软件测试,爱码小哥邀你同行!
1. 背景
先来说说花椒测试平台的由来:
# 目的1,降低接口测试对测试人员代码能力的要求。测试人员只需要知道接口的url,请求参数,以什么样的格式传个服务端,接口的响应数据里需要验证哪个字段的值即可进行测试,而不需要知道怎么建一个工程,怎么建一个测试类,测试方法,testng是怎么使用的,结果怎么解析,怎么取到想要的字段去做判断。
# 目的2,可视化的case管理,执行,结果管理。打开一个浏览器,根据接口文档新建一个测试case,执行检查接口返回,保存case,建不同入参的该接口的case,组成case集,批量运行,查看运行结果,相比于工程执行批量case,testng的html结果,平台的集中展示更清晰。
# 既然接口的测试已经有case的信息了,对接口进行压测的请求其实也类似一个case,只不过是有很多人在同时执行这个case,所以有了压力测试和接口测试平台的整合。在平台建压测任务的时候选定一个测试用例为载体,多并发的执行case,统计压测数据,实时展示。以往接口测试和压力测试都是分别写一个方法,里面有很多重复的部分。
# 接下来我们会想,像接口测试是由数据驱动的,那么UI自动化是否可以理解为一种另类的驱动呢?UI操作的公共方法如点击,输入,检查元素的值,其实和接口入参和结果检查很像,基于cucumber我们将UI自动化集成进了测试平台,测试人员只需要关心我点击的是哪个页面的那个button或输入的内容,期望那个元素是什么展示即可,降低了测试人员的代码门槛,app页面发生变化时,case维护成本较原来的通篇代码修改有所降低。

2. 花椒测试平台整个框架
说了这么多,先来看看花椒测试平台的整个框架:
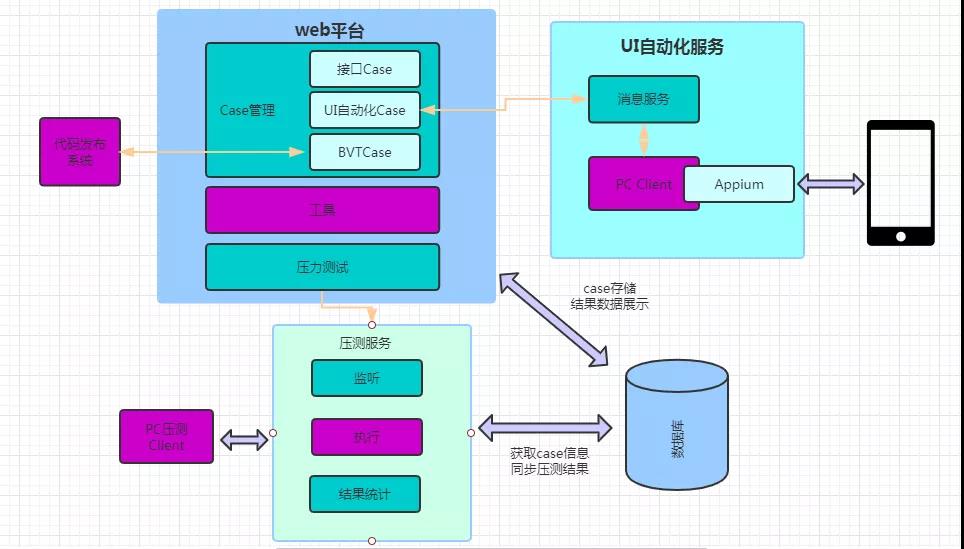
该框架主要由三大部分组成,今天主要介绍接口部分的一体化(接口测试+压力测试):
Web平台
Web平台是花椒测试平台的核心部分,主要是给测试开发人员提供可视化的界面操作,并封装为参数信息,调用后端的接口服务处理,展示处理结果给用户。后端采用Springboot + Mybatis框架,前端页面用jsp开发,后续UI自动化和部分工具的前端页面也有用vue框架开发,权限管理用的shiro,做好详细的权限管理,因为如果操作线上case,很有可能会对线上真实用户造成影响,所以线上case的权限只对部分人员开放,另外比如压测的功能,也需要做好权限管理,同时后端会记录每个用户的操作行为,便于追查。测试平台模块主要包含以下几个:
Case管理
Case管理部分,主要是管理包括接口case,场景case,bvtcase等的增加,修改,和在线执行
接口Case
case增加,删除,更新,另存为新用例,查找
case结构信息如下:
cases` ( 运行环境:测试环境,预发布,线上 模块:根据业务划分的模块 优先级:重要级别 Guid:特殊校验方式 参数格式:content-type和业务的结合,特殊的业务有特殊定义 用例名称,用例说明 url:接口url Token,请求头信息:请求头信息里的,Token标识用户 用例变量:抽取出来的变量,方便更改 请求参数:json结构体key-value的方式存储请求信息,后端请求的时候按参数个数组装 期望返回验证:对结果的校验,目前有等于,包含,自定义方法上线文验证等 )
