Ultra96 PYNQ入门之四——数据搬运能手DMA
不合理的地方欢迎批评指正!!!
源代码链接:Ultra96-PYNQ_A-simple-summary
1 背景知识
- DMA:直接内存访问,具体可查阅谷歌
- AXI接口:下图是MPSOC内部的互联情况,演示仅使用HP或HPC接口,用于PL通过DMA向PS部分的DDR4搬运数据

简化图如下
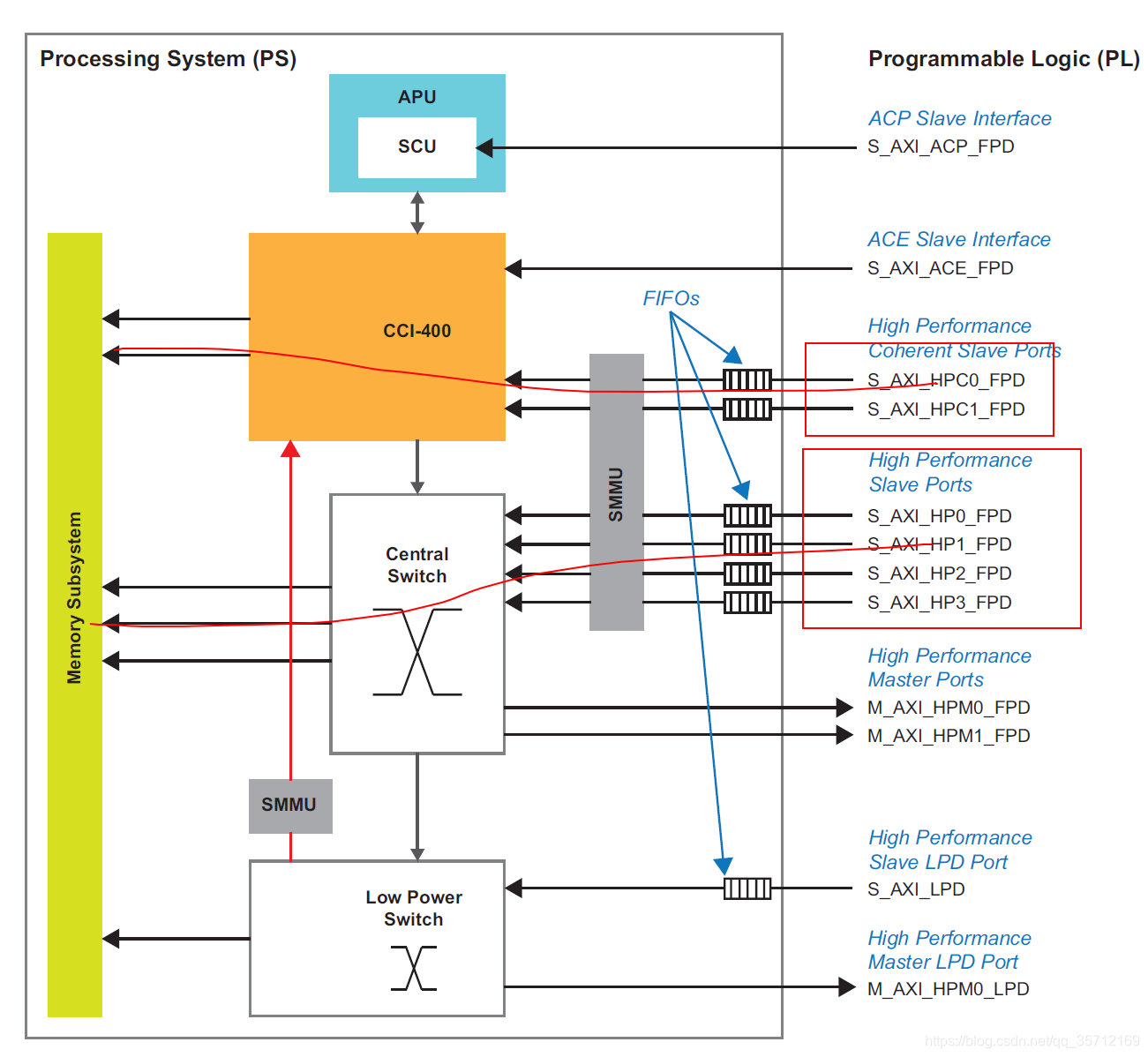
- AXI4-Stream
仅仅是完成本节的演示实验,可以不用深入了解AXI-Stream,但是要想真正的利用DMA将海量数据从PL搬运到PS的DDR中,那么AXI-Stream是你必须深入了解的。
2 DMA Loop演示
2.1 硬件设计
1. 简化的逻辑框图
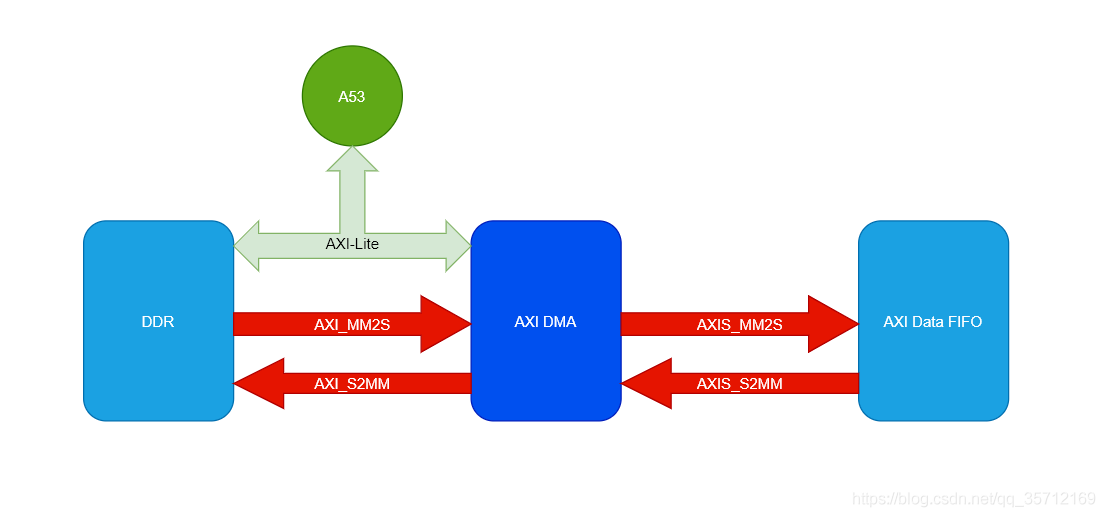
2. DMA Loop逻辑框图

