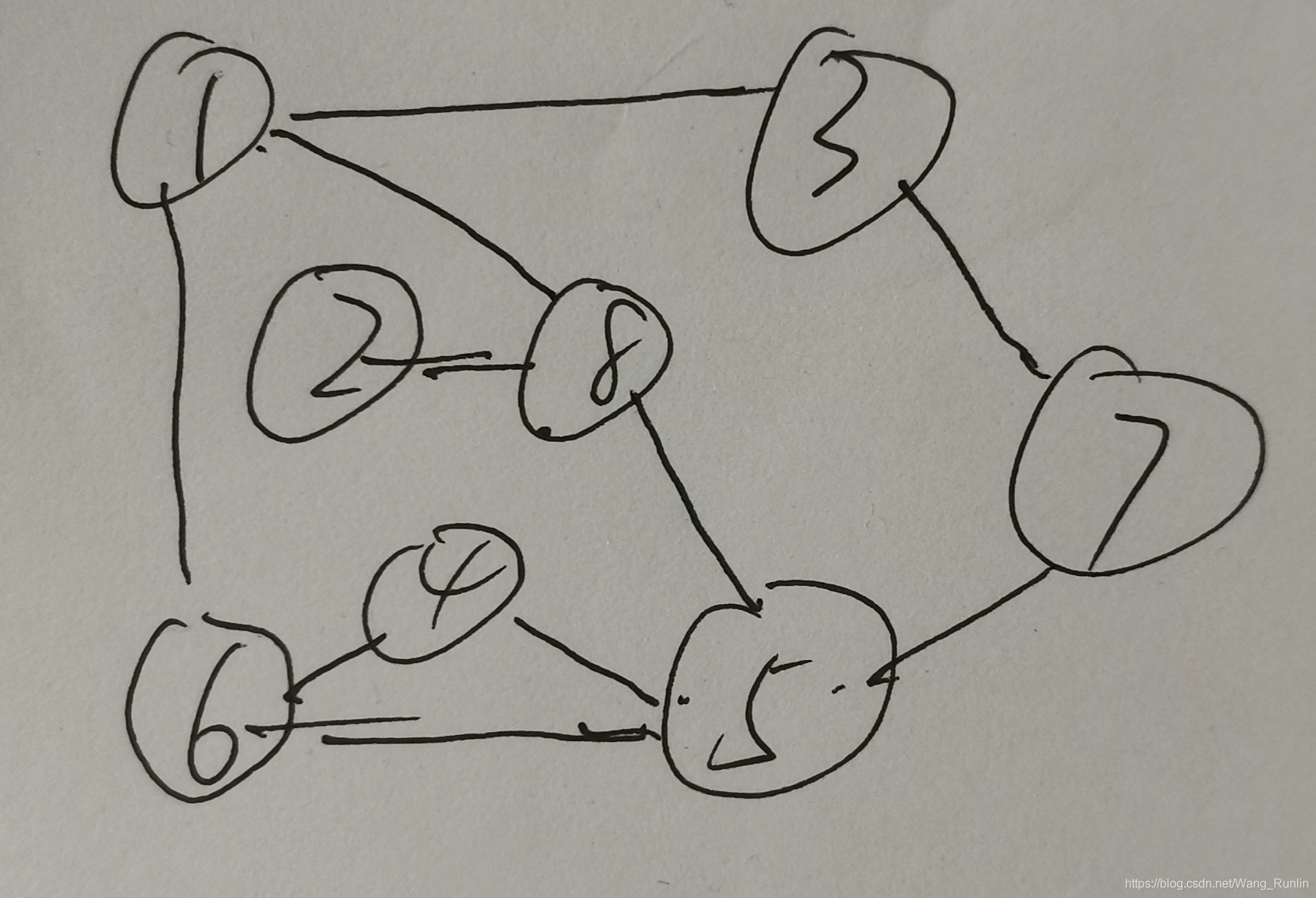
代码运行后,第一行输入图的顶点总数目n,顶点依次编号为1,2…n,顶点编号即对应顶点值;第二行输入图的总边数m,接下来m行输入每条边的两个顶点,以逗号分隔;最后输入遍历的始发顶点编号x。比如:下图输入顶点数8(对应的顶点为1~8),边数10和边集,始发顶点为8,得到的广度优先遍历的结果为:8 1 2 5 3 6 4 7。 程序输出广度遍历结果(空格隔开)
class Graph(object):
def __init__(self,*args,**kwargs):
self.node_neighbors = {} # 定义顶点与邻接顶点集为字典结构
self.visited = {} # 定义已访问顶点集为字典结构
def add_nodes(self,nodelist):
for node in nodelist:
self.add_node(node)
def add_node(self,node):
if not node in self.nodes():
self.node_neighbors[node] = []
def add_edge(self,edge):
u,v = edge
if(v not in self.node_neighbors[u]) and ( u not in self.node_neighbors[v]): # 此处可添加自己指向自己的边
self.node_neighbors[u].append(v)
if(u!=v):
self.node_neighbors[v].append(u)
def nodes(self):
return self.node_neighbors.keys()
def breadth_first_search(self,root=None): # 广度优先需用到队列结构
queue = []
order = []
def bfs():
while len(queue)> 0:
node = queue.pop(0)
self.visited[node] = True
self.node_neighbors[node].sort()
for n in self.node_neighbors[node]:
if (not n in self.visited) and (not n in queue):
queue.append(n)
order.append(n)
if root:
queue.append(root)
order.append(root)
bfs()
for node in self.nodes():
if not node in self.visited:
queue.append(node)
order.append(node)
bfs()
# print(order)
return order
if __name__ == '__main__':
g = Graph()
node_num=int(input())#顶点的数目
g.add_nodes([i+1 for i in range(node_num)])
vec_num=int(input())#边的数目
for i in range(vec_num):
g.add_edge(tuple(int(n) for n in input().split(',')))
order = g.breadth_first_search(int(input()))
# print(order)
for i in order:
print(i, end=' ')
测试结果:

深度优先遍历(DFS)
图的深度优先遍历可定义如下:首先访问出发点v,并将其标记为已访问过;然后依次从v出发搜索v的每个邻接点w。若w未曾访问过,则以w为新的出发点继续进行深度优先遍历,直至图中所有和源点v有路径相通的顶点均已被访问为止。若此时图中仍有未访问的顶点,则另选一个尚未访问的顶点为新的源点重复上述过程,直至图中所有的顶点均已被访问为止。请编写程序实现图的深度优先遍历,从节点1开始。同时由于图的深度优先遍历不唯一,我们约定对于多邻点的顶点的遍历,按顶点值由低到高进行深度优先遍历。
第一行输入图的顶点的数目;第二行输入图的边数;接下来逐行输入边。
比如:下图(还是上面那个图)输入顶点数8(对应的顶点为1~8),边数10和边集,得到的深度优先遍历的结果为:1 3 7 5 4 6 8 2
class Graph(object):
def __init__(self,*args,**kwargs):
self.node_neighbors = {}
self.visited = {}
def add_nodes(self,nodelist):
