1 引言
目前深度学习模型已经应用到了各个领域,将TensorFlow训练模型部署到终端上也逐步变为了现实。特别是mobileNet等体积小,占用内存少的模型出现后,将深度学习应用到终端上逐渐变得火热起来。mobileNet针对于终端,将标准的卷积分解成了一个depthwise 卷积和一个1x1的标准卷积,大大降低了模型参数数量。同时支持输入channel和resolution的裁剪,也大大降低了模型体积。官方训练的MobileNet_v1_0.25_128_quant, 在输入channel裁剪为原先1/4, 图像尺寸变为128*128后,模型体积仅仅为4.1MB,但识别准确度仍然可以达到65.8%. 本文聚焦于TensorFlow模型在Android app中的如何应用,就不对mobileNet进行详细分析了。
官方在TensorFlow源码的tensorflow/examples/android/ 目录下提供了一个app demo,配置好环境后,就可以在Android studio中run起来并安装到手机中了。下面详细分析这个demo的源码。掌握了官方demo原理后,我们就能够一方面改造这个demo app,来实现其他功能,比如相册内容识别等。另一方面可以用自己训练好的模型来替换官方demo中的TensorFlow模型。
2 工程目录结构
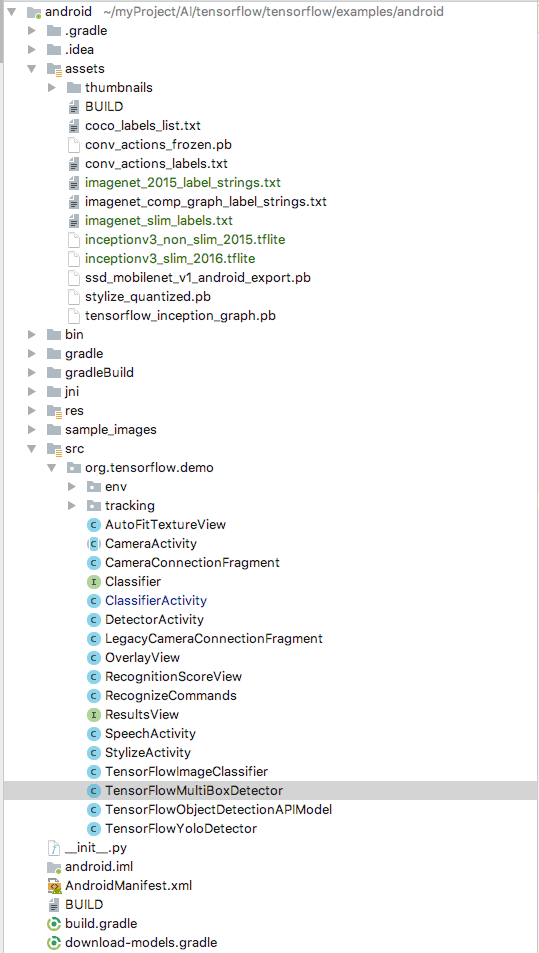
重要的文件如下
- assets:pb文件存放训练好的TensorFlow模型,txt文件为能够识别的物体的名字,也叫label。model和label成对出现。官方给出的inceptionV1模型能够识别1000种物体,基本能够满足我们的日常需求。添加自己的模型时,需要在assets目录中加入自己训练好的model和对应label文件。
- jni:物体识别使用了摄像头等组件,需要调用到jni。我们不需要详细了解
- res:资源文件,学过Android的小伙伴都知道
- src:demo中包含了四个子项目,分别为物体识别Classifier, 物体检测Detector,语音识别Speech,图片个性化Stylize。四个demo只是在训练模型上有差别,与Android的结合大同小异。故本文重点分析物体识别Classifier。其中的关键类如下
- ClassifierActivity:app中物体识别的主页面,也是入口类
- CameraActivity:ClassifierActivity的父类,包含了相机权限获取,初始化,图片转换等操作。
- CameraConnectionFragment, LegacyCameraConnectionFragment:主页面中相机实时预览图片的区域,分为传统方式和当前方式两种。
- TensorFlowImageClassifier:利用TensorFlow模型来预测物体的关键所在,包含识别器classifier的构造和图像识别两个主要方法。后面详细分析。
- build.gradle: 编译项目的配置文件,工程环境配置时比较关键,本文重点讲解TensorFlow在Android上应用的原理,就不展开说了。
3 app进行物体识别的流程
3.1 onCreate中请求相机权限并设置页面内容区的fragment
我们从ClassifierActivity的onCreate()看起,它继承于CameraActivity。主要作用为设置Activity的contentView,以及请求打开相机的权限。如下
protected void onCreate(final Bundle savedInstanceState) {
// 设置window layout,以及设置contentView
LOGGER.d("onCreate " + this);
super.onCreate(null);
getWindow().addFlags(WindowManager.LayoutParams.FLAG_KEEP_SCREEN_ON);
setContentView(R.layout.activity_camera);
// 有相机权限,则进行设置相机实时图片预览区域的Fragment,否则,请求权限,让用户确定
if (hasPermission()) {
setFragment();
} else {
requestPermission();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
相机权限请求requestPermission,通过发送android.permission.CAMERA 权限请求即可,做过Android的小伙伴都知道,不详细分析了。下面看setFragment()方法
protected void setFragment() {
// 获取相机,通过CameraService选择正确的摄像头。本app中不使用前置摄像头
String cameraId = chooseCamera();
// 构建相机的Fragment.注册Camera.PreviewCallback,android.hardware.Camera的callback
Fragment fragment;
if (useCamera2API) {
// 摄像头支持高级的图像处理功能时,构造CameraConnectionFragment实例。后面详细分析
CameraConnectionFragment camera2Fragment =
CameraConnectionFragment.newInstance(
new CameraConnectionFragment.ConnectionCallback() {
@Override
// 选择了预览图片的大小时的回调