以用户更新测试用例为例来看一下整个交互流程:
用户浏览器一个case,网页请求后端服务器,Shiro判断登陆状态跳转页面到第三方登陆,输入用户名密码后调第三方登陆服务,用户错误返回登陆失败,用户正确向数据库查询用户角色和权限,返回展示case页面及有权限的menu,用户修改case信息,编辑后点击保存,网页向服务器请求接口,服务器判断用户是否有访问权限,有权限则保存case更新到数据库,返回页面展示保存成功,没有权限则返回页面展示“保存失败,没有权限操作”
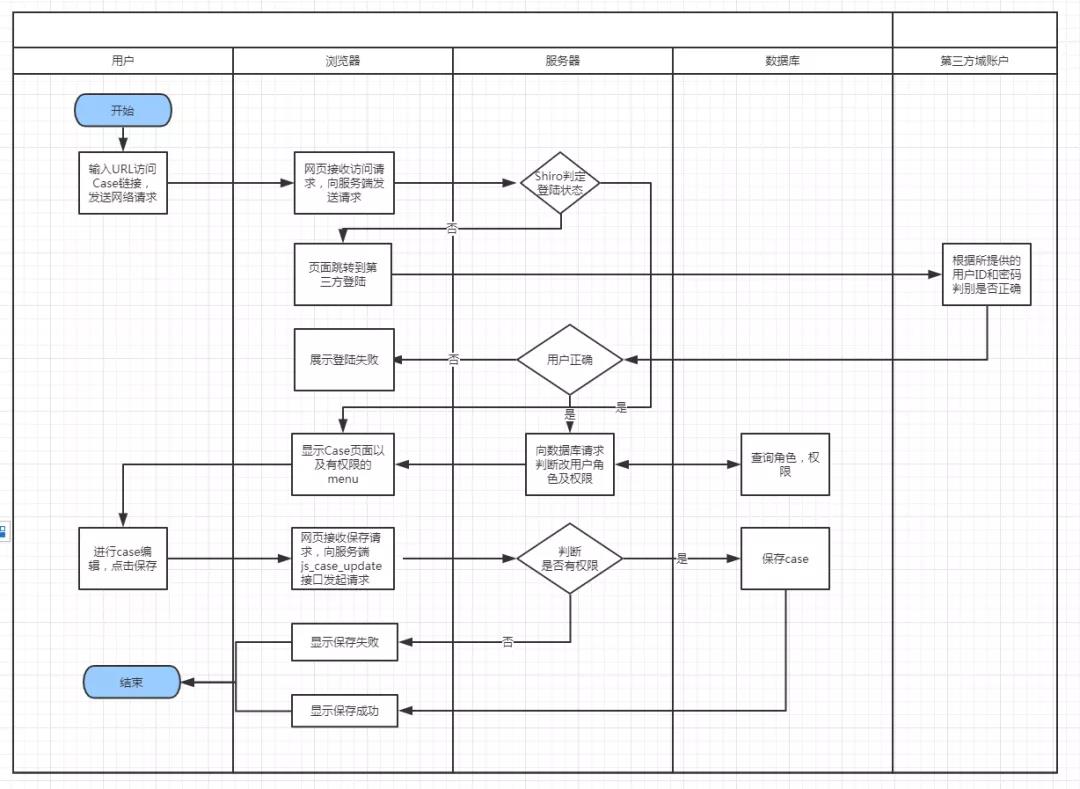
case测试执行
前端获取页面的case信息,URL,请求method,加解方式,参数,期望验证,以form的形式请求后端js_case_execute接口执行测试用例,服务器内部解析请求内容,调用case处理中心模块CaseRunner组装请求,向测试服务器发起请求,根据预设的断言,判断case的运行接结果,并将结果和服务器的返回组装成json格式返回给页面展示,页面的json展示用了开源的JSONFormatter.js (https://webscripts.softpedia.com/script/Development-Scripts-js/HTML-Tools/JSONFormatter-js-76391.html),能够根据各个层级展开和叠起,方便测试人员查看数据返回。js_case_excute实行如下:
@ResponseBody @RequestMapping(value = "/js_case_execute", method = RequestMethod.POST) public Response js_case_execute(Case hjcase, HttpServletRequest request) { RequestUtil.preResetField(request, hjcase); try { List<CaseResult> resultList = new ArrayList<CaseResult>(); CaseResult hjresult = new CaseResult(hjcase.getId(), hjcase.getCasename(), -1, ""); executeCase(hjcase, hjresult); resultList.add(hjresult); // 把该case加入我的常用case列表,方便使用 RedisService.addToMyFavCase(SecurityUtils.getSubject().getSession().getAttribute(Const.SESSION_USER), hjcase.getId() + "_" + hjcase.getCasename()); return new Response(resultList); } catch (ParamFormatException e) { //e.printStackTrace(); return new Response(1, e.getMessage()); } catch (Exception e) { e.printStackTrace(); return new Response(1, "Exception---" + e.getMessage()); } }
case批量运行
由于测试过程中经常会有制造批量数据,小并发运行的需求,并发支持对请求变量值设置数组运行,多线程随机或顺序取数组里的用户执行case,统计case耗时和平均响应时间,页面设置如下:

批量实现:
@ResponseBody
@RequestMapping(value = "case/batchExecCase")
public Response batchExecCase(Case hjcasesrc, HttpServletRequest request) {
RequestUtil.preResetField(request, hjcasesrc);
if (hjcasesrc.getCasetype() == 2) {
// suite case 只支持以数据库的为准
try {
List<Case> subCases = caseService.findByIds(hjcasesrc.getCaseids());
hjcasesrc.setSubCases(subCases);
} catch (Exception e) {
e.printStackTrace();
}
}
// 把需要批量运行是替换的参数解析,需多线程访问
Response response = new Response(); // response 传递为了返回运行时数据, 所有线程都共享该response,且可以修改其值, 不使用静态对象是因为多个并发请求会相互影响
try {
List<BatchKeyInfo> keyinfos = hjcasesrc.getBatchKeyInfos();
httpUtils utils = new httpUtils();
// 提前取用户登陆信息,获取出来, 都放入sampleList中,并且设置sampleType=2
for (BatchKeyInfo keyinfo : keyinfos) {
if (!keyinfo.isToken()) {
continue;
}
...//省略获取用户信息
break;
}
response.put(Response.TOTAL, totalBatch);
List<Thread> threadPool = new ArrayList<Thread>();
for (int i = 0; i < threadnum; i++) {
httpUtils httputils = new httpUtils();
CaseRunner runner = new CaseRunner(hjcasesrc, keyinfos, httputils, response);
