图数据库常规的有:neo4j(支持超多语言)、JanusGraph/Titan(分布式)、Orientdb,google也开源了图数据库Cayley(Go语言构成)、PostgreSQL存储RDF格式数据。
—- 目前的几篇相关:—–
neo4j︱图数据库基本概念、操作罗列与整理(一)
neo4j︱Cypher 查询语言简单案例(二)
neo4j︱Cypher完整案例csv导入、关系联通、高级查询(三)
最后附上官方速查表图一张:来源
一、neo4j 基本操作元素
neo4j可支持语言:.NET、Java、Spring、JavaScript、Python、Ruby、PHP、R、Go、C / C++、Clojure、Perl、Haskell
几个专有名词:变量(标识符)、节点、关系、实体、标签、属性、索引、约束。
举个例子,理解一下专有名词:
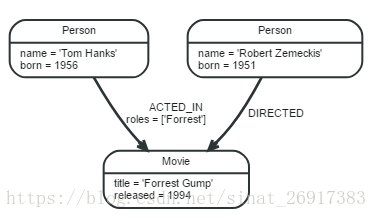
此结构中有:5个实体,三个节点和两个关系,实体包括节点和关系
Lable,Person和Movie
关系类型,ACTED_ID和DIRECTED
节点和关系的属性,name,title,roles等
变量
MATCH (n)-->(b) RETURN b
变量用于引用搜索模式(Pattern),但是变量不是必需的,如果不需要引用,那么可以忽略变量,譬如()就叫匿名变量。
小括号()中为命令变量环节,同时其区分大小写
索引
Cypher创建索引:
CREATE INDEX ON :Person(firstname)
CREATE INDEX ON :Person(firstname, surname)
便于更快查数。
约束
在图形数据库中,能够创建四种类型的约束:
• 节点属性值唯一约束(Unique node property):如果节点具有指定的标签和指定的属性,那么这些节点的属性值是唯一的
• 节点属性存在约束(Node property existence):创建的节点必须存在标签和指定的属性
• 关系属性存在约束(Relationship property existence):创建的关系存在类型和指定的属性
• 节点键约束(Node Key):在指定的标签中的节点中,指定的属性必须存在,并且属性值的组合是唯一的
CREATE CONSTRAINT ON (book:Book) ASSERT book.isbn IS UNIQUE;
CREATE CONSTRAINT ON (book:Book) ASSERT exists(book.isbn);
CREATE CONSTRAINT ON ()-[like:LIKED]-() ASSERT exists(like.day);
CREATE CONSTRAINT ON (n:Person) ASSERT (n.firstname, n.surname) IS NODE KEY;
.
二、数据库的增删改查
还是按照数据库的一贯风格,增删改查:
2.1 增-create/merge
2.1.1 create-创建节点
create (n:Person { name: 'Robert Zemeckis', born: 1951 }) return n;
create (变量:标签 {属性:’属性名称’}) return n;
变量名称可以是:任意,标签注意大小写
2.1.2 create-创建节点间关系
MATCH (a:Person),(b:Person)
where a.name = 'm'and b.name = 'Andres'
CREATE (a)-[r:girl]->(b)
RETURN r;
逻辑是,match定位到a,b两个数据集,然后找出两个中分别name为’m’/’Andres’的人,建立[r:girl]的关系。
2.1.3 create-创建节点间关系 + 关系属性
MATCH (a:Person),(b:Person)
WHERE a.name = 'm'and b.name = 'Andres'
CREATE (a)-[r:girl { roles:['friend'] }]->(b)
RETURN r;
逻辑:从姓名为m的人,到姓名为andres的人,建立关系girl,同时角色属性为friend
2.1.4 create-创建完整路径path
CREATE p =(vic:Worker:Person{ name:'vic',title:"Developer" })-[:WORKS_AT]->(neo)<-[:WORKS_AT]-(michael:Worker:Person { name: 'Michael',title:"Manager" })
RETURN p
逻辑为:创建vic这个人与变量(neo)的[:WORKS_AT]关系;
创建michael这个人与变量(neo)的[:WORKS_AT]关系。
2.1.5 创建唯一性节点 CREATE UNIQUE
MATCH (root { name: 'root' })
CREATE UNIQUE (root)-[:LOVES]-(someone)
RETURN someone
2.1.6 merge-on create 新增属性
Merge子句的作用有两个:当模式(Pattern)存在时,匹配该模式;当模式不存在时,创建新的模式(参考)。
如果需要创建节点,那么执行on create子句,修改节点的属性;
MERGE (keanu:Person { name: 'Keanu Reeves' })
ON CREATE SET keanu.created = timestamp()
RETURN keanu.name, keanu.created
注意:ON CREATE SET只在创建使用有用,如果节点已经存在了,那么该命令失效。
2.2 删
大致有两个:DELETE与REMOVE
2.2.1 删除所有节点与关系——delete
删除单个节点:MATCH (n:Useless) DELETE n;
删除单个节点和连接它的关系:MATCH (n { name: 'Andres' })-[r]-() DELETE n, r
删除所有节点和关系:MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r
2.2.2 删除标签与属性——remove
删除属性:MATCH (andres { name: 'Andres' }) REMOVE andres.age RETURN andres;
删除节点的标签:MATCH (n { name: 'Peter' }) REMOVE n:German RETURN n;
删除多重标签:MATCH (n { name: 'Peter' }) REMOVE n:German:Swedish RETURN n
2.2.3 重设为NULL——set
