1. 背景与需求
在处理数据中,往往需要做多维特征提取(一对多),如下:
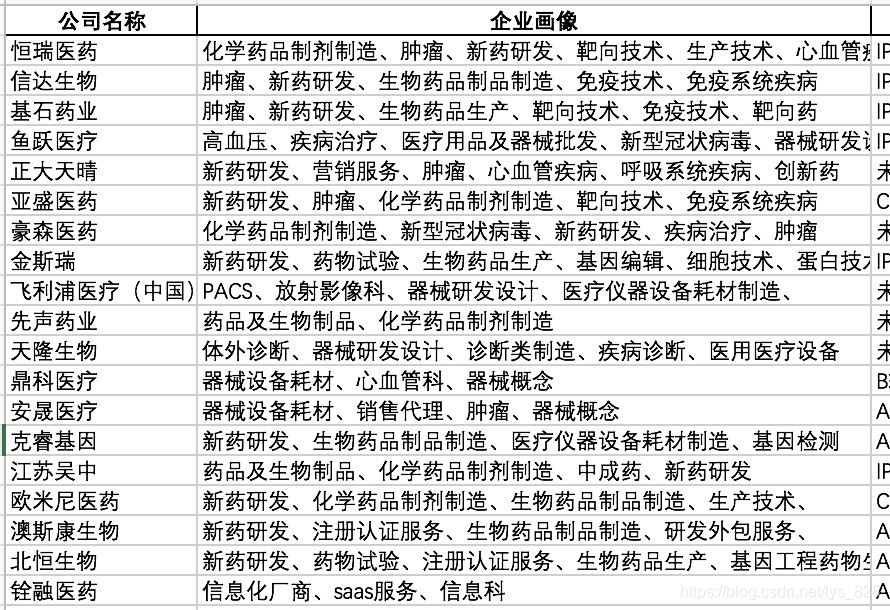
一个企业会有多个擅长领域,为了作多维度数据特征分析,需要将‘企业画像’中单元格的数据进行拆分成为一行一个特征的数据样式,且其他列数据保持不变,简单的demo(以随机两个公司为例)如下
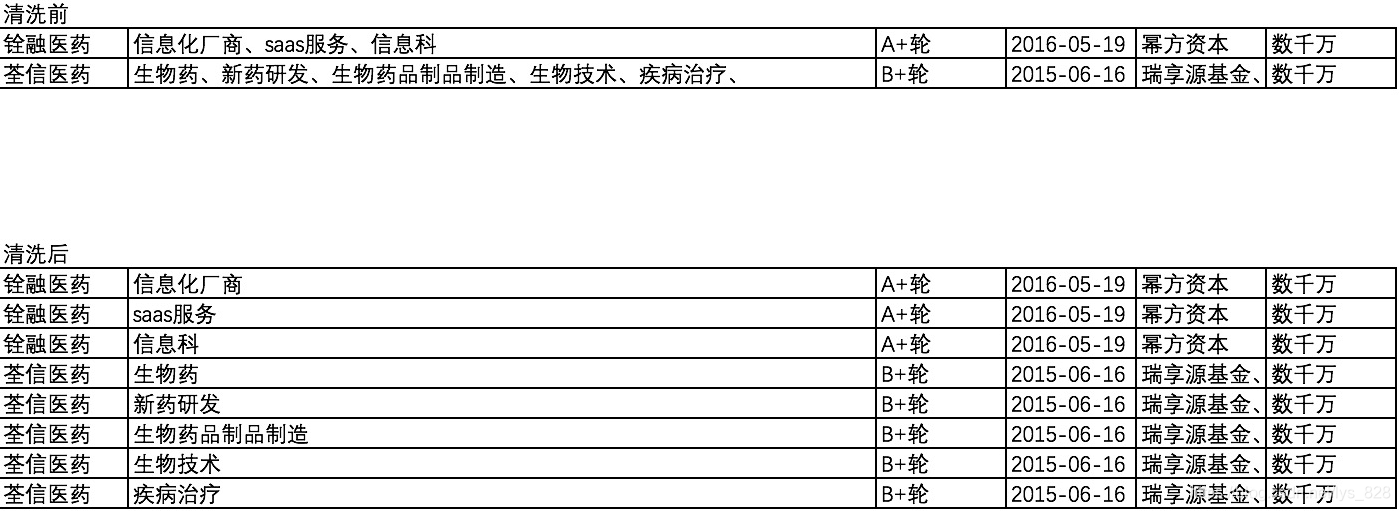
2. 问题解决
这里需要使用pandas中的explode方法,注意此方法是在0.25.0版本之后才有,所以确认当前的pandas版本是在此之上,查看某个库的版本可以使用如下代码
import pandas
print(pandas.__version__)
0.25.3 #当前的版本
2.1 官方示例
df.explode() 方法的使用代码如下:
import pandas as pd
df = pd.DataFrame({'A': [[1, 2, 3], 'foo', [], [3, 4]], 'B': 1})
print(df)
print(df.explode('A'))
→ 输出的结果为:(会将一列的单元格数据进行拆分,注意数据的格式:列表里面多个元素)
A B
0 [1, 2, 3] 1
1 foo 1
2 [] 1
3 [3, 4] 1
A B
0 1 1
0 2 1
0 3 1
1 foo 1