runner.setRunTime(totalBatch);
Thread runnerThread = new Thread(runner);
threadPool.add(runnerThread);
}
long starttime = System.currentTimeMillis();
for (Thread worktask : threadPool) {
worktask.start();
worktask.join();
}
long endtime = System.currentTimeMillis();
float avgTPS = (float) totalBatch / ((endtime - starttime) / 1000.0f);
response.put("Comsume", endtime - starttime);
response.put("avgTPS", String.valueOf(avgTPS));
} catch (Exception e) {
e.printStackTrace();
}
return new Response(response.getResultJSON());
}
场景case
场景case来源于用户的一系列有联系的操作行为,比如用户A想要和主播B连麦,A先发起连麦,B主播同意,A用户同意,然后用户A和主播B连麦成功,这里面就有3个接口,一个是发起的apply接口,同意的accept接口,和开始连接的connect接口,所以组成这个场景的子case有三个,case1用户A发起apply,成功后返回申请的id传递给case2/case3, case2主播accept连麦, 请求的用户信息是主播B, case3用户B开始connect连麦。
执行的整个过程是,先抽取变量,执行case1,处理断言信息,赋值返回的申请id,然后执行case2,case2的传参申请id用case1返回的id同意申请,case3用case1的申请id开始连麦,整个过程的顺序必须是case1->case2->case3。场景 case存储时,抽离出每个case的用户信息,输入,期望判断信息,如“0”:values,组成一个大的jsonobject,case运行时,解析结构体,顺序执行,case的主数据库结果体信息如下:
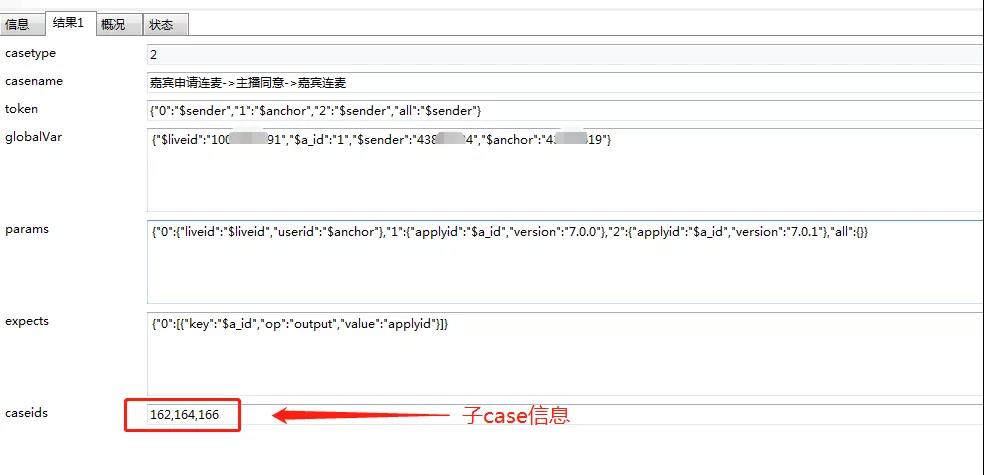
BVTCase集
BVTCase为各模块接口case集管理中心,case集可以共享请求服务器地址,用户等信息,case集内可以定义case的执行优先级,执行整个case集,查看执行结果,对外给发布系统提供查询,执行测试集的接口并返回结果给发布系统判断是否允许发布。另外也增加了crontab任务定期执行。
新建测试Suite,编辑测试Suite,编辑测试case顺序,执行测试Suite,批量执行测试Suite

对外代码发布系统获取测试Suite列表,指定测试Suite信息,调用测试Suite执行
-
inter/getSuiteLists获取测试集列表,可指定模块,如passport,live等