删除属性:MATCH (n { name: ‘Andres’ }) SET n.name = NULL RETURN n
2.3 改
2.3.1 set
节点额外加入标签与属性
// 加入额外标签
match (n)
where id(n)=7
set n:Company
return n;
//加入额外属性
match (n)
where id(n)=100
set n.name = 'id100'
return n;
// 设置多个属性
MATCH (n { name: 'Andres' }) SET n.position = 'Developer', n.surname = 'Taylor'
通过set来进行额外加入标签与属性。同时,已有的关系可以通过set赋值上去。
在节点和关系之间复制属性:
MATCH (at { name: 'Andres' }),(pn { name: 'Peter' })
SET at = pn
RETURN at, pn;
2.3.2 merge-on match
如果节点已经存在于数据库中,那么执行on match子句,修改节点的属性;
MERGE (person:Person)
ON MATCH SET person.found = TRUE , person.lastAccessed = timestamp()
RETURN person.name, person.found, person.lastAccessed
注意:对于已经存在的节点进行属性重定义.
2.4 查
查的语句有:WHERE语句、ORDER BY 默认是升序,降序添加DESC、LIMIT 返回靠前的一定数目的数据、SKIP 返回靠后的一定数目的数据、UNION 子查询结果合并
还可能查询一些pattern。
2.4.1 where/order by
属性查看: match(n) where n.born<1955 return n;
2.4.2 LIMIT
MATCH (a:Person)
RETURN a LIMIT 5
2.4.3 skip
match (n) return n order by n.name skip 3;
match (n) return n order by n.name skip 1 limit 3;
2.4.4 union
MATCH (pp:Person)
RETURN pp.age,pp.name
UNION
MATCH (cc:Customer)
RETURN cc.age,cc.name
2.4.5 return
返回一个节点:match (n {name:”B”}) return n;
返回一个关系:match (n {name:”A”})-[r:KNOWS]->(c) return r;
返回一个属性:match (n {name:”A”}) return n.name;
返回所有节点:match p=(a {name:”A”})-[r]->(b) return *;
列别名: match (a {name:”A”}) return a.age as thisisage;
表达式: match (a {name:”A”}) return a.age >30 ,”literal”,(a)–>();
唯一结果:match (a {name:”A”})–>(b) return distinct b;
2.4.6 merge-查询
在merge子句中指定on match子句
如果节点已经存在于数据库中,那么执行on match子句,修改节点的属性;
MERGE (person:Person)
ON MATCH SET person.found = TRUE , person.lastAccessed = timestamp()
RETURN person.name, person.found, person.lastAccessed
merge子句用于match或create多个关系
MATCH (oliver:Person { name: 'Oliver Stone' }),(reiner:Person { name: 'Rob Reiner' })
MERGE (oliver)-[:DIRECTED]->(movie:Movie)<-[:ACTED_IN]-(reiner)
RETURN movie
2.4.7 集合函数查询
(1)通过id函数,返回节点或关系的ID
MATCH (:Person { name: 'Oliver Stone' })-[r]->(movie)
RETURN id(r);
(2)通过type函数,查询关系的类型
MATCH (:Person { name: 'Oliver Stone' })-[r]->(movie)
RETURN type(r);
(3)通过lables函数,查询节点的标签
MATCH (:Person { name: 'Oliver Stone' })-[r]->(movie)
RETURN lables(movie);
(4)通过keys函数,查看节点或关系的属性键
MATCH (a)
WHERE a.name = 'Alice'
RETURN keys(a)
(5)通过properties()函数,查看节点或关系的属性
CREATE (p:Person { name: 'Stefan', city: 'Berlin' })
RETURN properties(p)
(6)nodes(path):返回path中节点
match p=(a)-->(b)-->(c) where a.name='Alice' and c.name='Eskil' return nodes(p)
(7)relationships(path):返回path中的关系
match p=(a)-->(b)-->(c) where a.name='Alice' and c.name='Eskil' return relationships(p)
2.4.8 路径查询
- 常规路径查询:
MATCH (:Person { name: 'm' })-->(person)
RETURN person;返回的是:name为m的这个节点,指向的节点,不包括m节点本身
- 可变长度路径:
match (a:Product {productName:'Chai'} )-[*1..5]-(b:Customer{companyName : 'Frankenversand'}) return a,b
//[*1..5]可变长度路径,从a到b的1-5条路径;- 零长度路径
START a=node(3)
MATCH p1=a-[:KNOWS*0..1]->b, p2=b-[:BLOCKS*0..1]->c
RETURN a,b,c, length(p1), length(p2)这个查询将返回四个路径,其中有些路径长度为0.
