本文配合"网易云课堂"周瑜老师的"Mysql索引底层原理"食用更加,附赠传送门:
https://study.163.com/course/courseMain.htm?courseId=1209598875 听过课之后感觉首页匪浅,感触良多。
个人整理,心得体会,欢迎讨论指导.
提起Mysql,"索引"这个名词肯定都磨烂大家的耳朵根了,自己理解不仅抽象而且无从下手,官方解释晦涩难懂;今天辫儿哥带你用大白话来聊聊啥是mysql(InnoDB引擎)的数据库索引奥~
什么是数据库
(身为程序猿,对于这个名词还是不理解的话,那么恭喜你!辫儿哥救不了你了,可以回炉重造了!!!)

索引在哪里?
在使用InnoDB数据库引擎创建数据表的时候,系统会自动根据给你生成一条索引~首先咱们来随便建一个表!
 够随便吧!只有一个ID主键及一个数字字段,就在这样一个普通的不能再普通的表中,系统其实已经为你建立了一条索引,那就是根据主键ID顺序排序的索引。
够随便吧!只有一个ID主键及一个数字字段,就在这样一个普通的不能再普通的表中,系统其实已经为你建立了一条索引,那就是根据主键ID顺序排序的索引。

看!神奇不神奇。
众所周知在一个表中没有任何排序查询限制的情况,这个表将会默认按照ID值的大小升序排列,这个默认排序的功能就是通过默认索引来实现的。
那么我们是不是可以得到一个很直接的结论,索引的第一个功能就是为表中指定的字段进行排序。
很好,就这样我们得到了索引的第一个性质,排序。

索引的排序性质
那么我们继续向下思考,为什么要进行排序?啥是数据库,这数据库这个东西不就是用来存放数据的么,你这我给你传啥数据你就往里写啥不就行了么?你这还自己给自己建立一个排序规则,这不是影响存储性能么?这说道这儿了就要开始研究一下数据库是怎么存放数据的。
任何事物存在的形式都离不开它专有的单位,数据库中的表也不例外。存放数据表的计量单位被称为页(Page) SQL Server 以页为单位分配数据库空间。系统默认的一页大小为4KB在 SQL Server 中,一页的大小为 8 KB。但是在基于InnoDB引擎的数据库一页大小可以达到16KB,光说肯定也不知道这玩意长啥样,那么看下面这张图,让你看看它真正的样子!

我们平时录入的数据就是通过这样的方式存储在表结构中的,图中的**“用户数据区域”**就是我们平时用于存放数据的地方;也就是在这个区域内,将数据按照默认主键索引的顺序进行排列。这里引入一个基本的概念要记住:我们日常使用的SQL语句是按照轮询的方式来进行查找的,也就是先从记录中去除一条数据值存入内存中,与你的查询条件进行比较,是则继续,不是则继续重复这个过程。(拓展:从硬盘读取到内存这样的一次操作过程,成为数据库的一次I/O)。
那么假设这个时候有这样的六条数据 111C,122C,133B,657E,199G,888T 存储在数据表中,
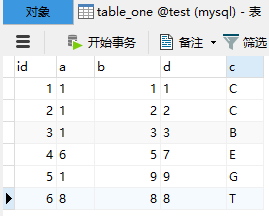
可以观察到他们本身是没有任何顺序可言,那么我们按照两种不同方式一种是InnoDB采用的主键索引排序制,一种是SQLServer默认填充存储来存储至我们的数据库中。

此时我们的数据已经存入,而此时有一个这样的查询条件,我要查询所有a字段小于2的数据。那么根据这两种查询方式就会形成两种截然不同的查询方式。

自行体会一下,当采用InnoDB主键索引排序录入数据表结构时,得到了查询条件,只需简单判断第一个字段符合条件即可终止查询。这种数据从左至右整体查找的方式我们称之为全表扫描。
但反观无顺序存储数据时,则需要把数据表中所有的数据都查询一遍最终才可以查询出所有负责查询条件值。我们这仅仅是六条数据,假设为几千条,万条,百万,千万级的数据库,那么采用右侧的查询方式是可以极大的提高查询效率的。
这也就是为什么索引,可以优化数据库查询性能的最根本原因。
SQL索引与B+树索引的关系
有了对数据库索引的第一个性质之后的认知,我们就可以进一步深入的向下学习了!(此处比较烧脑)

数据库的索引设计模式其实是参考了一种数学中索引结构,B+树。在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接。 例如:
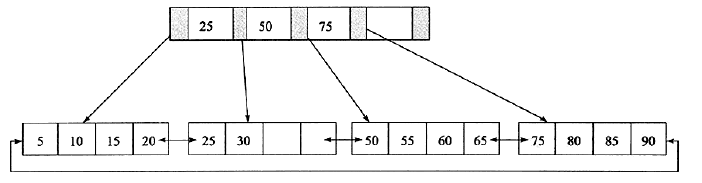
这是一个最标准的B+树索引模型,其高度为2,每页存放4条记录,扇出(fan out)为5。所有记录都在叶子节点上,并且是顺序存放的。对应了数据库中以下两点特性:
1,冗余:所有的非叶子节点都要冗余一份在上方节点(以便判断分支)。
2,指针:所有的叶子节点都要由一个指针与另一节点相互连接(以便回表查询)。
而数据库在进行存储时也是按照这种结构来存储的,结合数据,将其分为两组即可得到以下模型:

按照这个结构图来看,这就相当于B+树种的一个叶子节点,因为是按照顺序排放数据,所以将其按照四条数数据一组分为了两种。订端叶子节点记录的是下方两个子节点中数据的最小值,这样当有查询请求发送过来的时候,便可根据顶端叶子节点来判断走下方的两个分支中的某个分支。
例如查询一条结果为a = 4b便可根据顶端节点来判断,因为右侧入口最小值为5,所以查询条件不满足这个接口遍走向了左侧分支,查询到了需要的数组。
理解了这一方便后,我们又可以的出来了一条索引的性质:那就是数据库中的索引其实也是一种数据结构。
经过总结后得出以下结论:
索引是一个帮助快速查询的数据结构,其本质是数据结构。
而数据结构的目的是帮助我们更好的组合数组,以实现其主要功能“排序”。
其中:作为用户数据和索引数据存在一起称为“聚集索引”。
当用户在查找一条数据从左至右扫描的查找方式称之为“全表扫描”。
当用户在查找一条数据从上至下扫描的查找方式称之为“走索引”。