public void onPreviewSizeChosen(final Size size, final int rotation) {
previewHeight = size.getHeight();
previewWidth = size.getWidth();
CameraActivity.this.onPreviewSizeChosen(size, rotation);
}
},
this,
getLayoutId(),
getDesiredPreviewFrameSize());
camera2Fragment.setCamera(cameraId);
fragment = camera2Fragment;
} else {
// 摄像头只支持部分功能时,fallback到传统的API
fragment =
new LegacyCameraConnectionFragment(this, getLayoutId(), getDesiredPreviewFrameSize());
}
// fragment填充到container位置处
getFragmentManager()
.beginTransaction()
.replace(R.id.container, fragment)
.commit();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
下面来看CameraConnectionFragment,构造fragment时我们传入了两个比较重要的回调,一个是cameraConnectionCallback,它在打开摄像头时回调,一个是imageListener,它在摄像头拍摄到图片时回调。我们后面会详细分析。先来看fragment的生命周期中的几个重要方法。onCreateView() onViewCreated()基本没做太多事情,onResume()中有个关键动作,它调用了openCamera()方法来打开摄像头。我们来详细分析。
public void onResume() {
super.onResume();
startBackgroundThread();
if (textureView.isAvailable()) {
// 屏幕没有处于关闭状态时,打开摄像头。textureView是fragment中展示摄像头实时捕获的图片的区域。
openCamera(textureView.getWidth(), textureView.getHeight());
} else {
textureView.setSurfaceTextureListener(surfaceTextureListener);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.2 打开摄像头,并注册ConnectionCallback和OnImageAvailableListener
下面来看openCamera()方法。
private void openCamera(final int width, final int height) {
// 设置camera捕获图片的一些输出参数,图片预览大小previewSize,摄像头方向sensorOrientation等。最重要的是回调我们之前传入到fragment中的cameraConnectionCallback的onPreviewSizeChosen()方法。
setUpCameraOutputs();
// 设置手机旋转后的适配,这儿不用关心
configureTransform(width, height);
// 利用CameraManager这个Android底层类,打开摄像头。这儿也不是我们关注的重点
final Activity activity = getActivity();
final CameraManager manager = (CameraManager) activity.getSystemService(Context.CAMERA_SERVICE);
try {
if (!cameraOpenCloseLock.tryAcquire(2500, TimeUnit.MILLISECONDS)) {
throw new RuntimeException("Time out waiting to lock camera opening.");
}
manager.openCamera(cameraId, stateCallback, backgroundHandler);
} catch (final CameraAccessException e) {
LOGGER.e(e, "Exception!");
} catch (final InterruptedException e) {
throw new RuntimeException("Interrupted while trying to lock camera opening.", e);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
上面setUpCameraOutputs()比较重要,它设置了camera捕获图片的一些参数。如图片预览大小previewSize,摄像头方向sensorOrientation等。最重要的是回调我们之前传入到fragment中的cameraConnectionCallback的onPreviewSizeChosen()方法。我们来看之前CameraActivity中传入的cameraConnectionCallback
new CameraConnectionFragment.ConnectionCallback() {
@Override
// 预览图片的宽高确定后回调
public void onPreviewSizeChosen(final Size size, final int rotation) {
