豆瓣读书数据存入Mysql数据库
1. 豆瓣数据爬取
这一部分之前的爬虫专项中已经有详细讲到过,这里直接给出代码如下,保留了输入的图书类型和要爬取页数的接口,需要注意cookie要填写自己计算机的上对应的内容
#coding=utf8
from bs4 import BeautifulSoup
import requests
import pandas as pd
from urllib import parse
from doubandb import Book,sess
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Cookie': 'll="108296"; bid=b9z-Z1JF8wQ; _vwo_uuid_v2=DDF408830197B90007427EFEAB67DF985|b500ed9e7e3b5f6efec01c709b7000c3; '
} #输入自己的cookie
def get_html(url):
html = requests.get(url,headers = headers)
if html.status_code == 200:
print('正在解析页面......')
parse_html(html.text)
else:
print('ERROR!')
def parse_html(text):
soup = BeautifulSoup(text,'lxml')
books = soup.select('li.subject-item')
for book in books:
title = book.select_one('.info h2 a').text.strip().replace('\n','').replace(' ','')
info = book.select_one('.info .pub').text.replace('\n','').replace(' ','')
star = book.select_one('.rating_nums').text.replace('\n','').replace(' ','')
pl = book.select_one('.pl').text.replace('\n','').replace(' ','')
introduce = book.select_one('.info p').text.replace('\n','').replace(' ','')
img = book.select_one('.nbg img')['src']
print(title,info)
if __name__ == '__main__':
keyword = parse.quote(input('请输入要爬取的类型:'))
num = eval(input('请输入要爬取的页数:'))
for i in range(0,num):
url = f'https://book.douban.com/tag/{keyword}?start={i*20}&type=T'
get_html(url)
2. 创建数据库表单
这一步是新建一个py文件,然后导入相关的库,创建引擎后加载爬取数据对应的表单,如下
from sqlalchemy import create_engine
from sqlalchemy import Column,String,Integer,Text
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
#继承基类
Base = declarative_base()
engine = create_engine(
'mysql+pymysql://root:[email protected]:3306/test?charset=utf8',
echo = True
)#这里就是存入数据,单线程,不需要设置其他参数了
#Book类的设置就是与爬取的数据相对应
class Book(Base):
__tablename__ = 'book'
id = Column('id',Integer,primary_key=True,autoincrement=True)
title = Column('title',String(20))
info = Column('info',String(30))
star = Column('star',String(10))
pl = Column('pl',String(10))
describe = Column('desc',Text())
#加载表单
Base.metadata.create_all(engine)
→ 输出的结果为:(基于之前的表单,又多了一个book表单)
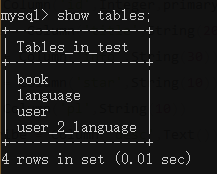
3. 插入数据
需要在创建引擎的文件加下添加session,如下
session = sessionmaker(engine)
sess = session()
然后在爬虫的文件夹里面导入相应的内容(就是从刚刚创建的引擎和session的文件中导入数据),如下
from doubandb import Book,sess
#插入数据库
book_data =Book(
title = title,
info = info,
star = star,
pl = pl,
introduce = introduce,
)
sess.add(book_data)
sess.commit()
运行之后,如果显示如下内容:
pymysql.err.DataError: (1406, "Data too long for column '字段名' at row 1")
解决方式为:(在命令行下进入mysql后执行下面语句)
SET @@global.sql_mode='';
→ 输出的结果为:(执行爬虫代码后结果如下)

4. 全部代码
代码分为两个部分,一个douban.py是爬取数据的文件,还有一个doubandb.py是用来设置数据库相关的内容的
① doubandb.py 文件中的代码如下
from sqlalchemy import create_engine
from sqlalchemy import Column,String,Integer,Text
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
engine = create_engine(
'mysql+pymysql://root:[email protected]:3306/test?charset=utf8',
echo = True
)
class Book(Base):
__tablename__ = 'book'
id = Column('id',Integer(),primary_key=True,autoincrement=True)
title = Column('title',Text())
info = Column('info',Text())
star = Column('star',Text())
pl = Column('pl',Text())
introduce = Column('introduce',Text())
Base.metadata.create_all(engine)
session = sessionmaker(engine)
sess = session()
② douban.py中的代码如下:
#coding=utf8
from bs4 import BeautifulSoup
import requests
import pandas as pd
from urllib import parse
from doubandb import Book,sess
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Cookie': 'll="108296"; bid=b9z-Z1JF8wQ; _vwo_uuid_v2=DDF408830197B90007427EFEAB67DF985|b500ed9e7e3b5f6efec01c709b7000c3;'
}
def get_html(url):
html = requests.get(url,headers = headers)
if html.status_code == 200:
print('正在解析页面......')
parse_html(html.text)
else:
print('ERROR!')
def parse_html(text):
soup = BeautifulSoup(text,'lxml')
books = soup.select('li.subject-item')
for book in books:
try :
title = book.select_one('.info h2 a').text.strip().replace('\n','').replace(' ','')
info = book.select_one('.info .pub').text.replace('\n','').replace(' ','')
star = book.select_one('.rating_nums').text.replace('\n','').replace(' ','')
pl = book.select_one('.pl').text.replace('\n','').replace(' ','')
introduce = book.select_one('.info p').text.replace('\n','').replace(' ','')
img = book.select_one('.nbg img')['src']
print(title,info)
#插入数据库
book_data =Book(
title = title,
info = info,
star = star,
pl = pl,
introduce = introduce,
)
sess.add(book_data)
sess.commit()
except Exception as e:
print(e)
sess.rollback()
if __name__ == '__main__':
keyword = parse.quote(input('请输入要爬取的类型:'))
num = eval(input('请输入要爬取的页数:'))
for i in range(0,num):
url = f'https://book.douban.com/tag/{keyword}?start={i*20}&type=T'
get_html(url)
