排序算法综合及效率比较
- 实验目的
- 实验内容
- 实验要求
- 实验步骤
- 概要设计
- 详细设计
- 软件测试
- 设计总结
- 源程序代码
1.实验目的
(1)熟练掌握几种经典排序的算法(如冒泡排序、选择排序、插入排序、希尔排序、折半插入排序、快速排序、归并排序、堆排序等)。培养综合运用所学知识,根据具体问题进行数据结构设计和算法设计的能力。
(2)熟练掌握简单的演示菜单与人机交互设计方法。
2.实验内容
(1)用rand()函数随机产生1-1000中30000个随机数并保存在数组array[]中。
(2)运用各种排序方法对30000个随机数进行由小到大排序。
(3)将排序结果写入不同的文件中。
(4)运用测试时间clock()函数计算各种排序的时间,并得出两种排序性能好的排序方法。
3.实验要求
(1)试描述各种排序ADT。
(2)采用数组作为存储结构,通过利用随机函数产生N个随机整数(20000个以上),并对这些数进行多种方法进行排序。
(3)至少采用三种方法实现上述问题求解(可采用的方法有冒泡排序、选择排序、插入排序、希尔排序、折半插入排序、快速排序、归并排序、堆排序)。
(4)把排序后的数据结果保存在不同的文件中.
(5)统计每一种排序方法的性能(以上机运行程序话费时间为准进行对比),找出其中两种较快的方法。
4.实验步骤
本演示程序用C语言编写,先用产生随机数函数rand()函数产生1-1000中30000个随机数,然后运用各种排序算法(如:冒泡排序、选择排序、插入排序、希尔排序、折半插入排序、快速排序、归并排序、堆排序等)对30000个随机数进行排序,最后用测试时间函数clock()函数来计算各种排序所话费的时间,以比较各种排序的性能。
(1) 输入的形式和输入值的范围:
用rand()函数产生1-1000随机正整数,并保存到数组中。即array[i]=rand()%1000+1
(2) 输出的形式:
根据不同的排序方法输出一系列有序数据,并将数据保存在各自文件中;
(3) 测试数据及预期结果:
冒泡排序:写出数据成功!读入数据成功!
1 1 1 2 2 2 2 … 998 999 999 999 1000 1000 用时:**秒
选择排序:写出数据成功!读入数据成功!
1 1 1 2 2 2 2 … 998 999 999 999 1000 1000 用时:**秒
…
…
5.概要设计
5.1函数详细设计
- 主函数main()
- 主控菜单函数menu()
- 产生随机数函数rand()
- 测试程序运行时间函数clock()
- 冒泡排序算法函数maopao()
- 选择排序算法函数xuanze()
- 插入排序函数insert()
- 折半插入排序函数binsertSort()
- 希尔排序函数shell()
- 为简化代码,各排序公共部分代码函数same()
- 显示方法和所用时间函数display()
- 选择菜单函数choice()
- 系统命令清屏函数system(“cls”)
5.2各函数间的调用关系
- 主函数main()调用选择菜单choice()函数
- 选择菜单choice函数调用menu()主控制菜单函数.其中的switch语句调用了冒泡排序算法函数maopao()、选择排序算法函数xuanze()、插入排序函数insert()、折半插入排序函数binsertSort()、希尔排序函数shell()、显示方法和所用时间函数display()
- 为简化代码,各种排序算法中均调用了公共部分代码函数same()
5.3随机数的生成以及存储操作
for(i=0;i<NUM;i++){ //NUM=30000
array[i]=rand()%1000+1;
}
5.4典型(或重要)算法的描述
- 产生随机数的算法:
srand()函数用来设置rand()函数产生随机数时的随机数种子。参数seed必须是整数,如果每次seed都设相同的值,rand()函数所产生的随机数值每次就会一样。rand()函数的内部数显示用线性同余法做的,它不是真的随机数,它返回一随机数的范围在0至MAX之间,MAX的范围最少是在32767之间(int),并且在0-MAX每个数字被选中的几率是相同的。 - 冒泡排序算法描述:
基本思路是不断地将所有的相邻数据进行比较,如果前面的数据大于后面的数据(a[j]>a[j+1]),就将两个位置的数据进行交换,最终实现所有数据按照非递减的顺序重新排列。 - 选择排序算法描述:
这是基于选择手段的排序算法,假设有n个数据将要参与排序操作,首先从n个数据中选择一个最小的数据,并将它交换到第一个位置;然后再从后边的n-1个数据中选择一个最小的数,并将它交换到第二个位置;以此类推,直到最后两个数据中选择一个最小的数据,并将它交换到第n-1个位置为止,整个排序操作结束。 - 插入排序算法描述:
基本思想是每次将一个待排序的记录,按其关键字大小插入到前面已经排好的序列中直到全部记录插入完成为止。假设待排序列的记录存放在R【1…n】中。初始时,R【1】自成1个有序区,无序区为R【2…n】,从i=2起直到i=n为止,依次将R【i】插入当前的有序区R【1…i-1】中,生成含n个记录的有序区。 - 折半插入排序算法描述:
基本原理与直接插入排序相同,不同之处在于直接插入排序每次插入,都从前面的有序子表中查找出待插入元素应该被插入的位置;并给插入位置腾出空间,将待插入元素复制到表中的插入位置,该算法中总是变比较边移动元素。 - 希尔排序算法描述:
实质就是分组插入排序。现将整个待排元素序列分割成若干个子序列(由相隔某个增量的元素组成)分别进行直接插入排序,然后依次缩小增量再进行排序,待整个序列中的元素基本有序(增量足够小时),再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下,效率是很高的,因此希尔排序在时间效率上很高。
5.5调试分析
- 分析算法的总体结构,分清程序中各部分应实现的功能;
- 调试方法通常有二种:总体调试、分块调试。
总体调试:把算法组装成单个程序,按C程序结构标准分层检查调试;
分块调试:把算法分拆成几个功能模块,按C程序结构标准分模块调试; - 错误跟踪有两种方法:错误信息排查法、执行路线跟踪法。
错误信息排查法:根据错误信息进行分类排查,要求分析者对C的错误代码要有足够的了解和认识,有经验的程序员多用此法。
执行路线跟踪法:变量分析法(跟踪变量的值)、插入标签法(插入输出标签),这种方法适合初学者。 - 调试分析不宜面面俱到,具体写出关键问题就行。
5.6创新部分
此程序添加了计时器,用于精确测试各种排序方法所运行的时间,以比较各种排序方法的性能。计时函数为clock(),这个函数返回从“开启这个程序进程”到“程序中调用clock()函数”时之间的CPU始终计时单元数,其中clock_t是用来保存时间的数据类型,在time.h文件中。
如程序中start = clock()表示开始计时。而finish = clock()表示结束计时,再运用duration = (double)(finish - start) / CLOCKS_PER_SEC用来计算程序的运行时间。
5.7使用说明
1.运行界面为DOS;运行软件:Visual C++ 6.0
2.首先在主控制菜单中选择操作数1-5进行各种排序,各种排序完成后,经排序后的数据会自动写入各自对应的记事本文件。然后返回主菜单选择操作数6显示各种排序方法和时间,以便比较各种排序算法性能。
6.详细设计
6.1 概要设计
功能模块图:

7.软件测试
-
主界面

-
冒泡排序(写入文件+运行时间)
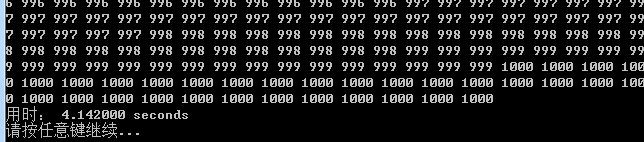

-
选择排序(写入文件+运行时间)
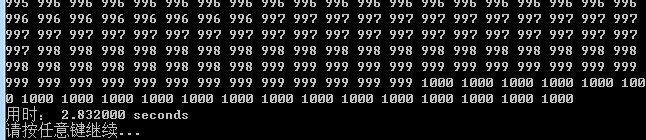

-
插入排序(写入文件+运行时间)
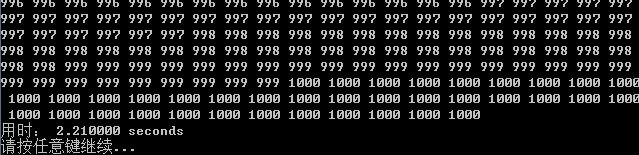

-
希尔排序(写入文件+运行时间)
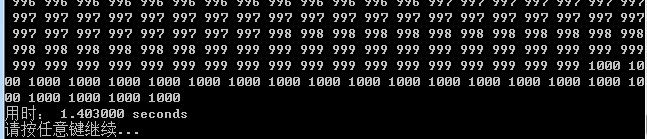
-
折半插入排序(写入文件+运行时间)


-
显示方法和运行时间

8.设计总结
- 在进行编写程序时,首先应该做出要求结构图进行结构化分块,这样即可将一个很大的工程变成若干小部分,一小块一小块编程效率会更高,目的性更强。建议可以使用思维导图进行构建。也可以先写好各自的排序算法,然后将这些算法加以总结在一起,构造一个出排序综合系统。因为在分开写时头脑会更加清晰
- 在用产生随机数函数rand()时,要运用stdlib.h头文件,以及在运用测试时间函数clock()时要用到time.h头文件,否则会在编译时产生错误
- 为了提高程序性能,要化简代码,如本程序中的same()函数,其里面的代码为各种排序中的共用部分,然后调用其即可,可提高程序性能
- 折半插入排序在进行插入时的基本思想就像二分法查找那样,把待插入元素插入到已有序的序列中,如果array[mid]>array[i],则查找左半子表,否则查找右半子表。而且在已经保存在顺序表中的元素进行删除或插入操作时会很费时间
- 调试第一步:找出一些因为粗心而导致的错误如:少大括号,少逗号,字母打错,没有分清大小写,等等