-
inter/getSuiteInfo获取指定id的suite信息,全部变量及各子case信息
-
inter/execSuiteList执行测试集,并返回测试集执行结果,成功失败,测试集的详细结果的访问方式
结果集,为测试suite执行的结果列表页面,记录执行结果,耗时已经执行人的信息:
结果集名称,总条数,成功条数,失败条数,状态(成功,失败),执行人
工具管理
平台工具管理中心,主要包含两种类型的工具,一种是jar包等上传可执行文件的工具,一种是在线使用工具:
可执行文件工具
平台支持添加脚本,上传jar包,指定传入的参数等,保存脚本信息,支持编辑更新,测试执行

在线使用的工具
该类工具如网页版的redis查询工具,byte string转换,数据清理等各种小工具,可以根据业务测试中的各种需求开发各种能提升效率的小工具,如下面这个byte string转换小工具,功能很简单,但解决了手工测试无法看到内容的困扰,提升了定位问题的效率

压力测试管理
压测场景
支持新建,更新压测场景,压测场景绑定已经建好的接口测试用例,修改用例变量值如用户id来实现多用户压测场景,压测场景包含的信息如下:
压测场景{
模块:选择压测场景属于的业务模块
用例id:选择压测的case
压测场景:压测的场景的名字
场景说明:该压测的信息说明,如多少个用户,多少并发
压测服务部署机器:部署压测服务的机器IP
启动线程个数:并发线程个数
运行次数:执行多少次case
发送间隔:每个线程每个请求处理完后的休息间隔(可为0)
用例变量:从选择的用例id里带过来的用例变量,便于压测过程中修改方便
压测参数:对用例变量进行取集合值,或从指定数值开始的多少个数,常用于多用户的场景压测
}
压测执行
点击启动压测任务
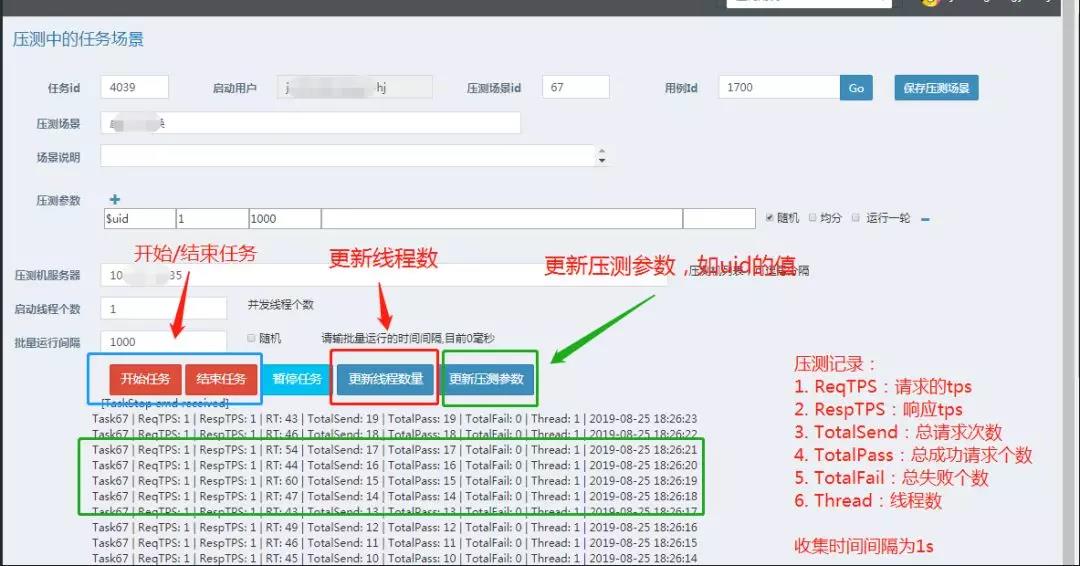
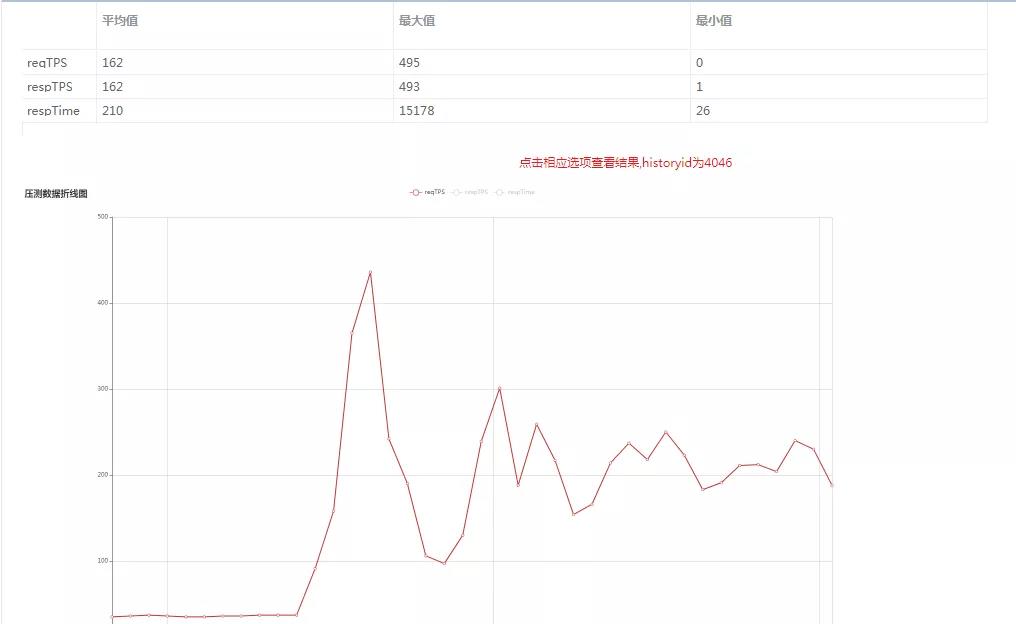
压测结果
点击结束任务时,当次压测的数据汇总回写到结果数据表,统计请求TPS(reqTPS),响应时间(respTime),响应TPS(respTPS)的最大最小值和平均值,以及总请求个数,以及失败的请求个数。
压测服务
压测服务是执行压力测试的中心服务,可以部署在任意可执行压测任务的服务器(有java环境即可),主要逻辑是监听从web,或者PC压测Client传过来的压测指令,根据执行获取压测信息,起线程进行压力测试,每秒统计一次压测数据,并将数据同步到数据库,供web平台展示查看实时压测结果并进行压测调整。

主要包含以下几个主要模块:
监听服务
监听服务是指启动一个socket server来监听指定端口,收到指令,为了保证安全性,先判断指令发送IP是否在白名单内,如不在,拒绝服务;解析命令内容,命令内容以TasK*开头,则代表从测试平台来的命令,执行相应操作,如启动任务,执行压测任务(CaseRunner分支),更新任务信息,结果任务等;如果命令内容直接以Start,任务名称等开头,则走自定义压测执行压测任务(WorkTask分支),自定义部分适合复杂场景和统计需求的压测。