- 最短路径
使用shortestPath函数可以找出一条两个节点间的最短路径,如下。
查询:
START d=node(1), e=node(2)
MATCH p = shortestPath( d-[*..15]->e )
RETURN p这意味着:找出两点间的一条最短路径,最大关系长度为15.圆括号内是一个简单的路径连接,开始节点,连接关系和结束节点。关系的字符描述像关系类型,最大数和方向在寻找最短路径中都将被用到。也可以标识路径为可选。
2.4.9 查询关系属性
MATCH (:Person { name: 'matt' })-[r]->( Person)
RETURN r,type(r);
功能:查看姓名为matt的人,到标签person之间,关系有哪些
2.4.10 一些特殊的用法:
with用法:with从句可以连接多个查询的结果,即将上一个查询的结果用作下一个查询的开始。
collecty用法:代表把内容序列化
with用法、匿名变量(具体可以见《图数据库》,40P)
(1)匿名变量
(a)<-[:ass]-()-[:bss]->(b)
(2)with用法:
match (a)-[:work]->(b)
with b ORDER BY b.yeah DESC
RETURN a,b
过滤聚合函数的结果:
MATCH (david { name: “David” })–(otherPerson)–>() WITH otherPerson, count(*) AS foaf
WHERE foaf > 1 RETURN otherPerson;
collect前排序结果:
MATCH (n) WITH n ORDER BY n.name DESC LIMIT 3 RETURN collect(n.name;
limit搜索路径的分支:
MATCH (n { name: "Anders" })--(m) WITH m
ORDER BY m.name DESC LIMIT 1 MATCH (m)--(o) RETURN o.name;
2.4.11 UNWIND
将一个集合展开为一个可选的list,有点像py中的生成器。
//{batch: [{name:"Alice",age:32},{name:"Bob",age:42}]}
UNWIND {batch} as row
CREATE (n:Label)
SET n.name = row.name, n.age = row.age其中row,就被定义为一个可迭代的List。
案例二:
//{batch: [{from:"[email protected]",to:"[email protected]",properties:{since:2012}},{from:"[email protected]",to:"[email protected]",properties:{since:2016}}]}
UNWIND {batch} as row
MATCH (from:Label {from:row.from})
MATCH (to:Label {to:row.to})
CREATE/MERGE (from)-[rel:KNOWS]->(to)
(ON CREATE) SET rel.since = row.properties.since
2.5 统计与集合函数
2.5.1 统计函数
常见的有:abs(),acos(),asin(),atan(),atan2(x,y),cos(),cot(),degree(),e()返回一个常量,exp(2) e的二次方,floor(0.9)=0.0,
haversin(),log(),log10(),pi()常量PI,radians(180),rand()返回0到1.0的值,round(3.14)=3.0,sign(),sin(),sqrt(),tan()
count:MATCH (n { name: ‘A’ })–>(x) RETURN n, count(*)
sum:MATCH (n:Person) RETURN sum(n.property)
avg:MATCH (n:Person) RETURN avg(n.property)
percentileDisc:计算百分位。MATCH (n:Person) RETURN percentileDisc(n.property, 0.5)
percentileCont:MATCH (n:Person) RETURN percentileCont(n.property, 0.4)
stdev:计算标准偏差。MATCH (n) WHERE n.name IN [‘A’, ‘B’, ‘C’] RETURN stdev(n.property)
stdevp:MATCH (n) WHERE n.name IN [‘A’, ‘B’, ‘C’] RETURN stdevp(n.property)
max:MATCH (n:Person) RETURN max(n.property)
min:MATCH (n:Person) RETURN min(n.property)
collect:MATCH (n:Person) RETURN collect(n.property)
distinct:MATCH (a:Person { name: ‘A’ })–>(b) RETURN
coalesce:返回第一个not null值。match (a) where a.name=’Alice’ return coalesce(a.hairColor,a.eyes)
head:返回集合的第一个元素。match (a) where a.name=’Alic’ return a.array,head(a.array);
last:返回集合的最后一个元素。match (a) where a.name=’Alic’ return a.array,last(a.array);
timestamp:返回当前时间的毫秒
startNode:返回一个关系的开始节点。match (x:foo)-[r]-() return startNode(r);
endNode:返回一个关系的结束节点。match (x:foo)-[r]-() return endNode(r);
toInt,toFloat,toString
参考文献:
书籍:《Graph Databases》
Example Project
图数据库之Cypher语言
neo4j教程
[Neo4j系列三]Neo4j的查询语言Cypher
Neo4j 第三篇:Cypher查询入门
Neo4j 第二篇:图形数据库
Neo4j Cypher查询语言详解