for node in nodelist:
self.add_node(node)
def add_node(self,node):
if not node in self.nodes():
self.node_neighbors[node] = []
def add_edge(self,edge):
u,v = edge
if(v not in self.node_neighbors[u]) and ( u not in self.node_neighbors[v]):
self.node_neighbors[u].append(v)
if(u!=v):
self.node_neighbors[v].append(u)
def nodes(self):
return self.node_neighbors.keys()
def depth_first_search(self,root=None):
order = []
def dfs(node):
self.visited[node] = True
order.append(node)
self.node_neighbors[node].sort()
for n in self.node_neighbors[node]:
if not n in self.visited:
dfs(n)
if root:
dfs(root)
for node in self.nodes():
if not node in self.visited:
dfs(node)
#print(order)
return order
if __name__ == '__main__':
g = Graph()
node_num=int(input())#顶点的数目
#node_c=input().split(',')
#g.add_nodes(i for i in node_c)
g.add_nodes([i+1 for i in range(node_num)])
vec_num=int(input())#边的数目
for i in range(vec_num):
g.add_edge(tuple(int(n) for n in input().split(',')))
#print("nodes:", g.nodes())
order = g.depth_first_search(1)
for i in order:
print(i,end=' ')

最短路径树
计算最短路径树使用邻接矩阵表示较方便。它是指到某个节点路径都是最短的一棵树。下面的代码求所有节点到图的第一个节点构成的最短路径树。最短路径树使用邻接矩阵表示法较方便。第一行是图的节点数n,第二行到第n+1行,是对应的图的邻接矩阵。然后,在一行中输出从所有节点(包含第一个节点自己)到第一个节点的最短路径的长度。
n=int(input())
path_cost=[]
for i in range(n):
path_cost.append(list(map(int,input().split())))
a=[0]+[200000000 for x in range(n-1)]
visit=[False]*n
for i in range(n):
min1=200000000
for j in range(n):
if (not visit[j]) and (a[j]<min1):
min1=a[j]
k=j
visit[k]=True
for j in range(n):
if(not visit[j]) and (a[k]+path_cost[k][j]<a[j]):
a[j]=a[k]+path_cost[k][j]
print(a)
如果两个节点之间不存在边,权重就取一个很大值,姑且输入65535。

最小生成树
一个有n个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有n个结点,并且有保持图连通的最少的边。
而最小生成树便是指该生成树所有边的权值之和是最小的生成树。常用的方法有prim算法和kruskal算法。
这个代码输入第一行为正整数N。(N>0)N为图的节点数,接下来输入一个N行N列的矩阵C,因为是无向图,所以这是一个沿对角线对称的矩阵,矩阵的元素Cij代表从i节点到j节点的花费值。若该条边不存在,则设置数值为65535;输出最小生成树的cost。这里给出了两种算法的函数。
class Graph(object):
def __init__(self, maps):
self.maps = maps
self.nodenum = self.get_nodenum()
self.edgenum = self.get_edgenum()