// 获取相机捕获的图片的宽高,以及相机旋转方向。
previewHeight = size.getHeight();
previewWidth = size.getWidth();
// 相机捕获的图片的大小确定后,需要对捕获图片做裁剪等预操作。这将回调到ClassifierActivity中。我们后面重点分析。
CameraActivity.this.onPreviewSizeChosen(size, rotation);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们这就分析清楚了打开摄像头前cameraConnectionCallback的回调流程了,还记得我们传入了另外一个listener吧,也就是onImageAvailableListener, 它在摄像头被打开后,捕获的图片available时由系统回调到。摄像头打开后,会create一个新的预览session,其中就会设置OnImageAvailableListener到CameraDevice中。这个过程我们不做详细分析了。
3.3 相机预览图片宽高确定后,回调onPreviewSizeChosen
上面分析到onPreviewSizeChosen会调用到ClassifierActivity中。它主要做了两件事,构造分类器classifier,它是模型分类预测的一个比较关键的类。另外就是预处理输入图片,如裁剪到和模型训练所使用的图片相同的尺寸。
// 图片预览展现出来时回调。主要是构造分类器classifier,和裁剪输入图片为224*224
@Override
public void onPreviewSizeChosen(final Size size, final int rotation) {
final float textSizePx = TypedValue.applyDimension(
TypedValue.COMPLEX_UNIT_DIP, TEXT_SIZE_DIP, getResources().getDisplayMetrics());
borderedText = new BorderedText(textSizePx);
borderedText.setTypeface(Typeface.MONOSPACE);
// 构造分类器,利用了TensorFlow训练出来的Model,也就是.pb文件。这是后面做物体分类识别的关键
classifier =
TensorFlowImageClassifier.create(
getAssets(),
MODEL_FILE,
LABEL_FILE,
INPUT_SIZE,
IMAGE_MEAN,
IMAGE_STD,
INPUT_NAME,
OUTPUT_NAME);
previewWidth = size.getWidth();
previewHeight = size.getHeight();
sensorOrientation = rotation - getScreenOrientation();
LOGGER.i("Camera orientation relative to screen canvas: %d", sensorOrientation);
LOGGER.i("Initializing at size %dx%d", previewWidth, previewHeight);
rgbFrameBitmap = Bitmap.createBitmap(previewWidth, previewHeight, Config.ARGB_8888);
croppedBitmap = Bitmap.createBitmap(INPUT_SIZE, INPUT_SIZE, Config.ARGB_8888);
// 将照相机获取的原始图片,转换为224*224的图片,用来作为模型预测的输入。
frameToCropTransform = ImageUtils.getTransformationMatrix(
previewWidth, previewHeight,
INPUT_SIZE, INPUT_SIZE,
sensorOrientation, MAINTAIN_ASPECT);
cropToFrameTransform = new Matrix();
frameToCropTransform.invert(cropToFrameTransform);
addCallback(
new DrawCallback() {
@Override
public void drawCallback(final Canvas canvas) {
renderDebug(canvas);
}
});
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
3.3.1 分类器classifier的构造
classifier分类器是模型预测图片分类中比较重要的类,其中一些概念和深度学习以及TensorFlow紧密相关。代码如下
// 构造物体识别分类器
public static Classifier create(
AssetManager assetManager,
String modelFilename,
String labelFilename,
int inputSize,
int imageMean,
float imageStd,
String inputName,
String outputName) {
// 1 构造TensorFlowImageClassifier分类器,inputName和outputName分别为模型输入节点和输出节点的名字
TensorFlowImageClassifier c = new TensorFlowImageClassifier();
