目录:
1、Hive 基本概述
-
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。
-
hive利用hdfs存储,利用mr查询,将sql转为mr程序执行,比mr开发效率高
-
构建在Hadoop之上的数据仓库;
使用HQL作为查询接口
使用HDFS存储
使用MapReduce计算
Hive本质是:将HQL转化成MapReduce程序
Hive的表其实就是HDFS上的目录和文件
灵活性和扩展性比较好:支持UDF,自定义存储格式等
适合离线数据处理
2、Hive 作用
用于解决海量结构化数据的统计工具
数据仓库工具
提供HQL查询
将提交的HQL语句,解析为mapreduce向yarn提交
使用HDFS存储数据,Hive表本质是HDFS的目录和文件
Hive的元数据存储在关系型数据库中 如:derby、MySQL
3、Hive体系结构如下:
1.Hive的数据存储基于Hadoop HDFS.
2.Hive没有专门的数据存储格式
3.存储结构主要包括:数据库、文件、表、视图、索引
4.Hive默认可以直接加载文本文件(TextFile),还支持 SequenceFile、RCFile
5.创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据
4、Hive 体系架构 图1.1
图1.1
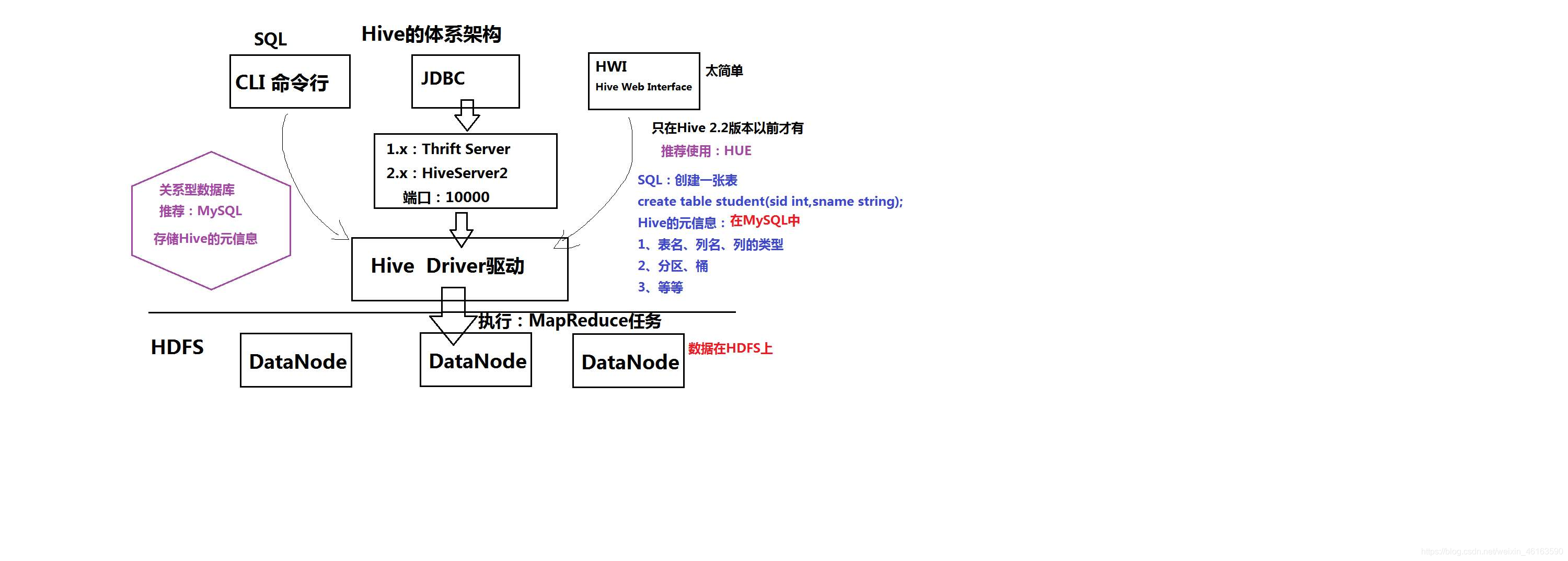
5、Hive驱动器:Driver
包含: 解析器 、编译器 、优化器、执行器、
1、解析器:将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库 完成,比如 antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误(比如 select中被判定为聚合的字段在group by中是否有出现);
2、编译器:将AST编译生成逻辑执行计划;
3、优化器:对逻辑执行计划进行优化;
4、执行器:把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/TEZ/Spark;
6、 Hive 优点与使用场景
1.操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手);
2.避免了去写MapReduce,减少开发人员的学习成本;
3.统一的元数据管理,可与impala/spark等共享元数据;
4.易扩展(HDFS+MapReduce:可以扩展集群规模;支持自定义函数);
5.数据的离线处理;比如:日志分析,海量结构化数据离线分析…
6.Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求不高的场合;
7.Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
