1. 模块安装
Echarts.js是一个由百度开源的基于JavaScript的数据可视化工具库,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 就诞生了,因此在使用之前需要安装这个模块
cmd界面安装指令
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts
安装界面如下

2. 根据词频计数生成词云图
1) 转化数据格式
按照新版词云绘制的要求,data数据需要转化为[(‘a’,1),(‘b’,2)]的数据类型,因此再获得索引和值之后要将两者组合起来,可以使用list(zip(data1,data2))的方法
# 提取所有名词+人名 - 多条件,并集
df_nper = df_news_pos[(df_news_pos['pos'] == 'n') | (df_news_pos['ne'] == 'PER')]
nper_counts = df_nper['item'].value_counts()
# 提取每个词
words = nper_counts.index.tolist()
# 提取每个词的词频
words_counts = nper_counts.values.tolist()
data = list(zip(words, words_counts))
print(data)
–> 输出的结果为:(注意一定要tolist(),不然出图显示空白)
[('孙杨', 70),('杨明', 26), ('妈妈', 15),('事情', 11), ('儿子', 9), ('运动员', 8), ('问题', 6), ('记者', 6), ('朱志根', 5), ('母亲', 5), ('时间', 5), ('成绩', 5), ('孩子', 5), ('大牌', 4), ('领导', 4), ('职业生涯', 4), ('听证会', 4), ('媒体', 4), ('教练', 4), ('国际', 3), ('个人', 3), ('时', 2), ('律师', 2) ......
2) 绘制词云图
from pyecharts.charts import WordCloud
from pyecharts import options as opts
worls_cloud = WordCloud()
worls_cloud.add('',data,word_size_range=[20,100])
worls_cloud.set_global_opts(title_opts=opts.TitleOpts(title='词云示例'))
worls_cloud.render(r'C:\Users\86177\Desktop\wordcloud.html')
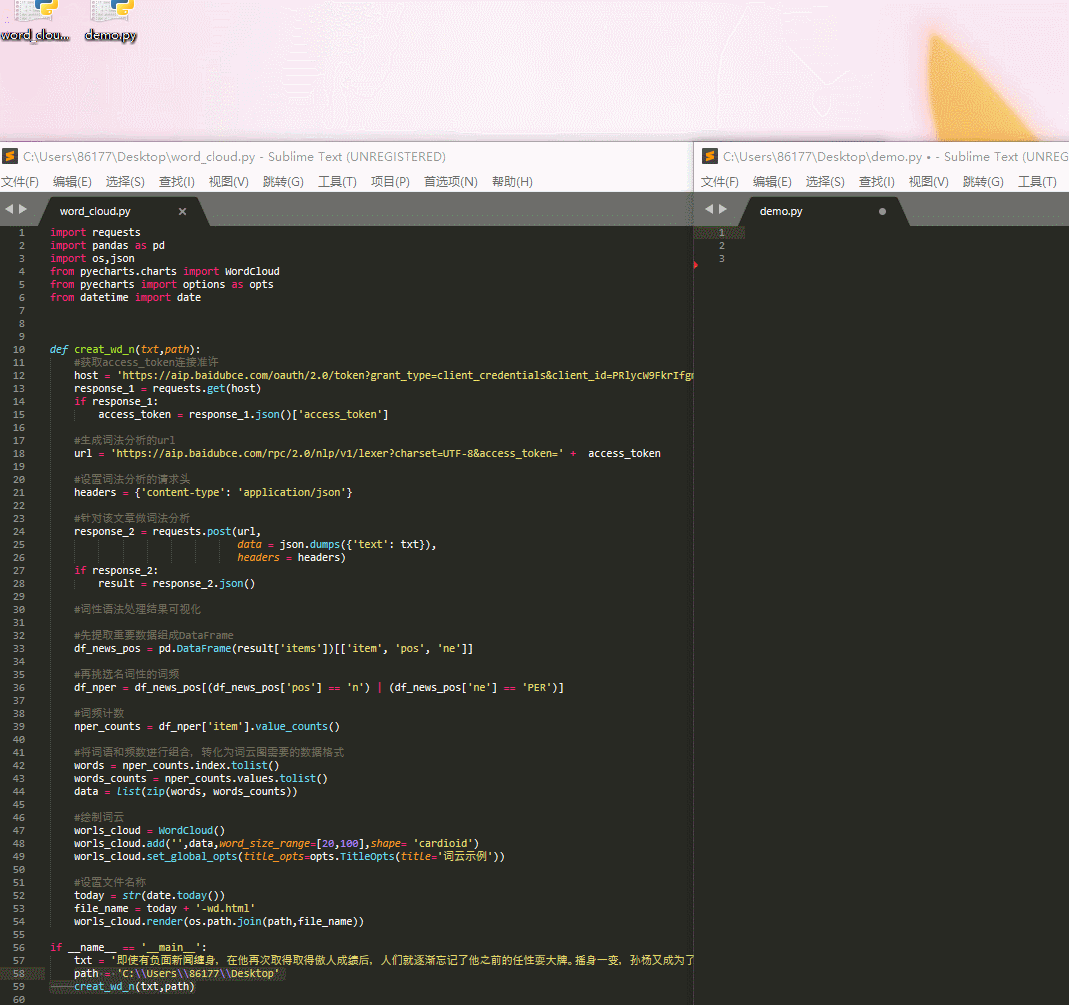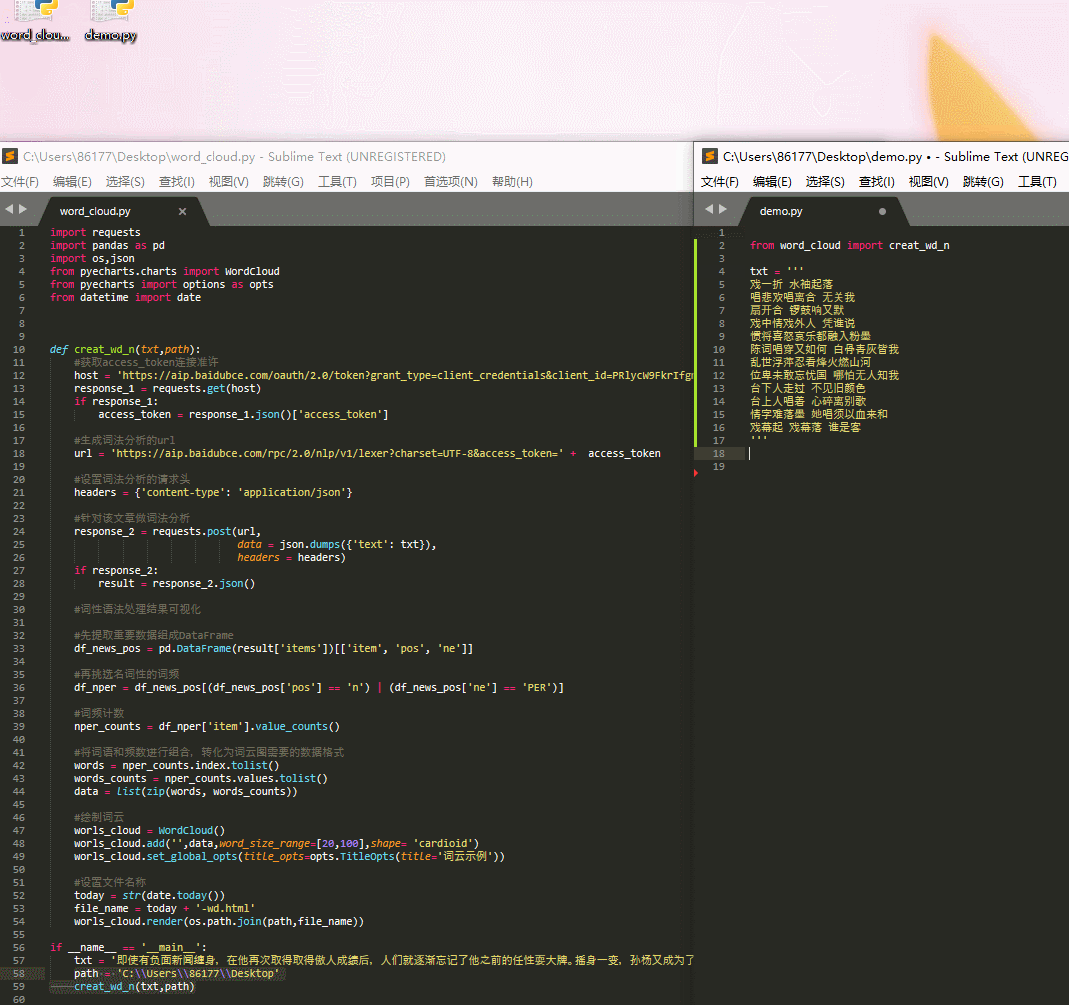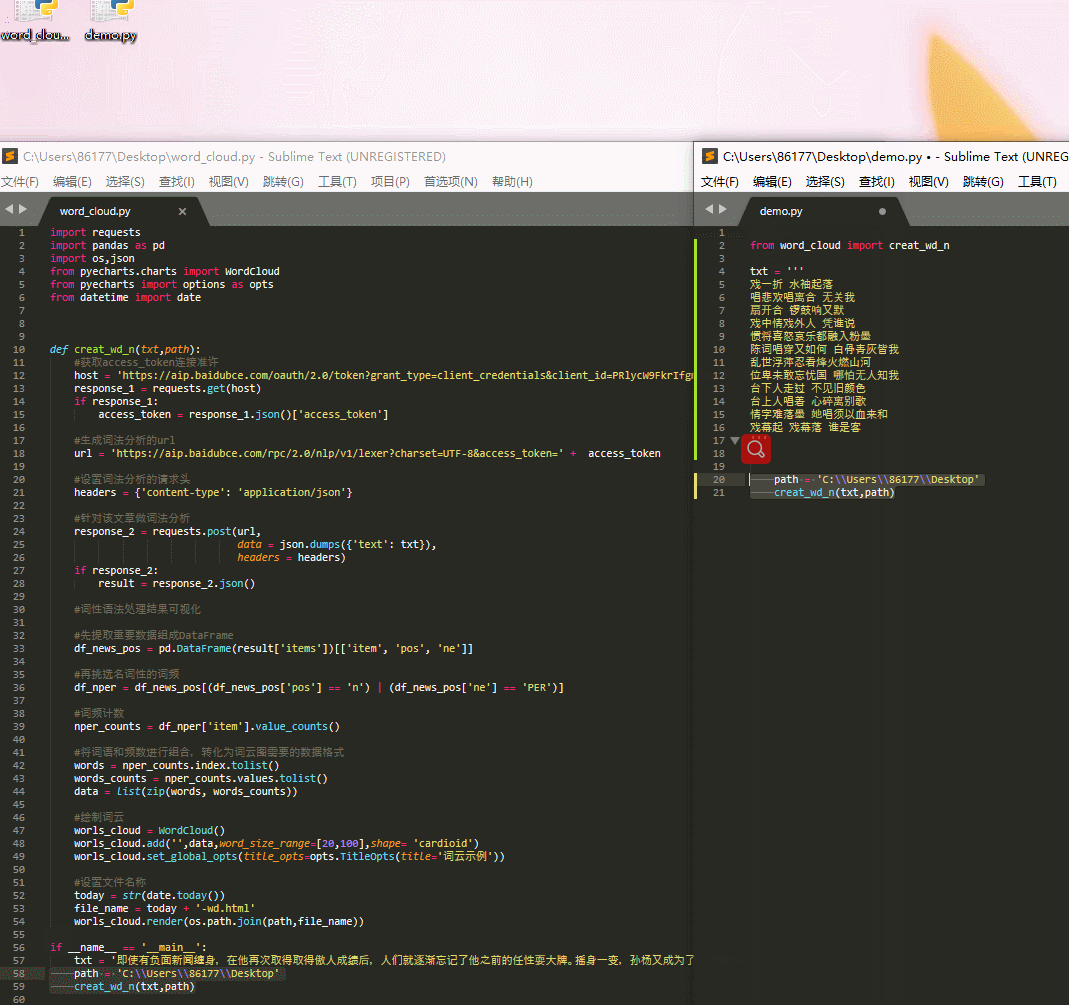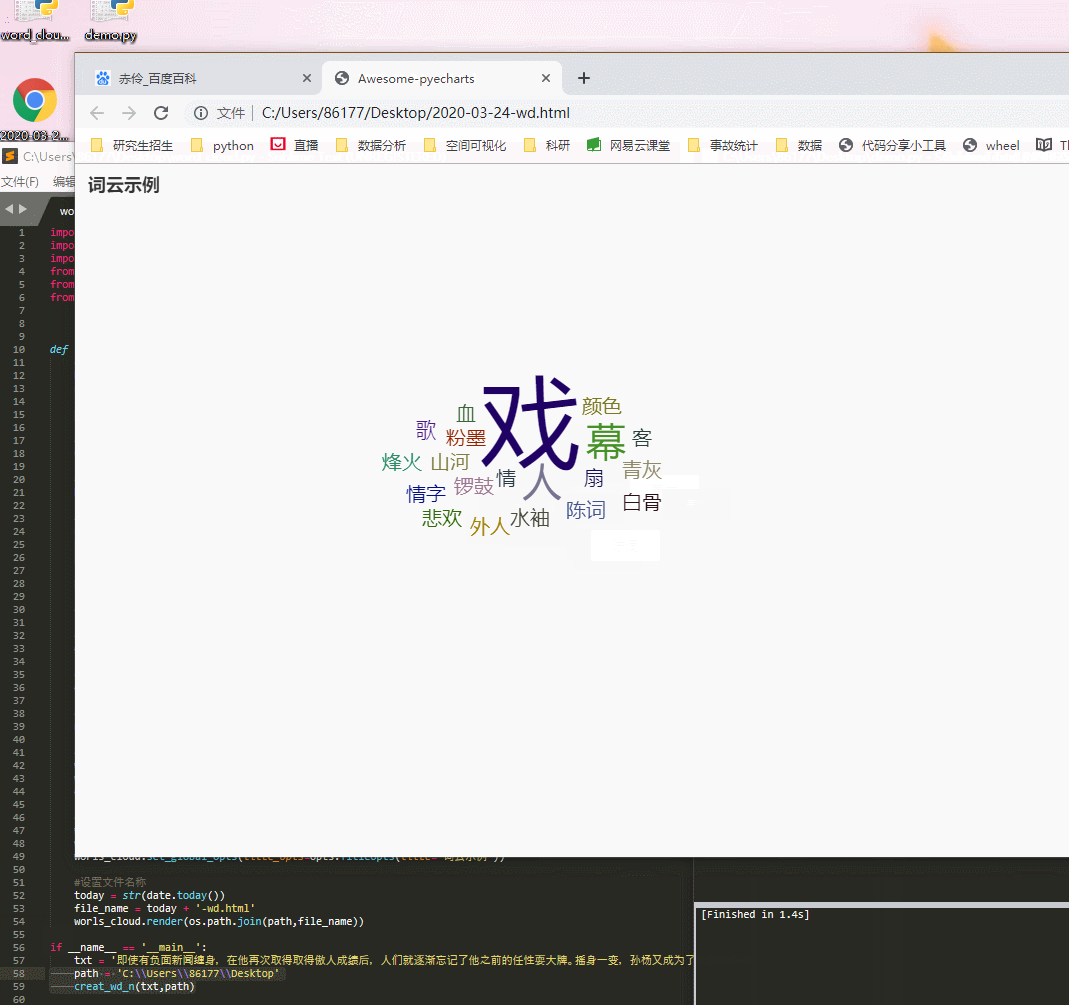
–> 输出的结果为:(可以根据词云图来剔除重复数据)

3) 数据去重
在成功制作了词云图之后,我们也会发现会有一些相同含义但词语不同的内容,例如’孙杨妈妈’、‘孙妈妈’、‘母亲’、‘妈妈’、'杨明’其实都代表孙杨母亲杨明,包括’儿子’也代指孙杨,如果大家光看分词的表格数据,是很难快速判断的,但有了词云图就很快察觉出来了。