c.inputName = inputName;
c.outputName = outputName;
// 2 读取label文件内容,将内容设置到出classifier的labels数组中
String actualFilename = labelFilename.split("file:///android_asset/")[1];
Log.i(TAG, "Reading labels from: " + actualFilename);
BufferedReader br = null;
try {
// 读取label文件流,label文件表征了可以识别出来的物体分类。我们预测的物体名称就是其中之一。
br = new BufferedReader(new InputStreamReader(assetManager.open(actualFilename)));
// 将label存储到TensorFlowImageClassifier的labels数组中
String line;
while ((line = br.readLine()) != null) {
c.labels.add(line);
}
br.close();
} catch (IOException e) {
throw new RuntimeException("Problem reading label file!" , e);
}
// 3 读取model文件名,并设置到classifier的interface变量中。
c.inferenceInterface = new TensorFlowInferenceInterface(assetManager, modelFilename);
// 4 利用输出节点名称,获取输出节点的shape,也就是最终分类的数目。
// 输出的shape为二维矩阵[N, NUM_CLASSES], N为batch size,也就是一批训练的图片个数。NUM_CLASSES为分类个数
final Operation operation = c.inferenceInterface.graphOperation(outputName);
final int numClasses = (int) operation.output(0).shape().size(1);
Log.i(TAG, "Read " + c.labels.size() + " labels, output layer size is " + numClasses);
// 5. 设置分类器的其他变量
c.inputSize = inputSize; // 物体分类预测时输入图片的尺寸。也就是相机原始图片裁剪后的图片。默认为224*224
c.imageMean = imageMean; // 像素点RGB通道的平均值,默认为117。用来将0~255的数值做归一化的
c.imageStd = imageStd; // 像素点RGB通道的归一化比例,默认为1
// 6. 分配Buffer给输出变量
c.outputNames = new String[] {outputName}; // 输出节点名字
c.intValues = new int[inputSize * inputSize];
c.floatValues = new float[inputSize * inputSize * 3]; // RGB三通道
c.outputs = new float[numClasses]; // 预测完的结果,也就是图片对应到每个分类的概率。我们取概率最大的前三个显示在app中
return c;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
3.3.2 预处理预览图片
// 预处理预览图片,裁剪,旋转等操作。
// srcWidth, srcHeight为预览图片宽高。dstWidth dstHeight为训练模型时使用的图片的宽高
// applyRotation 旋转角度,必须是90的倍数,
// maintainAspectRatio 如果为true,旋转时缩放x而保证y不变
public static Matrix getTransformationMatrix(
final int srcWidth,
final int srcHeight,
final int dstWidth,
final int dstHeight,
final int applyRotation,
final boolean maintainAspectRatio) {
// 定义预处理后的图片像素矩阵
final Matrix matrix = new Matrix();
// 处理旋转
if (applyRotation != 0) {
// 旋转只能处理90度的倍数
if (applyRotation % 90 != 0) {
LOGGER.w("Rotation of %d % 90 != 0", applyRotation);
}
// translate平移,保持圆心不变
matrix.postTranslate(-srcWidth / 2.0f, -srcHeight / 2.0f);
// rotate旋转
matrix.postRotate(applyRotation);
}
// 输出矩阵是否需要转置。如果旋转为90度和270度时需要。转置后,宽高互换。
final boolean transpose = (Math.abs(applyRotation) + 90) % 180 == 0;
final int inWidth = transpose ? srcHeight : srcWidth;
