关于特征值离散化的相关内容可以看机器学习面试题之机器学习基础(一)
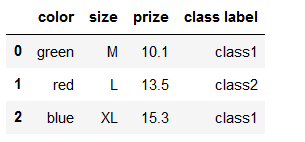
1.pandas进行特征离散处理
import pandas as pd
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
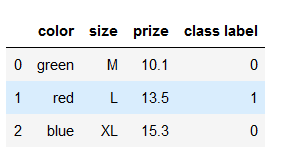
标签处理
通常会把字符型的标签转换成数值型的
class_mapping = {label:idx for idx,label in enumerate(set(df['class label']))}
print(class_mapping )
#{'class1': 0, 'class2': 1}
df['class label'] = df['class label'].map(class_mapping)
df
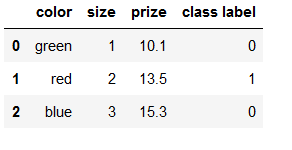
特征处理
对于特征来说,一般可以做一个映射的字典
size_mapping = {
'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].map(size_mapping)
df
还可以转换成编码
color_mapping = {
'green': (0,0,1),
'red': (0,1,0),
'blue': (1,0,0)}
df['color'] = df['color'].map(color_mapping)
df
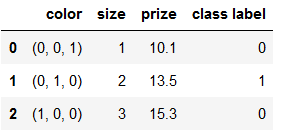
还原数据初始状态
inv_color_mapping = {v: k for k, v in color_mapping.items()}
inv_size_mapping = {v: k for k, v in size_mapping.items()}
inv_class_mapping = {v: k for k, v in class_mapping.items()}
df['color'] = df['color'].map(inv_color_mapping)
df['size'] = df['size'].map(inv_size_mapping)
df['class label'] = df['class label'].map(inv_class_mapping)
df
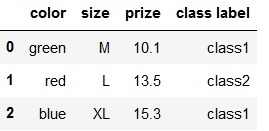
2.使用sklearn进行离散值处理的方式如下:
①.标签编码(LabelEncoder)
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'])
df
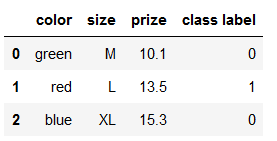
数据还原回去可以用inverse_transform :
class_le.inverse_transform(df['class label'])
②.特征向量化(DictVectorizer)
使用 DictVectorizer将得到特征的字典
df.transpose().to_dict().values()
dict_values([{'color': 'green', 'size': 'M', 'class label': 0, 'prize': 10.1}, {'color': 'red', 'size': 'L', 'class label': 1, 'prize': 13.5}, {'color': 'blue', 'size': 'XL', 'class label': 0, 'prize': 15.3}])
feature = df.iloc[:, :-1]
feature
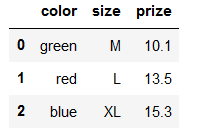
对所有的数据都做了映射
from sklearn.feature_extraction import DictVectorizer
dvec = DictVectorizer(sparse=False)
X = dvec.fit_transform(feature.transpose().to_dict().values())
X
#输出结果
array([[ 0. , 1. , 0. , 10.1, 0. , 1. , 0. ],
[ 0. , 0. , 1. , 13.5, 1. , 0. , 0. ],
[ 1. , 0. , 0. , 15.3, 0. , 0. , 1. ]])
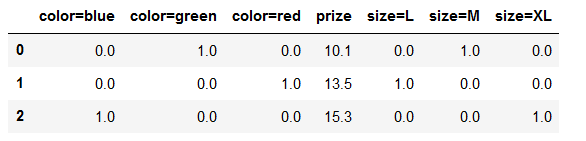
可以调用 get_feature_names 来返回新的列的名字,其中0和1就代表是不是这个属性。
pd.DataFrame(X, columns=dvec.get_feature_names())
③.独热编码(OneHotEncoder)
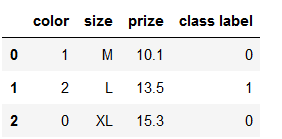
OneHotEncoder 必须使用整数作为输入,所以得先预处理一下
color_le = LabelEncoder()
df['color'] = color_le.fit_transform(df['color'])
df
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
X = ohe.fit_transform(df[['color']].values)
X
#输出结果
array([[ 0., 1., 0.],
[ 0., 0., 1.],
[ 1., 0., 0.]])
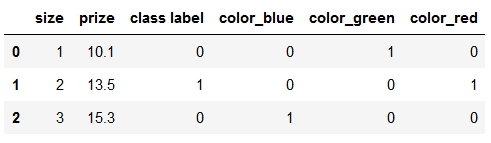
Pandas虚拟变量
Pandas库中同样有类似的操作,使用get_dummies也可以得到相应的特征
import pandas as pd
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
size_mapping = {
'XL': 3,
'L': 2,
'M': 1}
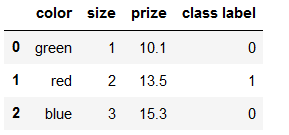
df['size'] = df['size'].map(size_mapping)
class_mapping = {label:idx for idx,label in enumerate(set(df['class label']))}
df['class label'] = df['class label'].map(class_mapping)
df
对整个DF使用get_dummies 将会得到新的列:
pd.get_dummies(df)