...//以收到启动命令为例
if(cmd.equals("TaskStart")){ // 启动线程,初始化变量
int content = Integer.parseInt(params[1]); // 非结束状态,说明 可能有些初始化或销毁操作是需要进行的, 必须&& 非下面两种状态时处理
if(CommonTaskData.getSTATE() == CommonTaskData.RUNNING || CommonTaskData.getSTATE() == CommonTaskData.PAUSE) // 从 start 之后 还是start--
{
if(CommonTaskData.getId() == content) {
// 如果还是同一个task, 则只需重新更新一下task即可
CaseHelper casehelper = CaseHelper.getInstance(); StressTaskHistory taskhistory = casehelper.getTaskHistory(content); CommonTaskData.setTask(taskhistory.parseStressTask()); System.out.println("从暂停状态中恢复~~"); for(CaseRunner runner : caseRunners){ runner.setState(CommonTaskData.RUNNING);
}
CommonTaskData.setSTATE(CommonTaskData.RUNNING); continue;
} else{
System.out.println("不同TaskId Start ----先清理之前线程"); for(CaseRunner runner : caseRunners){
runner.setState(CommonTaskData.STOP);
}
for(Thread worktask : threadPool){// 等待3s的销毁时间 销毁原来的线程池
try {
worktask.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Statistics.startSampling(); //启动压测统计服务
...//准备压测执行的数据,读取case和task信息
//设置运行状态,启动线程
CommonTaskData.setSTATE(CommonTaskData.RUNNING);
for(int i =0; i < CommonTaskData.getThreadnum(); i++){
CaseRunner runner = new CaseRunner();
runner.setState(CommonTaskData.RUNNING);
Thread worktask = new Thread(runner);
threadPool.add(worktask);
caseRunners.add(runner);
worktask.start(); } }
...