final int inHeight = transpose ? srcWidth : srcHeight;
// 如果src尺寸和dest尺寸不同,则需要做裁剪
if (inWidth != dstWidth || inHeight != dstHeight) {
final float scaleFactorX = dstWidth / (float) inWidth;
final float scaleFactorY = dstHeight / (float) inHeight;
if (maintainAspectRatio) {
// 保持宽高比例不变,不会有形变,但可能会被剪切。此时宽高scale的因子相同
final float scaleFactor = Math.max(scaleFactorX, scaleFactorY);
matrix.postScale(scaleFactor, scaleFactor);
} else {
// 不用保持宽高不变,直接匹配为dest的尺寸。可能会发生形变
matrix.postScale(scaleFactorX, scaleFactorY);
}
}
if (applyRotation != 0) {
// 平移变换
matrix.postTranslate(dstWidth / 2.0f, dstHeight / 2.0f);
}
return matrix;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
3.4 相机预览图片available时,OnImageAvailableListener回调
当相机预览图片准备好时,Android系统的cameraDevice会回调之前注册的OnImageAvailableListener。下面来看OnImageAvailableListener都做了哪些事情。
public void onImageAvailable(final ImageReader reader) {
// onPreviewSizeChosen被回调后,设置了previewWidth和previewHeight,才处理预览图片
if (previewWidth == 0 || previewHeight == 0) {
return;
}
// 构造图片输出矩阵
if (rgbBytes == null) {
rgbBytes = new int[previewWidth * previewHeight];
}
try {
// 获取图片
final Image image = reader.acquireLatestImage();
if (image == null) {
return;
}
// 正在处理图片时,则直接返回
if (isProcessingFrame) {
image.close();
return;
}
// yuv转换为rgb格式
isProcessingFrame = true;
Trace.beginSection("imageAvailable");
final Plane[] planes = image.getPlanes();
fillBytes(planes, yuvBytes);
yRowStride = planes[0].getRowStride();
final int uvRowStride = planes[1].getRowStride();
final int uvPixelStride = planes[1].getPixelStride();
imageConverter =
new Runnable() {
@Override
public void run() {
ImageUtils.convertYUV420ToARGB8888(
yuvBytes[0],
yuvBytes[1],
yuvBytes[2],
previewWidth,
previewHeight,
yRowStride,
uvRowStride,
uvPixelStride,
rgbBytes);
}
};
postInferenceCallback =
new Runnable() {
@Override
public void run() {
image.close();
isProcessingFrame = false;
}
};
// 这儿是关键,利用训练模型来预测图片,后面详细分析
processImage();
} catch (final Exception e) {
LOGGER.e(e, "Exception!");
Trace.endSection();
return;
}
Trace.endSection();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
onImageAvailable()先做一些预校验,如previewWidth是否被设置,当前是否正在处理图片等。然后将相机捕获的yuv格式图像转为rgb格式。最后,也是最重要的一步,调用processImage,利用TensorFlow模型来处理图片。下面我们详细分析processImage
protected void processImage() {
// 图片的绘制等,不是模型预测的重点,不分析了
rgbFrameBitmap.setPixels(getRgbBytes(), 0, previewWidth, 0, 0, previewWidth, previewHeight);
final Canvas canvas = new Canvas(croppedBitmap);
canvas.drawBitmap(rgbFrameBitmap, frameToCropTransform, null);
// For examining the actual TF input.