- 调试第二步:主要是针对函数。在使用switch-case语句时,不要忘记写break
- 要严格注意各种排序算法程序中循环条件,思路要清晰,否则运行出来达不到想要的目的。要把握全局,定义好要使用的全局变量,以方便使用,简化程序代码结构
- 在程序中使用清屏函数system(“cls”)和系统中断函数system(“pause”)可增加程序运行过程中的条理性以及为用户提供方便可读性高的操作界面
- 由实验结果可得出在所运用的五种排序算法中希尔排序所用时间最少,排序最快
- 在编程时我们应该适当的对程序进行注释,因为在当时调试程序时可能会非常清楚,但是经过一段时间,回头再看程序时,在重点算法处可能就会有所淡忘,因此应该对其注释,方便回忆。同时也会增强程序的可读性,在其他人阅读时更加方便
- 设计的运行界面要美观,给用户一种新鲜感
9.源程序代码
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#define NUM 30000
/*全局变量*/
int array[NUM];
FILE *fp;
clock_t start, finish;
double duration;
double t1,t2,t3,t4,t5;
/*
作者:C位出道、
*/
/*为简化代码,此函数代码为公用部分*/
void same()
{
int i;
for(i=0;i<NUM;i++){
printf("%d ",array[i]);
}
printf("\n");
finish = clock(); //结束计时
duration = (double)(finish - start) / CLOCKS_PER_SEC;
printf("用时: %f seconds\n", duration);
printf("请按任意键继续...\n");
getch();
}
/*冒泡排序*/
void maopao()
{
int i,j;
start = clock(); //开始计时
srand(time(NULL));//初始化随机数
for(i=0;i<NUM;i++){
array[i]=rand()%1000+1;
}
for(i=0;i<NUM-1;i++){
for(j=0;j<NUM-1-i;j++){
if(array[j]>array[j+1]){
int temp=array[j]; //设置中间变量
array[j]=array[j+1];
array[j+1]=temp;
}
}
}
if((fp=fopen("./起泡排序.txt","w"))==NULL)
printf("文件无法打开!");
else
{
for(i=0;i<NUM;i++)
{
fprintf(fp,"%d ",array[i]);
}
}
fclose(fp);
printf("写出数据成功!\n"); //写文件
if((fp=fopen("./起泡排序.txt","r"))==NULL)
printf("文件无法打开!");
else
{
for(i=0;i<NUM;i++)
{
fscanf(fp,"%d ",&array[i]);
}
}
fclose(fp);
printf("读入数据成功!\n"); //读文件
same();
t1=duration;
}
/*选择排序*/
void xuanze()
{
int i,j,n=NUM,temp,minValue;
start = clock(); //开始计时
srand(time(NULL));
for(i=0;i<NUM;i++){
array[i]=rand()%1000+1;
}
for(i = 0; i < n - 1; i++) //第一个数到倒数第二个数
{
minValue = i; //先把最小值赋值给第一个数
for(j = i + 1; j < n; j++) //用循环实现选择i到n-1之间最小的数值
if(array[j] < array[minValue]) //如果发现比当前最小元素还小的元素,则更新记录最小元素的下标d
minValue = j;
if(minValue != i) //交换数值
{
temp = array[minValue];
array[minValue] = array[i];
array[i] = temp;
}
}
/*写数据到文件*/
if((fp=fopen("./选择排序.txt","w"))==NULL)
printf("文件无法打开!");
else
{
for(i=0;i<NUM;i++)
{