统一标准: 所以这里我们基于词云图,先对原始文本数据做一遍清洗,我们把相同含义的词语都归类为1个词,例如:所有指向孙杨母亲杨明的,我们都用’孙母’;所有指向孙杨的,我们都用’孙杨’
news_r = news.replace('孙杨妈妈', '孙母')
news_r = news_r.replace('孙妈妈', '孙母')
news_r = news_r.replace('母亲', '孙母')
news_r = news_r.replace('杨明', '孙母')
news_r = news_r.replace('妈妈', '孙母')
news_r = news_r.replace('儿子', '孙杨')
# 查看前100个字
news_r[:100]
–> 输出的结果为:(一定要注意先替换’大的’称呼,再替换’小的’,不然的话,会造成部分数据的增多,比如先替换妈妈字段就会把孙杨妈妈这个字段也被替换,就多出来一个孙杨的数据)
'\n孙杨的事情,还没有结束。最近,他的孙母孙母,也被卷进了舆论风波中。在国际体育仲裁法庭宣布孙杨禁赛八年后,爱子心切的孙母,在朋友圈发了一条长文。文章开头,就在哭诉孙杨的不容易。之后,她就开始指责领导的'
3. 封装函数接口方便今后直接调用
经过上面的分析已经可以正常的出图了,那么为了方便今后工作的使用,可以直接封装一个函数,这样就不用去翻看密匙,再进行一步步的输出了
import requests
import pandas as pd
import os
import json
from pyecharts.charts import WordCloud
from pyecharts import options as opts
from datetime import date
def creat_wd_n(txt,path):
#获取access_token连接准许,需要自己的密匙