if (SAVE_PREVIEW_BITMAP) {
ImageUtils.saveBitmap(croppedBitmap);
}
// 利用分类器classifier对图片进行预测分析,得到图片为每个分类的概率. 比较耗时,放在子线程中
runInBackground(
new Runnable() {
@Override
public void run() {
final long startTime = SystemClock.uptimeMillis();
// 1 classifier对图片进行识别,得到输入图片为每个分类的概率
final List<Classifier.Recognition> results = classifier.recognizeImage(croppedBitmap);
lastProcessingTimeMs = SystemClock.uptimeMillis() - startTime;
LOGGER.i("Detect: %s", results);
// 2 将得到的前三个最大概率的分类的名字及概率,反馈到app上。也就是results区域
cropCopyBitmap = Bitmap.createBitmap(croppedBitmap);
if (resultsView == null) {
resultsView = (ResultsView) findViewById(R.id.results);
}
resultsView.setResults(results);
// 3 请求重绘,并准备下一次的识别
requestRender();
readyForNextImage();
}
});
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
processImage()先做图片绘制方面的工作,将相机捕获的图片绘制出来。然后利用分类器classifier来识别图片,获取图片为每个分类的概率。最后将概率最大的前三个分类,展示在result区域上。这儿我们重点来看分类器是如何来识别图片的。也就是classifier.recognizeImage()
public List<Recognition> recognizeImage(final Bitmap bitmap) {
// 1 预处理输入图片,读取像素点,并将RGB三通道数值归一化. 归一化后分布于 -117 ~ 138
bitmap.getPixels(intValues, 0, bitmap.getWidth(), 0, 0, bitmap.getWidth(), bitmap.getHeight());
for (int i = 0; i < intValues.length; ++i) {
final int val = intValues[i];
floatValues[i * 3 + 0] = (((val >> 16) & 0xFF) - imageMean) / imageStd; // 归一化通道R
floatValues[i * 3 + 1] = (((val >> 8) & 0xFF) - imageMean) / imageStd; // 归一化通道G
floatValues[i * 3 + 2] = ((val & 0xFF) - imageMean) / imageStd; // 归一化通道B
}
Trace.endSection();
// 2 将输入数据填充到TensorFlow中,并feed数据给模型
// inputName为输入节点
// floatValues为输入tensor的数据源,
// dims构成了tensor的shape, [batch_size, height, width, in_channel], 此处为[1, inputSize, inputSize, 3]
Trace.beginSection("feed");
inferenceInterface.feed(inputName, floatValues, 1, inputSize, inputSize, 3);
Trace.endSection();
// 3 跑TensorFlow预测模型
// outputNames为输出节点名, 通过session来run tensor
Trace.beginSection("run");
inferenceInterface.run(outputNames, logStats);
Trace.endSection();
// 4 将tensorflow预测模型输出节点的输出值拷贝出来
// 找到输出节点outputName的tensor,并复制到outputs中。outputs为分类预测的结果,是一个一维向量,每个值对应labels中一个分类的概率。
Trace.beginSection("fetch");
inferenceInterface.fetch(outputName, outputs);
Trace.endSection();
// 5 得到概率最大的前三个分类,并组装为Recognition对象
PriorityQueue<Recognition> pq =
new PriorityQueue<Recognition>(
3,
new Comparator<Recognition>() {
@Override
public int compare(Recognition lhs, Recognition rhs) {
// Intentionally reversed to put high confidence at the head of the queue.
return Float.compare(rhs.getConfidence(), lhs.getConfidence());
}
});
for (int i = 0; i < outputs.length; ++i) {
if (outputs[i] > THRESHOLD) {
pq.add(
new Recognition(
"" + i, labels.size() > i ? labels.get(i) : "unknown", outputs[i], null));
}
}
final ArrayList<Recognition> recognitions = new ArrayList<Recognition>();
int recognitionsSize = Math.min(pq.size(), MAX_RESULTS);
for (int i = 0; i < recognitionsSize; ++i) {
recognitions.add(pq.poll());
}
Trace.endSection(); // "recognizeImage"
return recognitions;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
图片识别主要分为5步
- 预处理输入图片,读取像素点,并将RGB三通道数值归一化. 归一化后分布于 -117 ~ 138
- 将输入数据填充到TensorFlow中,并feed数据给模型
- 跑TensorFlow预测模型
- 将tensorflow预测模型输出节点的输出值拷贝出来
- 得到概率最大的前三个分类,并组装为Recognition对象
TensorFlow-Android sdk对TensorFlow封装得很好,暴露了TensorFlowInferenceInterface这个对象来作为接口供我们调用底层TensorFlow代码。其中feed用来填充输入图片,run用来跑模型并得到结果,fetch用来从TensorFlow内部获取输出节点的输出值。
这样我们就将打开摄像头,注册监听器,构造分类器classifier,预处理相机图片和利用模型预测图片分类的整个流程分析清楚了。对于自己实现一个应用TensorFlow模型的Android app应该了然于心了吧。
4 总结
掌握了官方demo的整个流程后,我们完全可以一方面改造app,来定制我们其他功能需求,比如实现一个相册中照片识别分类的app。另一方面替换模型为自己训练好的其他模型,比如将官方的inceptionV1替换为更小的mobilenet。随着深度学习在终端应用的普及,TensorFlow在Android上的应用将会发挥更大的用武之地。