fprintf(fp,"%d ",array[i]);
}
}
fclose(fp);
printf("写出数据成功!\n");
/*读取文件中数据*/
if((fp=fopen("./选择排序.txt","r"))==NULL)
printf("文件无法打开!");
else
{
for(i=0;i<NUM;i++)
{
fscanf(fp,"%d ",&array[i]);
}
}
fclose(fp);
printf("读入数据成功!\n");
same();
t2=duration;
}
/*插入排序的基本思想:每次将一个待排序的记录,按其关键字大小插入到前面已经排好的序列中
直到全部记录插入完成为止
直接插入排序方法的基本思想:
假设待排序列的记录存放在R【1..n】中。初始时,R【1】自成1个有序区,无序区为R【2..n】,
从i=2起直到i=n为止,依次将R【i】插入当前的有序区R【1..i-1】中,生成含n个记录的有序区。
*/
/*插入排序*/
void insert()
{
int i,j,n=NUM,insertVal;
start = clock();
srand(time(NULL)); //初始化随机数
for(i=0;i<NUM;i++){
array[i]=rand()%1000+1;
}
for(i=1;i<n;i++){
insertVal=array[i]; //insertVal为准备插入的数
j=i-1; //插入的数与有序序列最后一个进行比较
while(j>=0&&insertVal<array[j]){
array[j+1]=array[j]; //下标往后移
j--;
}
array[j+1]=insertVal;
}
if((fp=fopen("./插入排序.txt","w"))==NULL)
printf("文件无法打开!");
else
{
for(i=0;i<NUM;i++)
{
fprintf(fp,"%d ",array[i]);
}
}
fclose(fp);
printf("写出数据成功!\n");
if((fp=fopen("./插入排序.txt","r"))==NULL)
printf("文件无法打开!");
else
{
for(i=0;i<NUM;i++)
{
fscanf(fp,"%d ",&array[i]);
}
}
fclose(fp);
printf("读入数据成功!\n");
same();
t3=duration;
}
/*折半插入排序*/
void binsertSort()
{
int i,j,low,high,mid,flag;
start = clock();
srand(time(NULL)); //初始化随机数
for(i=0;i<NUM;i++){
array[i]=rand()%1000+1;
}
for(i=1;i<NUM;i++){
flag=array[i]; //flag用来暂存元素
low=0;
high=i-1; //折半查找范围
while(low<=high){
mid=(low+high)/2;
if(array[mid]>array[i]){
high=mid-1; //查找左半子表
}else{
low=mid+1; //查找右半子表
}
}
for(j=i;j>low;j--){
array[j]=array[j-1]; //统一向后移动元素,空出插入位置
array[low]=flag; //插入flag中的元素
}
}
if((fp=fopen("./折半插入排序.txt","w"))==NULL)
printf("文件无法打开!");
else
{
for(i=0;i<NUM;i++)
{
fprintf(fp,"%d ",array[i]);
}
}
fclose(fp);
printf("写出数据成功!\n"); //写文件
if((fp=fopen("./折半插入排序.txt","r"))==NULL)
printf("文件无法打开!");
else
{
for(i=0;i<NUM;i++)
{
fscanf(fp,"%d ",&array[i]);
}
}
fclose(fp);
printf("读入数据成功!\n");
same();
t4=duration;
}
/*希尔排序的实质就是分组插入排序
基本思想:现将整个待排元素序列分割成若干个子序列(由相隔某个增量的元素组成)
分别进行直接插入排序,然后依次缩小增量再进行排序,待整个序列中的
元素基本有序(增量足够小时),再对全体元素进行一次直接插入排序。