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=PRlycIfgm7moLA6uLeW&client_secret=GGF88lVjTnLHbIYmwjPzfla1bhtE'
response_1 = requests.get(host)
if response_1:
access_token = response_1.json()['access_token']
#生成词法分析的url
url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=' + access_token
#设置词法分析的请求头
headers = {'content-type': 'application/json'}
#针对该文章做词法分析
response_2 = requests.post(url,
data = json.dumps({'text': txt}),
headers = headers)
if response_2:
result = response_2.json()
#词性语法处理结果可视化
#先提取重要数据组成DataFrame
df_news_pos = pd.DataFrame(result['items'])[['item', 'pos', 'ne']]
#再挑选名词性的词频
df_nper = df_news_pos[(df_news_pos['pos'] == 'n') | (df_news_pos['ne'] == 'PER')]
#词频计数
nper_counts = df_nper['item'].value_counts()
#将词语和频数进行组合,转化为词云图需要的数据格式
words = nper_counts.index.tolist()
words_counts = nper_counts.values.tolist()
data = list(zip(words, words_counts))
#绘制词云
worls_cloud = WordCloud()
worls_cloud.add('',data,word_size_range=[20,100],shape= 'cardioid')
worls_cloud.set_global_opts(title_opts=opts.TitleOpts(title='词云示例'))
#设置文件名称
today = str(date.today())
file_name = today + '-wd.html'
worls_cloud.render(os.path.join(path,file_name))
if __name__ == '__main__':
txt = '即使有负面新闻缠身,在他再次取得取得傲人成绩后,人们就逐渐忘记了他之前的任性耍大牌。摇身一变,孙杨又成为了大家眼中可爱的大白杨。即使后面他因穿个人签约品牌违反规定遭争议,孙杨也并未回应。而这些也都未击垮他的职业生涯,观众们也没做太多关心。直到14年,孙杨因为服用违禁药品问题,完美的职业生涯出现了一个缺口。'
path = 'C:\\Users\\86177\\Desktop'
creat_wd_n(txt,path)
4. 直接调用函数演示
刚刚封装的函数保存的文件名称为word_cloud.py(不要和第三方库的名称重复,还要有辨识度,可以尝试加下划线解决),要调用这个函数接口的话,可以直接在该文件的相同路径下直接调用这个函数(from 文件名 import 函数),如下,最后会在同文件夹下(这里是桌面)生成一个目标文件