**什么是人工智能、机器学习与深度学习? **
人工智能的简洁定义如下:努力将通常由人类完成的智力任务自动化。
机器学习指自我学习执行特定任务。他和深度学习的核心问题都在于有意义地变换数据。
深度学习是机器学习的一个分支领域 : 它是从数据中学习表示的一种新方法,强调从连续的层(layer)中进行学习。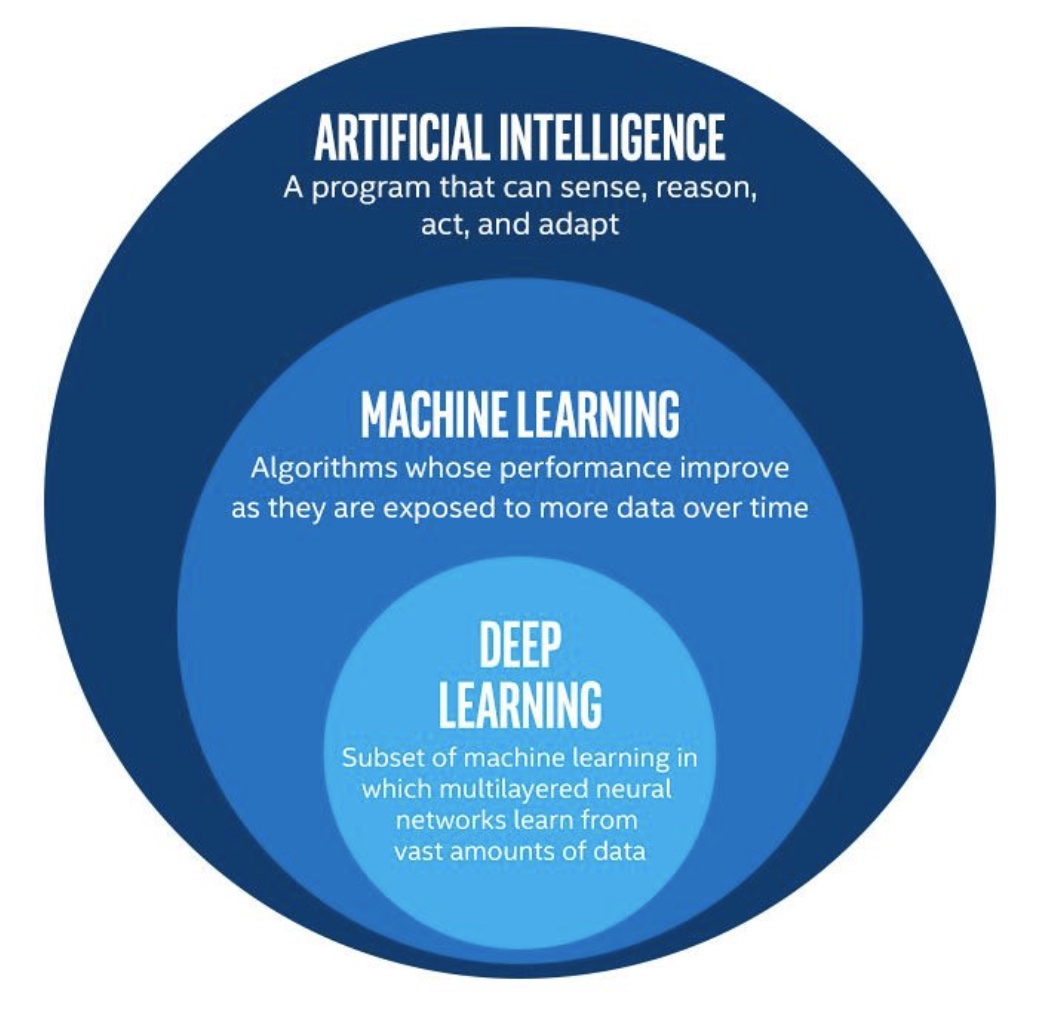
作为入门学习者,经常搞混一些概念和层级,在本篇文章中将梳理一下这些层级关系,简述各个算法的大概内容,建立起框架性的理解。
下面我将从机器学习的方法和机器学习算法两方面开始。
机器学习问题的四个分支
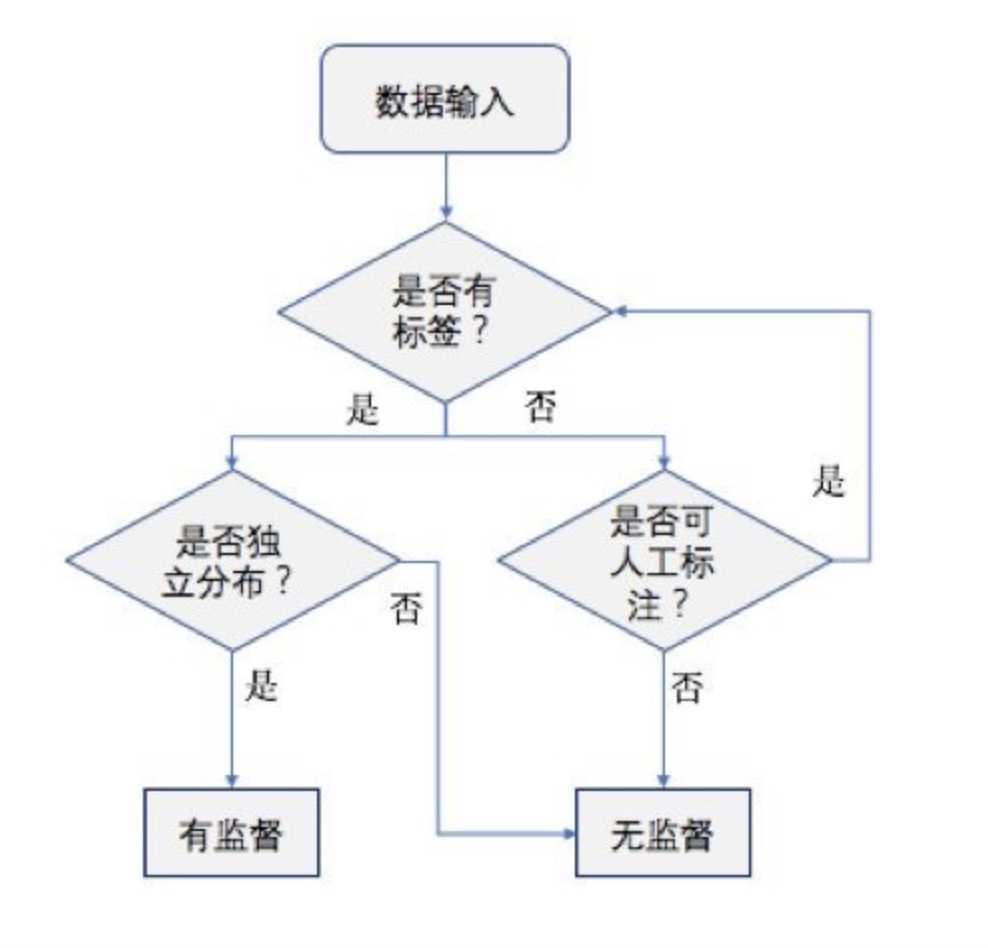
- 监督学习
监督学习是目前最常见的机器学习类型。给定一组样本( 通常由人工标注,有一个明确的标识或结果 ),它可以学会将输入数据映射到已知目标。近年来广受关注的深度学习应用几乎都属于监督学习,比如字符识别、语音识别、 图像分类和语言翻译。
监督学习主要包括分类和回归,分类问题也分为多标签多分类、单标签单分类等。
- 无监督学习
无监督学习是指在没有目标的情况下寻找输入数据的有趣变换,无监督学习主要包括聚类、降维。
- 自监督学习
自监督学习是监督学习的一个特例,它与众不同,值得单独归为一类。自监督学习是没有人工标注的标签的监督学习,你可以将它看作没有人类参与的监督学习。标签从输入数据中生成的。
- 强化学习
在强化学习下,输入数据作为对模型的反馈,模型对此立刻作出优化调整。
机器学习算法分类
机器学习的范围非常庞大,算法多而杂,有些算法很难明确归类到某一类。而对于有些分类来说,同一分类的算法可以针对不同类型的问题。
接下来将叙述这些算法的大概思路。
-
核方法
核方法是一组分类算法,其中最有名的就是支持向量机SVM(Support Vector Machine)
SVM 的目标是通过把输入数据映射到一个高阶的向量空间,在新的表示空间中找到良好的决策超平面,来解决分类问题。