压测任务处理
根据测试平台或PC client发过来压测任务,CaseRunner执行相应的case,并将请求的结果,如成功与否,请求的响应时间等发送给Statistic统计服务进行打点统计,目前CaseRunner执行方式的压测适用与web的http同步请求,而自定义压测方式的worktask则既可以定义同步的等待响应后发送下一个请求的方式;也可定义直接往服务器扔请求,异步接收线程处理响应结果及给Statistic统计服务发送打点数据。下面一CaseRunner同步执行的方式为例:
@Override
public void run() {
while(true)
{
...停止,暂停等状态,中断执行
casedata.copyFrom(CommonTaskData.getBasecase());
casedata.appendGlobalVar(varMap);
CaseResult caseresult = new CaseResult();
String actionName = "Task" + CommonTaskData.getTask().getId();
try {
Statistics.OnRequestSend(actionName);
long pre = System.currentTimeMillis();
utils.runCase(casedata, caseresult);
long after = System.currentTimeMillis();
//根据case执行成功失败,打点
if (caseresult.getStatus() == 1) {
Statistics.OnResponseRecv(actionName);
Statistics.onResponseTimeRecv(actionName, after - pre);
}
else{
Statistics.onFailedResp(actionName);
try{
if(casedata.getCasetype() == 1){
...//根据case里设置的断言,统计特殊需求的失败,总个数和失败请求的响应时间
}
}
catch(Exception e)
{
System.out.println("CaseRunner(114) - Exception-" + e.getMessage());
}
Logger.SysOutput("Fail:" + caseresult.getResult().toString());
}
} catch (Exception e) {
e.printStackTrace();
Logger.SysOutput("CaseRunner(123) - Exception:" + e.getMessage());
}
// 测试场景如果设置的发送间隔,则sleep
if(CommonTaskData.getSleeptime() > 0){
if(CommonTaskData.getSleepRan() == 1){
Tools.sleep(RamNum.GetRamInt(CommonTaskData.getSleeptime()));
}else{
Tools.sleep(CommonTaskData.getSleeptime());
}
}
}
}
Statistic压测结果统计
统计每秒的请求数,响应数,响应时间,失败数等,如果是平台的压测请求,将压测数据根据需求记入数据库,供web平台展示用,具体实现如下
@Override
public void run() {
long lastSampleTime;
while(!stopSample){
lastSampleTime = System.currentTimeMillis();
try{
Thread.sleep(samplePeriod);
Object[] actionNameSet = actions.keySet().toArray();
for(Object key : actionNameSet){
Action action = actions.get(key.toString());
if (!key.toString().startsWith("Task")) {
action.Sample(lastSampleTime);//统计请求信息,并打印
action.SampleResponseTime(lastSampleTime);//统计响应时间信息,并打印
} else {
action.SampleRedis(lastSampleTime);//统计请求信息,响应,打印并存库
}
}
}catch(InterruptedException e){
System.out.println("Sample thread stop for interrupted exception.");
break;
}
}
}
后续计划
目前测试平台只集成了自动化测试的基本功能,在持续集成上的应用还需要丰富起来,另外作为一个质量管理平台,对提测->测试 -> 测试bug记录->测试结果->上线的整个过程并没有完整的整合起来,也是我们后续需要完善的地方。