因为直接插入排序在元素基本有序的情况下,效率是很高的,因此希尔排
序在时间效率上很高。
*/
/*希尔排序*/
void shell()
{
int i,j,d,x,n=NUM,a; //d表示增量
start = clock(); //开始计时
srand(time(NULL)); //初始化随机数
for(i=0;i<NUM;i++){
array[i]=rand()%1000+1;
}
d=n/2; //增量先取一半
while(d>=1) //当增量为1时退出循环
{
for(i=d;i<n;i++){
x=array[i];
j=i-d;
//进行直接插入排序
while(j>=0&&array[j]>x)
{
array[j+d]=array[j];
j=j-d;
}
array[j+d]=x; //保存数据
}
d=d/2; //增量减小2倍
}
if((fp=fopen("./希尔排序.txt","w"))==NULL)
{
printf("文件无法打开!\n");
}else{
for(i=0;i<NUM;i++){
fprintf(fp,"%d ",array[i]);
}
fclose(fp);
printf("写出数据成功!\n");
}
if((fp=fopen("./希尔排序.txt","r"))==NULL)
{
printf("文件无法打开!\n");
}else{
for(i=0;i<NUM;i++){
fscanf(fp,"%d ",&array[i]);
}
fclose(fp);
printf("读入数据成功!\n");
}
same();
t5=duration;
}
void display()
{
printf("\n\n\t\t***显示所有排序所用的时间***\n");
printf("\n\t\t冒泡排序所用时间为:%lf\n",t1);
printf("\n\t\t选择排序所用时间为:%lf\n",t2);
printf("\n\t\t插入排序所用时间为:%lf\n",t3);
printf("\n\t\t希尔排序所用时间为:%lf\n",t5);
printf("\n\t\t折半插入排序所用时间为:%lf\n",t4);
printf("\n\t\t请按任意键继续...\n");
getch();
}
void menu()
{
printf("\n\n\t\t**☆☆欢迎来到综合排序界面☆☆**\n");
printf("\t\t…………………………………………");
printf("\n\t\t1.冒泡排序(写入文件+运行时间)\n");
printf("\n\t\t2.选择排序(写入文件+运行时间)\n");
printf("\n\t\t3.插入排序(写入文件+运行时间)\n");
printf("\n\t\t4.希尔排序(写入文件+运行时间)\n");
printf("\n\t\t5.折半插入排序(写入文件+运行时间)\n");
printf("\n\t\t6.显示方法和所用时间\n");
printf("\n\t\t0.退出界面");
printf("\n\t\t…………………………………………\n");
printf("\t\t请选择操作数(0-6):");
}
/*选择菜单函数*/
void choice()
{
int key;
while(1){
menu();
scanf("%d",&key);
if(key<0||key>6){
printf("\t\t你输入有误,请重新输入!\n");
}else{
switch(key){
case 1:system("cls");
maopao();system("cls");
break;
case 2:system("cls");
xuanze();system("cls");
break;
case 3:system("cls");
insert();system("cls");
break;
case 4:system("cls");
shell();system("cls");
break;
case 5:system("cls");
binsertSort();system("cls");
break;
case 6:system("cls");
display();system("cls");
break;
case 0:exit(1);
break;
default:printf("选择操作数有误!\n");
break;
}
}
}
}
/*主函数*/
void main()
{
choice();
getch();
}
若有不足之处,请留言,感谢! 作者:C位出道、