但是,SVM 很难扩展到大型数据集,计算量大,效率会很低;其次,需要找合适的核函数。
-
决策树、随机森林与梯度提升机
这三种算法具有相似的性质,根据数据的属性采用树状结构建立决策模型。
梯度提升机得到的模型与随机森林具有相似的性质,但在绝大多数情况下效果都比随机森林要好,因为运用了梯度提升方法。和深度学习一样,它也是 Kaggle 竞赛中最常用的技术之一。
-
逻辑回归 (logistic regression)
logistic 回归 (logistic regression,简称 logreg),它有时被认为是 现代机器学习的“hello world”。logreg 是一种分类算法,而不是回归算法。
-
贝叶斯算法
贝叶斯算法是基于贝叶斯定理的一类算法,主要用来解决分类和回归问题。贝叶斯算法是基于贝叶斯定理的一类算法,主要用来解决分类和回归问题。常见算法包括:朴素贝叶斯算法
-
KNN(K Nearest Neighbor) K近邻
K-近邻是一种分类算法,其思路是:如果一个样本在特征空间中的k个最相似 ( 即特征空间中最邻近 ) 的样本中的大多数属于某一个类别,则该样本也属于这个类别。
-
神经网络
神经网络是机器学习的一个庞大的分支,有几百种不同的算法。(其中深度学习就是其中的一类算法)
他起源于上世纪,当时叫感知机(perceptron),拥有输入层、输出层和一个隐含层。随着数学的发展,发明了多层感知机,进入20世纪后,隐含层不断增多,神经网络真正意义上有了“深度”,由此揭开了深度学习的热潮。然后出现了CNN、RNN、LSTM等结构。通常将深度学习划分为监督学习,但实际上无监督学习也可以使用深度学习。
-
聚类算法
聚类算法是将一系列对象分组的任务。所有的聚类算法都试图找到数据的内在结构,以便按照最大的共同点将数据进行归类,使相同组(集群)中的对象之间比其他组的对象更相似。
-
降维算法
降低维度算法将原高维空间中的数据点映射到低维度的空间中。以非监督学习的方式试图利用较少的信息来归纳或者解释数据。