1、首先要大概知道非0拷贝机制

传统的读取文件数据并发送到网络的步骤如下: (1)操作系统将数据从磁盘文件中读取到内核空间的页面缓存; (2)应用程序将数据从内核空间读入用户空间缓冲区; (3)应用程序将读到数据写回内核空间并放入socket缓冲区; (4)操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络发送。
很明显,传统非0拷贝读取磁盘一次,经过4次网络拷贝(IO);
如果读取10亿次,意味经过40亿次频繁的IO处理
2、kafka的0拷贝技术
kafka的0拷贝技术充分利用了操作系统内核OSCache
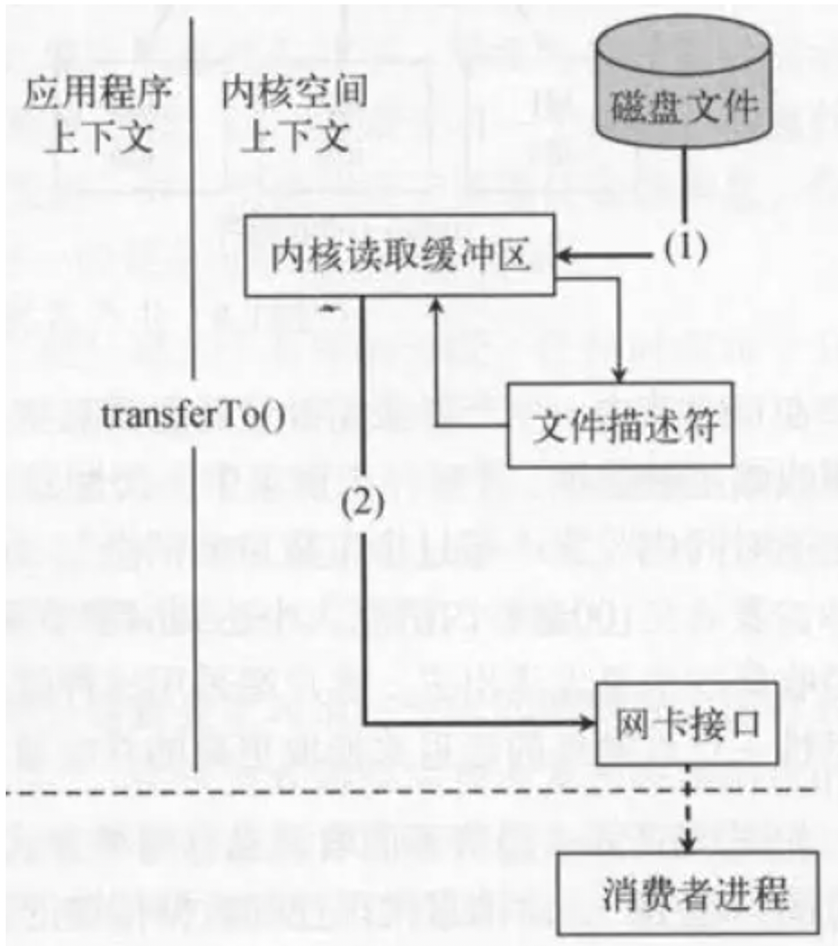
只用将磁盘文件的数据复制到页面缓存中一次,然后将数据从页面缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面缓存),避免了重复复制操作
这样原来的一次读取操作,只经历了2次拷贝(IO);
假如现在有5个消费者 , 要读取10亿次磁盘文件:
原来的非0拷贝:5 * 10亿 * 4 = 200亿次网络拷贝(IO)
0拷贝技术:1 次 + 10亿次
很明显,随着消费者次数的增多,读取次数的增多,占用IO的频繁是很明显的
3、估算kafka服务器需要的内存
通过0拷贝,可以知道,kafka快速的主要原因是利用了内核缓冲区OScache , 意味着 kafka本身的JVM要求其实并不是特别大的;
因为很多数据结构并不在JVM内部使用,而是在OSCache内部;
所以,一般我们给kafka服务的jvm内存几个G就可以了,比如一个kafka服务给5G
现在有 5台机器 , 一般情况下分区数和机器数是倍数关系的,比如5台kafka机器,那么分区数可以是5或者10
假如生产线上的topic个数是100个 , 每个topic的分区数是5 , 那么总共的分区数是500
正常情况下,kafka存储数据的.log文件默认大小是1G , 每个分区的最新.log文件肯定默认大小就是1G
现在有 500个分区,那么饱和状态下就是 : 如果有500G的内存,完全是可以的;
但是没必要这样豪横 , 因为消费者去kafka拉取数据,绝对是拉取上一次offset位置的数据,也就是保守估计,预留原来的25%的内存就可以的
所以,原来是500G内存 * 25% = 75G内存;
5台机器,相当于每台机器给OSCache预留25G内存 , 同时kafka server的jvm在预留 5G的-Xmx和-Xms
最后得出,每台机器给30G内存就可以