BP 训练中的实际问题
1. Review
- On-line learning = incremental learning
Off-line learning = Batch learning - BP 中的B为增益其中隐藏层的增益是根据输出层的增益算的
2. Practical issuses
2.1 Sequencial or random presentation
- Epoch 是训练的基础单元(即所有的训练单元跑一遍)
- 在一个训练中如果是incremental训练那么随机的example会有较好的结果
2.2 Initialization of Network
- 与其他的网络不同神经网络的初始状态时随机化的
- 网络的权重初始在-0.5到0.5的区间内
- 输入经常被标准化到0到1范围内
- 即使在一样的学习条件下由于初始权重的不同训练结果也会不同
- 合适的训练条件会让训练过程更快结果更好
2.3 Hidden Layers
- Additional layer 不会增加代表能力对于区分来说 representative power for discrimination.
- 两层的layer更强但是一层对于绝大多数问题都已经够用了并且更快
- 经验法则:
一层网络with n neural unit n=(input+output)/2
2.4 停止条件 Stopping Criteria
- RMS (root mean square) is lower at the threshold at the end of the epoch
- 最大的epoch数达到了
- 使用验证集较早停止
2.5 学习速率
- 学习速率太小会导致收敛过慢并且有可能调入局部最小挑不出来.
- 学习速率太大尽管进程很快但是结果更多的会在较差的结果间震荡.
- 所以我们要挑能使网络收敛的学习率中最大的,这样如果陷入局部最小值学习率大可能会帮助跳出或跳过低谷.
2.6 Momentum
- 动量是用于稳定权重的变化,通过梯度负方向与之前权重的变化组合实现
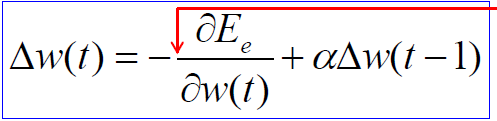
- 效果是使权重趋向于沿着之前改变的方向运行,若相同则相当于加大了学习速率,若相反则能使权重相对平稳不至于大幅度动荡.
- 注意若a=0 则和之前的完全相同(学习速率为1)
若a=1则权重前进方向完全取决去之前的方向不会有其他改变
a的值一般在0.6~0.9
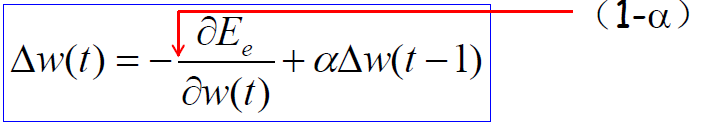
- Momentum 的 作用:
(1). 使权重的改变更为平滑, 去向错误山谷上的边到边震荡
(2). 当权重改变相同时动量增加了学习速率使收敛更快
(3). 使能够逃出局部最小值的陷阱(和较大的学习速率一个概念)
3. 泛化和过拟合 Generalization & Overfitting
3.1 基本介绍
- 泛化:
网络应该有能力把学到的东西应用到相似的问题上或所有数据上(all population) - 过拟合:
过拟合意味着训练数据的误差很小但是一个新的数据引入后相应的误差很高, 换言之网络记住了所有训练数据但是没学会怎么应用学到的东西.


左图是从训练数据层面看,右图是从network performance 方向看( 黄色的为测试集, 红色为训练集)
3.2 为什么过拟合
- Common reason: 自由参数的数量大于给定的训练数据

用尽量少的free parameters 去解决问题
用大小刚好的网络(足够拟合), 换言之不要在小的网络足够用的情况下用大的
3.3 怎么解决过拟合 Techniques to overcome overfitting
-
Weight Decay:

Large weights can hurt generalization in two different ways:
(1). 隐藏层的权重过大可能会导致输出函数粗略并且很有可能不连续
(2). 另外过大的隐藏层权重会导致输出很奇怪远超给定输入(如果激活不bounded)
最重要的原因是, 权重大会导致很多输出在激活函数的平滑区域(导数是0)没有学习意义
The main risk with large weights is that the non-linear node outputs could be in one of the flat parts of the transfer function, where the derivative is zero. In such case the learning is irreversibly stopped -
Validation:




