在使用Docker容器来部署应用时大部分情况下都是在一个容器中只部署一个应用程序,比如很多情况下服务A和服务B,或者应用和数据库都存在于不同的容器中,这就涉及到了容器网络模式与容器间连接相关的内容。在Linux系统中是通过network namespace来进行网络隔离,运行在Liunx中的Docker亦是如此。对于网络一个network namespace提供一个完全独立的网络,当然这是在宿主机中虚拟出的环境,包括独立的IP、端口、路由表和防火墙等等。这样Docker就可以通过这种方法为每个容器提供一份独立的网络配置。Docker中提供了多种网络模式,在研究这些网络模式之前,我们先看下Linux中如何创建虚拟网络并通信。
引例实验1:创建虚拟网络并通信
本实验主要参照参考文献[3]的博文。在linux系统中创建两个虚拟网络并使之能够连接到彼此,实验的操作环境是Ubuntu主机。
使用命令 ip netns ls 或 ip netns list 可查看当前的network namespace列表。
创建第一个network namespace命名为ns1
~$ sudo ip netns add ns1 ~$ sudo ip netns list ns1
查看ns1虚拟网卡信息,当前状态为Down,表示该网卡尚未启动
~$ sudo ip netns exec ns1 ip a 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
启动ns1中这个虚拟网卡lo
~$ sudo ip netns exec ns1 ip link set lo up
之后再查看ns1中的网卡信息,现在状态变为UNKNOWN,网卡的本地回环地址为127.0.0.1/8
~$ sudo ip netns exec ns1 ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever
使用上面同样的流程创建另一个network namespace命名为ns2并启动lo。
在Linux中提供了一种 Virtual Ethernet Pair 的技术用来创建网络连接接口,接口都是成对创建的。创建完成后的veth-ns1与veth-ns1分别放在两个network namespace中,向veth-ns1中发送数据包便可以在veth-ns1中收到包数据,这样两个namespace下便可以实现通信了。如同veth-ns1和veth-ns2这种对子称为 veth pair 。
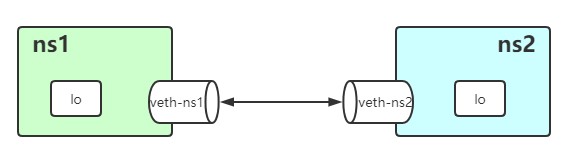
创建 veth pair
~$ sudo ip link add veth-ns1 type veth peer name veth-ns2
查看当前的link,可以看到刚刚创建的 veth pair
~$ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:08:39:2b brd ff:ff:ff:ff:ff:ff 3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 02:42:3c:aa:35:f0 brd ff:ff:ff:ff:ff:ff 5: vethc81c504@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default link/ether 9a:6d:d1:c1:30:ec brd ff:ff:ff:ff:ff:ff link-netnsid 0 6: veth-ns2@veth-ns1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether d2:c2:5f:2f:91:3b brd ff:ff:ff:ff:ff:ff 7: veth-ns1@veth-ns2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 8a:36:d3:11:7b:33 brd ff:ff:ff:ff:ff:ff
把虚拟网卡veth-ns1加到ns1中,将veth-ns2加到ns2中
~$ sudo ip link set veth-ns1 netns ns1 ~$ sudo ip link set veth-ns2 netns ns2
查看ns1上的虚拟网卡信息,发现多出一个 veth-ns1@if6 。
~$ sudo ip netns exec ns1 ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 7: veth-ns1@if6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 8a:36:d3:11:7b:33 brd ff:ff:ff:ff:ff:ff link-netnsid 1
同样查看ns2上的虚拟网卡信息,发现多出一个 veth-ns2@if7 。
~$ sudo ip netns exec ns2 ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 6: veth-ns2@if7: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether d2:c2:5f:2f:91:3b brd ff:ff:ff:ff:ff:ff link-netnsid 0
启动这两个虚拟网卡
~$ sudo ip netns exec ns1 ip link set veth-ns1 up ~$ sudo ip netns exec ns2 ip link set veth-ns2 up
为两个网卡分配IP地址。
~$ sudo ip netns exec ns1 ip addr add 192.168.0.11/24 dev veth-ns1 ~$ sudo ip netns exec ns2 ip addr add 192.168.0.12/24 dev veth-ns2
现在再来查看下ns1中的网卡的信息,已得到我们分配的IP地址。
~$ sudo ip netns exec ns1 ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 7: veth-ns1@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 8a:36:d3:11:7b:33 brd ff:ff:ff:ff:ff:ff link-netnsid 1 inet 192.168.0.11/24 scope global veth-ns1 valid_lft forever preferred_lft forever inet6 fe80::8836:d3ff:fe11:7b33/64 scope link valid_lft forever preferred_lft forever
现在使用ns1去ping一下ns2可以发现已经可以连接上了。
ns1去连接ns2 :~$ sudo ip netns exec ns1 ping 192.168.0.12 PING 192.168.0.12 (192.168.0.12) 56(84) bytes of data. 64 bytes from 192.168.0.12: icmp_seq=1 ttl=64 time=0.037 ms 64 bytes from 192.168.0.12: icmp_seq=2 ttl=64 time=0.049 ms 64 bytes from 192.168.0.12: icmp_seq=3 ttl=64 time=0.031 ms
引例实验2:创建Bridge
上面通过创建 veth-pair 连接两个network namespace的网络,相当于是使用了一根网线直接插在两台电脑的网口上进行连接。但是要搭建起一个局域网络,存在多台主机需要通信通常的做法可不是用网线对插了,而是会使用到交换机。在Linux中 bridege 的功能就类似于我们的交换机功能。接下来试着创建Bridge并连接两个网卡。首先创建3个namespace,其中 bridge 便是随后要作为交换机的namespace。
~$ sudo ip netns add ns3 ~$ sudo ip netns add ns4 ~$ sudo ip netns add bridge ~$ ip netns ls bridge ns4 ns3 ns2 (id: 2) ns1 (id: 1)
创建一对 veth-pair
~$ sudo ip link add type veth
~$ ip link ... ... 8: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether c2:aa:ec:3f:db:7d brd ff:ff:ff:ff:ff:ff 9: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether ca:aa:3f:60:2c:2d brd ff:ff:ff:ff:ff:ff
看到生成veth0和veth1,现在我们将veth0这头“插”到ns3中,将veth1这头“插”在bridge上
~$ sudo ip link set dev veth0 name ns3-bridge netns ns3 ~$ sudo ip link set dev veth1 name bridge netns bridge #这里应该将bridge上的网卡命名为“bridge-ns3”更贴切一点
接着对ns4进行类似的操作
~$ sudo ip link add type veth ~$ sudo ip link set dev veth0 name ns4-bridge netns ns4 ~$ sudo ip link set dev veth1 name bridge-ns4 netns bridge
查看ns3上的网卡和bridge上的网卡。
~$ sudo ip netns exec ns3 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 8: ns3-bridge@if9: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether c2:aa:ec:3f:db:7d brd ff:ff:ff:ff:ff:ff link-netnsid 1 ~$ sudo ip netns exec bridge ip a 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 9: bridge@if8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether ca:aa:3f:60:2c:2d brd ff:ff:ff:ff:ff:ff link-netnsid 0 11: bridge-ns4@if10: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 02:cb:c9:5b:10:8d brd ff:ff:ff:ff:ff:ff link-netnsid 1
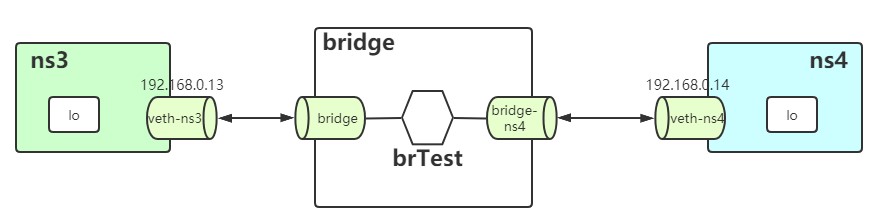
现在的连接情况如下图所示

在bridge这个namespace中创建网桥设备(br)并启动来使其变成我们的“交换机”。
~$ sudo apt-get install bridge-utils #安装工具 ~$ sudo ip netns exec bridge brctl addbr brTest #创建网桥 ~$ sudo ip netns exec bridge ip link set dev brTest up #启动网桥
启动bridge上的两个网卡 bridge 和 bridge-ns4
~$ sudo ip netns exec bridge ip link set dev bridge up ~$ sudo ip netns exec bridge ip link set dev bridge-ns4 up
把bridge上的两个网卡 bridge 和 bridge-ns4 连到网桥br上
~$ sudo ip netns exec bridge brctl addif brTest bridge ~$ sudo ip netns exec bridge brctl addif brTest bridge-ns4
启动ns3和ns4中的两个网卡并分配IP地址
~$ sudo ip netns exec ns3 ip link set dev ns3-bridge up ~$ sudo ip netns exec ns3 ip address add 192.168.0.13/24 dev ns3-bridge ~$ sudo ip netns exec ns4 ip link set dev ns4-bridge up ~$ sudo ip netns exec ns4 ip address add 192.168.0.14/24 dev ns4-bridge
当前示意图
测试连接,成功。
~$ sudo ip netns exec ns3 ping 192.168.0.14 PING 192.168.0.14 (192.168.0.14) 56(84) bytes of data. 64 bytes from 192.168.0.14: icmp_seq=1 ttl=64 time=0.045 ms 64 bytes from 192.168.0.14: icmp_seq=2 ttl=64 time=0.060 ms 64 bytes from 192.168.0.14: icmp_seq=3 ttl=64 time=0.043 ms 64 bytes from 192.168.0.14: icmp_seq=4 ttl=64 time=0.059 ms
Docker中的网络模式
在进行了上述的实验后对理解Docker的网络模式会有很好的帮助,在Docker中提供了5中网络模式分别是
- bridge模式
§ 默认模式,如果启动容器时不指定任何网络模式,就会使用默认bridge模式。这种模式下Docker会为所有容器分配一个独立的网络,并将所有这些网络并到一个网桥上。这种模式常用在独立容器间通信的情形。 - host模式
§ 去除容器与宿主机器的网络隔离,容器直接使用宿主的网络,也就是说容器与主机在同一个network namespace下,并且Docker也不会为容器再虚拟出网络环境相关的配置。 - overlay模式
§ 若已经存在了一个容器,那么新创建的容器使用此模式可以让其与使用已存在的这个容器的网络,新创建的容器Docker将不会再为其虚拟网络环境。共享了网络的两个容器可以使用lo网卡(回环网络)通信。 - macvlan模式
§ 这种模式下可以让你为容器分配mac地址。 - none模式
§ 这种模式下每个容器拥有自己的network namespace,但是Docker不会为容器配置网络信息,需要我们自己来为容器配置网络。
bridge模式
当我们启动Docker时,Docker会帮我们自动创建一个默认的网桥网络命名为bridge。在启动容器时如果不显式的指定网络模式,则都会采用bridge模式,容器拥有自己独立的network namespace并通过veth pair连接上默认bridge网络上的虚拟网桥。这个虚拟网桥默认叫docker0,就象是这个网络的交换机,每个使用默认bridge网络的容器都连到这部交换机上。当然用户也可以自己自定义网桥网络并供容器连接,自定义的网桥网络的优先级是高于默认的网桥网络的。我们先来研究一番bridge模式下的工作原理。
首先我们通过命令查看下Docker默认创建的网络列表,可以看到其中已经包含了我们说的默认的bridge。
> docker network ls NETWORK ID NAME DRIVER SCOPE 366865106dfe bridge bridge local c9f4882bd348 host host local ddbca9f4bc4a none null local
我们启动一个容器并命名为server1,并使用端口映射将容器的8081端口映射到主机的8080端口,随后查看容器的网络信息,可以看到一个已开启并已分配了IP的虚拟网卡。
> docker run -t -i --rm -p 8081:8080 --name server1 ubuntu # apt-get update # apt-get install iproute2 /# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 3: ip6tnl0@NONE: <NOARP> mtu 1452 qdisc noop state DOWN group default qlen 1000 link/tunnel6 :: brd :: 6: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
接着再启动第二个容器命名为server2,同样使用端口映射。检查server2的网络信息可发现情况和server1类似。
> docker run -t -i --rm -p 8082:8080 --name server2 ubuntu # apt-get update # apt-get install iproute2 /# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 3: ip6tnl0@NONE: <NOARP> mtu 1452 qdisc noop state DOWN group default qlen 1000 link/tunnel6 :: brd :: 8: eth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
可以看到两个 server1 和 server2 的两个网卡是 eth0@if7 和 eth0@if9,这两个虚拟网卡不是连续的说明不是一对veth pair,不能直接通信,而是通过bridge间接连接的。
我们查看下宿主机(若window系统上便是Docker Desktop在Hyper-V中启动的Linux虚拟机)上的网卡信息。
/ # ip a … … 4: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN group default qlen 1000 link/ether 02:50:00:00:00:01 brd ff:ff:ff:ff:ff:ff inet 192.168.65.3/28 brd 192.168.65.15 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::50:ff:fe00:1/64 scope link valid_lft forever preferred_lft forever 5: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:b9:5f:a1:6d brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:b9ff:fe5f:a16d/64 scope link valid_lft forever preferred_lft forever 7: veth2ee4a60@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default link/ether 72:95:52:63:55:45 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet6 fe80::7095:52ff:fe63:5545/64 scope link valid_lft forever preferred_lft forever 9: veth79a9b67@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default link/ether 32:d3:5f:94:24:fc brd ff:ff:ff:ff:ff:ff link-netnsid 1 inet6 fe80::30d3:5fff:fe94:24fc/64 scope link valid_lft forever preferred_lft forever
可以看到Docker默认创建的docker0,就类似我们在前面实验2中创建的bridge。并看到server1和server2的veth-pair的“另一半”。
使用Docker的命令可以查看到接入到默认网桥网络bridge的容器server1和server2。
> docker network inspect bridge … … "Containers": { "058a70d5ebe51d97f9810cb4b5ec17df82668ba7b09a3bb906d52d79fee0c659": { "Name": "server1", "EndpointID": "38986e3b75ab68f0c2aeb32773512149c52eaea7988f4e0d9965f3d08a6d2dda", "MacAddress": "02:42:ac:11:00:02", "IPv4Address": "172.17.0.2/16", "IPv6Address": "" }, "6c7215c324a993134945d8ba965800bf421715df750eca190940fce5fadbe7fa": { "Name": "server2", "EndpointID": "d648e845488f48df36dac6c8cf3214ff4acf99a4989a2f947e61e2eedc3675b7", "MacAddress": "02:42:ac:11:00:03", "IPv4Address": "172.17.0.3/16", "IPv6Address": "" } } … …
试下使用server1容器连接server2容器,发现可以ping通server2的IP地址。同样的server2也可以ping到server1的IP。但是直接server1直接ping容器server2的容器名是ping不通的。
/# ping 172.17.0.3 PING 172.17.0.3 (172.17.0.3) 56(84) bytes of data. 64 bytes from 172.17.0.3: icmp_seq=1 ttl=64 time=0.061 ms 64 bytes from 172.17.0.3: icmp_seq=2 ttl=64 time=0.040 ms 64 bytes from 172.17.0.3: icmp_seq=3 ttl=64 time=0.044 ms ^C --- 172.17.0.3 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2077ms rtt min/avg/max/mdev = 0.040/0.048/0.061/0.009 ms
如果你的主机可以访问外网的话,主机中的Docker容器也是可以访问外网的。
/# ping google.com PING google.com (216.58.197.110) 56(84) bytes of data. 64 bytes from 216.58.197.110 (216.58.197.110): icmp_seq=1 ttl=37 time=11.8 ms 64 bytes from 216.58.197.110 (216.58.197.110): icmp_seq=2 ttl=37 time=21.0 ms
我们在宿主机(Windows下是Linux虚拟机)上查看iptables的规则可以看到存在多出这几条。
# iptables -t nat -S -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE-A DOCKER ! -i docker0 -p tcp -m tcp --dport 8081 -j DNAT --to-destination 172.17.0.2:8080 -A DOCKER ! -i docker0 -p tcp -m tcp --dport 8082 -j DNAT --to-destination 172.17.0.3:8080
说明将源地址为172.17.0.0/16的包(Docker容器发出的包),并且不是从docker0网卡发出的,进行源地址转换,转换成主机网卡的地址。
另外的两个规则可以看出,由于我们在启动容器时进行了端口映射,对eth0收到的目的端口为8081或8082的tcp流量进行DNAT转换,将流量发往172.17.0.2:8080或者172.17.0.3:8080也就是server1或server2容器。
在bridge模式下除了使用默认的桥接网络bridge外,我们也可以自定义桥接网络并让容器连接上来。
创建自定义的bridge network。
> docker network create --driver bridge demo-net
0eb15c4cfa0138e9d2234b58bef032b26cbb0635c855a7645c63cf1ad0127a73
> docker network ls
NETWORK ID NAME DRIVER SCOPE 366865106dfe bridge bridge local 0eb15c4cfa01 demo-net bridge local c9f4882bd348 host host local ddbca9f4bc4a none null local
检视下demo-net的网络信息可以看到IP等,当前还没容器连上所以Containers中是空的。
> docker network inspect demo-net [ { "Name": "demo-net", "Id": "0eb15c4cfa0138e9d2234b58bef032b26cbb0635c855a7645c63cf1ad0127a73", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "172.18.0.0/16", "Gateway": "172.18.0.1" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": {}, "Options": {}, "Labels": {} } ]
创建两个测试容器连上我们自定义的网络demo-net。Docker中在创建容器时使用 --network 来指定容器的网络。
> docker run -dit --name demoC1 --network demo-net alpine ash
a0efcb9108c9ea55e6eb54d8c01f6ce687fad7fd02796e17d13e7a476c79c1c7 > docker run -dit --name demoC2 --network demo-net alpine ash
2f49f11c443bd5c466070467c6b7788be6ab3deaba0dc87c6f615b3615b20ca5
> docker network inspect demo-net [ ... ..."Containers": { "2f49f11c443bd5c466070467c6b7788be6ab3deaba0dc87c6f615b3615b20ca5": { "Name": "demoC2", "EndpointID": "4a121a78efe9849ebf37667c595b7740650850a7f0324342b39c17d0e4ea766a", "MacAddress": "02:42:ac:12:00:03", "IPv4Address": "172.18.0.3/16", "IPv6Address": "" }, "a0efcb9108c9ea55e6eb54d8c01f6ce687fad7fd02796e17d13e7a476c79c1c7": { "Name": "demoC1", "EndpointID": "889ffd05fcf772ad5d07fa068ed91ac5f5f1f547f7f9935dc41a45d4fc3eeef4", "MacAddress": "02:42:ac:12:00:02", "IPv4Address": "172.18.0.2/16", "IPv6Address": "" } }, ... ...
这是再检查demo-net时可看到Containers中多出了“demoC1”和“demoC2”。接下来我们测试下这两个容器的通信,值得注意的是这次我们并非使用IP地址而是使用容器的名称。
> docker container attach demoC1
/ # ping -c 2 demoC2 PING demoC2 (172.18.0.3): 56 data bytes 64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.100 ms 64 bytes from 172.18.0.3: seq=1 ttl=64 time=0.078 ms --- demoC2 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.078/0.089/0.100 ms
如果没有在容器创建时通过 --network 指定网络,可以使用Docker命令 docker network connect <network> <container> 将容器加入网络,使用命令 docker network disconnect <network> <container> 将容器移除该网络。
> docker run -dit --name demoC3 alpine ash
a9188e57c0ffb84dae344b8ef8d6953229ba8404498434d8a2bcfa3258881137 > docker network connect demo-net demoC3 # 将demoC3加入网络demo-net > docker container inspect demoC3 # 检视容器demoC3,可看到连上了两个网络,默认的bridge和后加的demo-net ... ... "Networks": { "bridge": { "IPAMConfig": null, "Links": null, "Aliases": null, "NetworkID": "bc461594e771ba255f2feade7acdc8d44c92698266966e3e85c75e908e1dcc13", "EndpointID": "1463e6457be98038f50749ee0ad7fd0989ed5a810ed27f04597831efe66cad3d", "Gateway": "172.17.0.1", "IPAddress": "172.17.0.2", "IPPrefixLen": 16, "IPv6Gateway": "", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "MacAddress": "02:42:ac:11:00:02", "DriverOpts": null }, "demo-net": { "IPAMConfig": {}, "Links": null, "Aliases": [ "a9188e57c0ff" ], "NetworkID": "0eb15c4cfa0138e9d2234b58bef032b26cbb0635c855a7645c63cf1ad0127a73", "EndpointID": "2c175f500d410134284cb848b0bfcdd2cbf005a675de8eb1a1f4e56acc0c7231", "Gateway": "172.18.0.1", "IPAddress": "172.18.0.2", "IPPrefixLen": 16, "IPv6Gateway": "", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "MacAddress": "02:42:ac:12:00:02", "DriverOpts": {} }
... ...
用户自定义的网络和默认网桥网络bridge存在以下区别。
- 如果容器使用默认的网桥bridge,那么容器之间通信只可以通过IP地址,或者我们为其指定--link参数。然后--link用法Docker官方已经表明为过时并不建议使用了,用法可参考这里。而用户定义的网桥自带DNS解析,所以容器间除了可以通过IP还可以通过容器名来相互访问。
- 使用自定义的网桥可以做到更好的网络隔离,我们可以将容器通过--network指定网桥将需要通信的容器放在一个网络下,有点类似分组。不需要通信的容器嫁接在不同网桥上,避免发生不必要的连接而产生无法预知的问题。
- 使用自定义的网桥,可以在容器运行的时候使其从网桥上断开或连接上一个我们定义的网桥。而默认的bridge网桥想要做到这一点必须先停掉容器。
- 使用自定义网桥可以更加灵活的配置,针对不同的容器使用不用的配置。并且修改默认bridge网桥的配置时需要将Docker重启。
bridge模式下容器连接
了解了bridge模式的工作原理后我们试着将ASP.NET Core应用容器化部署并通信。实验通过两个简单的ASP.NET Core Web应用(一个为MVC项目一个为WebApi项目),MVC通过HttpClient访问WebApi来获取数据并在页面上显示出来。
我们设定两个web应用的运行端口都为80端口。有两种方法可以修改默认端口,第一中是修改代码,在Program.cs中增加 UseUrls 方法。
1 public static IHostBuilder CreateHostBuilder(string[] args) => 2 Host.CreateDefaultBuilder(args) 3 .ConfigureWebHostDefaults(webBuilder => 4 { 5 webBuilder.UseUrls("http://*:80") #设置启动的端口 6 .UseStartup<Startup>(); 7 });
另外一种是设置环境变量,这个环境变量我们可以在项目的Dockerfile中增加环境变量 ASPNETCORE_URLS 并赋值,也可在docker启动容器时指定环境变量
FROM base AS final WORKDIR /app COPY --from=publish /app/publish . ENV ASPNETCORE_URLS http://+:80 ENTRYPOINT ["dotnet", "ASP.NET Core3.x MVC Demo.dll"]
我们的MVC项目使用HttpClient来向WebApi项目发送请求,我采用的是从配置中设置WebApi的uri。以下是在Startup.cs中ConfigureServices方法中注册HttpClient时的代码。
1 //从配置中读取WebApi的地址 2 services.AddHttpClient<DemoApiHttpClient>(client => 3 { 4 client.BaseAddress = new Uri(Configuration["DemoApiUri"]); 5 });
由于我们将要将两个Web应用的容器加入到自定义bridge网络中,这样我们就可以使用容器名来作为地址进行请求了,所以在配置中WebApi的地址是这么写的。
"DemoApiUri": "http://webapidemo:80"
接下来我们来构建这两个应用的镜像,构建镜像的方法就不在本文赘述了,可参考上一篇文章。关于本项目代码我上传在GitHub上:https://github.com/Xuhy0826/ASP.NET-Core3.x-Demo
打开powershell并cd到解决方案根目录下,执行build命令,创建webapi项目的镜像。
> docker build -f "${pwd}\ASP.NET Core3.x WebApi Demo\Dockerfile" --force-rm -t mark826/demo.aspnetcore/webapi:v520 .
接着build mvc项目的镜像。
> docker build -f "${pwd}\ASP.NET Core3.x MVC Demo\Dockerfile" --force-rm -t mark826/demo.aspnetcore/mvc:v520 .
接着使用这两个镜像创建容器,使用我们创建的“demo-net”网络。并且将mvc应用的容器的80端口映射到主机的8081端口上。
> docker run -dt --network demo-net --name webapidemo mark826/demo.aspnetcore/webapi:v520 > docker run -dt --network demo-net -p:8081:80 --name mvcdemo mark826/demo.aspnetcore/mvc:v520
> docker ps CONTAINER ID IMAGE COMMAND PORTS NAMES 703d48ac965a mark826/demo.aspnetcore/mvc:v520 "dotnet 'ASP.NET Cor…" 0.0.0.0:8081->80/tcp mvcdemo bd81fe720e8f mark826/demo.aspnetcore/webapi:v520 "dotnet 'ASP.NET Cor…" 80/tcp webapidemo
容器启动成功后我们在浏览器上打开mvc地址。如下图,可以看到mvc项目已从webapi中获取了数据。
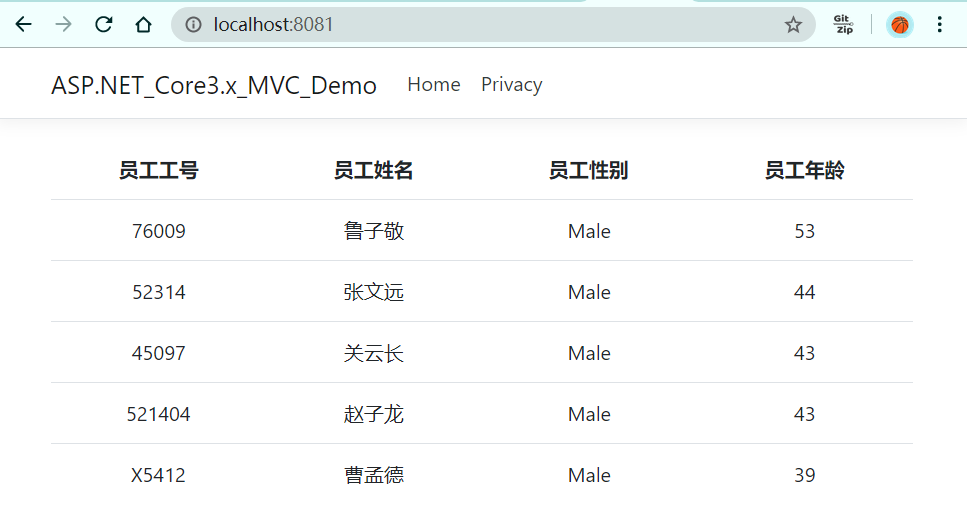
我们查看一下mvc容器的日志,注意下面加粗的日志段,打出了mvc请求的地址为“http://webapidemo/api/employees”,访问的是容器名称而非IP。
> docker logs mvcdemo info: Microsoft.Hosting.Lifetime[0] Now listening on: http://[::]:80 info: Microsoft.Hosting.Lifetime[0] Application started. Press Ctrl+C to shut down. info: Microsoft.Hosting.Lifetime[0] Hosting environment: Production info: Microsoft.Hosting.Lifetime[0] Content root path: /app info: System.Net.Http.HttpClient.DemoApiHttpClient.LogicalHandler[100] Start processing HTTP request GET http://webapidemo/api/employees info: System.Net.Http.HttpClient.DemoApiHttpClient.ClientHandler[100] Sending HTTP request GET http://webapidemo/api/employees info: System.Net.Http.HttpClient.DemoApiHttpClient.ClientHandler[101] Received HTTP response after 556.1971ms - OK info: System.Net.Http.HttpClient.DemoApiHttpClient.LogicalHandler[101] End processing HTTP request after 563.7564ms - OK
host模式
未完待续。。。
none模式
overlay模式
参考文献:
[1] https://docs.docker.com/network/bridge/
[2] https://docs.docker.com/network/network-tutorial-standalone/
[3] https://www.cnblogs.com/kb342/p/5799266.html