同样一条数据 Maprucde和 Hive运行谁更快? Hive更快
因为Hive底层有解析器和优化器
7、hive中表的类型及区别
分为两种类型:外部表、内部表(受控表)
也是说在建外部表时加(EXTERNAL ) 关键字,内部表不加。
CREATE EXTERNAL TABLE test_db
内部表(受控表):当删除内部表的时候,hdfs上的数据以及元数据都会被删除。
外部表:当删除外部表的时候,HDFS上的数据不会被删除,但是元数据会被删除。
临时表(测试环境):在当前会话期间内存在,会话结束自动消失,生命周期随之session。
分区表:将一批数据分成多个目录来存储。(按日期、天数来分区)
分桶表:分桶也就是分区,分区数量等于文件数,(抽样查看数据)
8、Hive与RDBMS的区别:
1、hive存储的数据量比较大,适合海量数据,适合存储轨迹类历史数据,适合用来做离线分析、数据挖掘运算,
事务性较差,实时性较差
rdbms一般数据量相对来说不会太大,适合事务性计算,实时性较好,更加接近上层业务
2、hive的计算引擎是hadoop的mapreduce,存储是hadoop的hdfs文件系统,
rdbms的引擎由数据库自己设计实现例如mysql的innoDB,存储用的是数据库服务器本地的文件系统
3、hive由于基于hadoop所以存储和计算的扩展能力都很好,
rdbms在这方面比较弱,比如orcale的分表和扩容就很头疼
4、hive表格没有主键、没有索引、不支持对具体某一行的操作,适合对批量数据的操作,不支持对数据的update操作,
更新的话一般是先删除表然后重新落数据
rdbms事务性强,有主键、索引,支持对具体某一行的增删改查等操作
5、hive的SQL为HQL,与标准的RDBMS的SQL存在有不少的区别,相对来说功能有限
rdbms的SQL为标准SQL,功能较为强大。
6、Hive在加载数据时候和rdbms关系数据库不同,hive在加载数据时候不会对数据进行检查,也不会更改被加载的数据文件,而检查数据格式的操作是在查询操作时候执行,这种模式叫“读时模式”。在实际应用中,写时模式在加载数据时候会对列进行索引,对数据进行压缩,因此加载数据的速度很慢,但是当数据加载好了,我们去查询数据的时候,速度很快。但是当我们的数据是非结构化,存储模式也是未知时候,关系数据操作这种场景就麻烦多了,这时候hive就会发挥它的优势。
rdbms里,表的加载模式是在数据加载时候强制确定的(表的加载模式是指数据库存储数据的文件格式),如果加载数据
时候发现加载的数据不符合模式,关系数据库则会拒绝加载数据,这个就叫“写时模式”,写时模式会在数据加载时候对数据模式进行检查校验的操作。
最后做下总结:
HIVE是数据仓库适合存储历史的海量的数据,适合做批量和海量复杂运算,事务性差,运算时间长。
RDBMS是数据库,存储数据量偏小一些,事务性强,适合做OLTP和OLAP业务,运算时间短。
寄语专区:
《转载注明出处,你的点赞是我的动力。》