def get_nodenum(self):
return len(self.maps)
def get_edgenum(self):
count = 0
for i in range(self.nodenum):
for j in range(i):
if self.maps[i][j] > 0 and self.maps[i][j] < 9999:
count += 1
return count
def kruskal(self):
res = []
sum_cost=0
if self.nodenum <= 0 or self.edgenum < self.nodenum-1:
return res
edge_list = []
for i in range(self.nodenum):
for j in range(i,self.nodenum):
if self.maps[i][j] < 9999:
edge_list.append([i, j, self.maps[i][j]])#按[begin, end, weight]形式加入
edge_list.sort(key=lambda a:a[2])#已经排好序的边集合
group = [[i] for i in range(self.nodenum)]
for edge in edge_list:
for i in range(len(group)):
if edge[0] in group[i]:
m = i
if edge[1] in group[i]:
n = i
if m != n:
res.append(edge)
sum_cost +=edge[2]
group[m] = group[m] + group[n]
group[n] = []
#return res
return sum_cost
def prim(self):
sum_cost=0
res = []
if self.nodenum <= 0 or self.edgenum < self.nodenum-1:
return res
res = []
seleted_node = [0]
candidate_node = [i for i in range(1, self.nodenum)]
while len(candidate_node) > 0:
begin, end, minweight= 0, 0, 9999
for i in seleted_node:
for j in candidate_node:
if self.maps[i][j] < minweight:
minweight = self.maps[i][j]
begin = i
end = j
res.append([begin, end, minweight])
sum_cost += minweight
seleted_node.append(end)
candidate_node.remove(end)
return sum_cost
max_value = 65535
'''
row0 = [0,7,max_value,max_value,max_value,5]
row1 = [7,0,9,max_value,3,max_value]
row2 = [max_value,9,0,6,max_value,max_value]
row3 = [max_value,max_value,6,0,8,10]
row4 = [max_value,3,max_value,8,0,4]
row5 = [5,max_value,max_value,10,4,0]
maps = [row0, row1, row2,row3, row4, row5]
maps2=[[0,6,3,2,99,99,99],
[6,0,5,99,99,2,99],
[3,5,0,3,99,1,99],
[2,99,3,0,5,99,6],
[99,99,99,5,0,6,2],
[99,2,1,99,6,0,4],
[99,99,99,6,2,4,0]]
'''
n_length=int(input())
maps=[]
for i in range(n_length):
maps.append(list(map(int,input().split())))
graph = Graph(maps)
#print('邻接矩阵为\n%s'%graph.maps)
#print('节点数据为%d,边数为%d\n'%(graph.nodenum, graph.edgenum))
#print('最小生成树kruskal算法')
#print(graph.kruskal())
#print('最小生成树prim算法')
print(graph.prim())