3. DMA的配置
最简化DMA配置,DMA的缓存开到最大

2.2 软件设计
输入缓冲区为正弦波形,通过DMA Loop返回到输出缓冲区。
from pynq import Overlay
import time
from pynq import Xlnk
import numpy as np
xlnk = Xlnk()
dma_loop = Overlay("./data/4.DMA_Loop.bit")
%matplotlib inline
import matplotlib.pyplot as plt
from ipywidgets import *
data_size = 1024*1024
input_buffer = xlnk.cma_array(shape=(data_size,), dtype=np.uint64)
output_buffer = xlnk.cma_array(shape=(data_size,), dtype=np.uint64)
raw_input = ( (np.sin(np.linspace(0, 4*np.pi, data_size)) + 1) * 65536 ).astype(dtype=np.uint64)
for i in range(data_size):
input_buffer[i] = raw_input[i]
plt.plot(range(len(input_buffer)), input_buffer)
print("the len of input_buffer:{}".format(len(input_buffer)))
dma_send = dma_loop.axi_dma_0.sendchannel
dma_recv = dma_loop.axi_dma_0.recvchannel
dma_send.transfer(input_buffer)
dma_recv.transfer(output_buffer)
dma_send.wait()
dma_recv.wait()
plt.plot(range(len(output_buffer)), output_buffer)
print("the len of input_buffer:{}".format(len(output_buffer)))
print("DMA sendchannel state is idle:{}".format(dma_send.idle))
print("DMA sendchannel state is running:{}".format(dma_send.running))
print("DMA recvchannel state is idle:{}".format(dma_recv.idle))
print("DM1 recvchannel state is running:{}".format(dma_recv.running))
需要特别注意的点是硬件设计中FIFO的缓冲区仅设计为4096,如果发送的同时不同步读取的话,会导致数据丢失。所以发送要立即读取,防止出现数据丢失的现象。
dma_send.transfer(input_buffer)
dma_recv.transfer(output_buffer)
3 DMA 速度测试
3.1 简单速度测试
每次发送8MB数据,发送128次。
start = time.time()
for i in range(128):
dma_send.transfer(input_buffer)
dma_recv.transfer(output_buffer)
dma_send.wait()
dma_recv.wait()
end = time.time()
print("DMA数据发送或接收的速度为{}MB/s".format(1024 / (end - start)))
DMA数据发送或接收的速度为508.3851995927206MB/s
发送与接收均占用HP0口。
3.2 “鸡血”性能测试
说是鸡血有点不合适,做出的提升主要有
- 提升PL部分的时钟频率:从100MHZ到300MHZ。
- 使用两个HP口,一个用于发送,一个用于接收。
硬件逻辑框图

测试结果
DMA数据发送或接收的速度为1023.8781883201666MB/s
还有很多方面可以提升,大幅提升数据位宽、DMA高级模式的使用(PYNQ好像不支持?)上面仅仅是示例,欢迎自由发挥。
4 DMA工程使用
DMA Loop实验仅是演示下DMA的使用,如果真要在设计中使用DMA,则需要通过自己通过AXI4-Stream接口,来实现PL与PS的数据交互。
可以利用PL部分的BRAM,通过读取BRAM的初始化数据,并将数据流转化为AXI4-Stream数据流,再结合乒乓操作,实现高效的PL采集的数据发送到PS的DDR中。
DMA也有相应的中断,可以参考Ultra96 PYNQ使用之三——中断与协程尝试着使用DMA的中断
await dma_send.wait_async()
await dma_recv.wait_async()
原创不易,严禁剽窃!

欢迎大家关注我创建的微信公众号——小白仓库
原创经验资料分享:包含但不仅限于FPGA、ARM、RISC-V、Linux、LabVIEW等软硬件开发,另外分享生活中的趣事以及感悟。目的是建立一个平台记录学习过的知识,并分享出来自认为有用的与感兴趣的道友相互交流进步。