2 NaN 1
3 3 1
3 4 1
2.2 实际操作
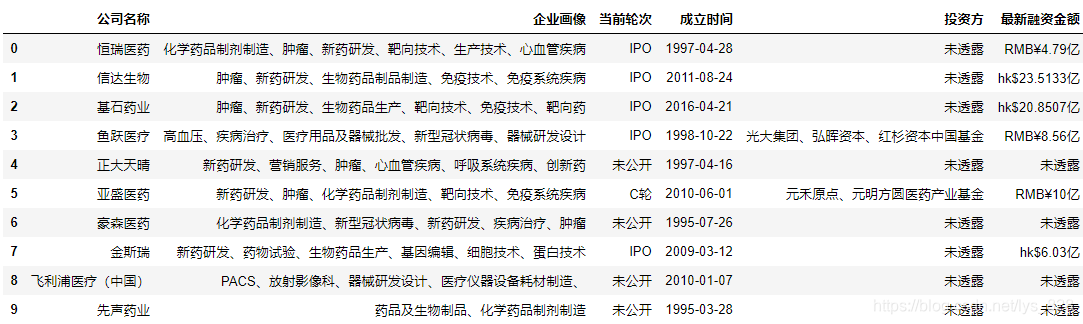
首先导入库,进行文件数据的读取
import pandas as pd
data = pd.read_excel('data_ok.xlsx')
data.head(10)
→ 输出的结果为:(文件数据导入成功)
2.2.1 采坑
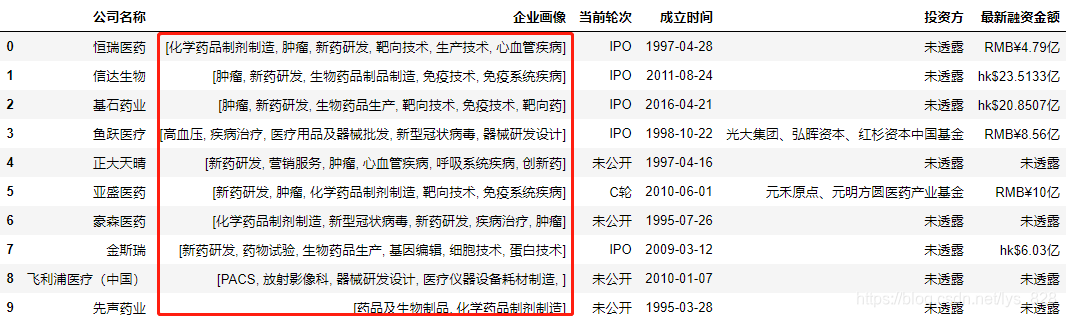
观察官方给出的示例,为了确保数据的格式一样,先把格式化为统一,因此就对‘企业画像’这个字段进行数据处理
data['企业画像'] = data['企业画像'].apply(lambda x:[x.replace('、',', ')])
data.head(10)
→ 输出的结果为:(在jupyter notebook里面这里看上去是和官方是一致的)
然后在按照‘企业画像’字段进行拆分数据,运行代码及输出的结果如下,会发现并没有出现想要的结果
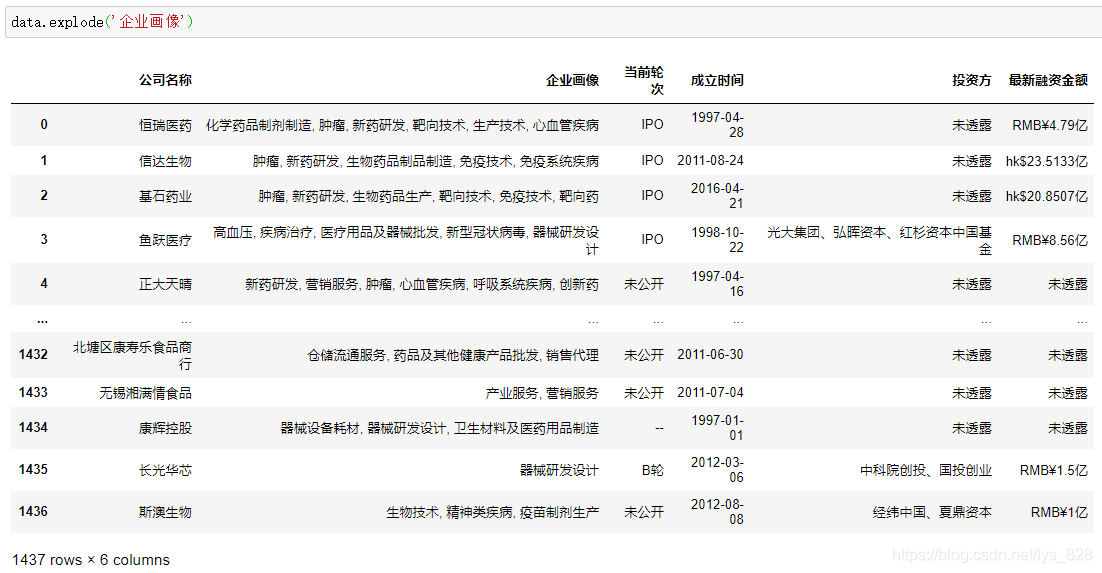
2.2.2 问题纠错
碰巧的是我在spyder里面运行相同的代码,然后在调试的过程中,发现中间进行目标格式转化时,spyder的变量查看器里的数据格式是和jupyter notebook中不一样(列表里面只有一个元素)。当执行完数据格式转化之后,spyder中的数据如下
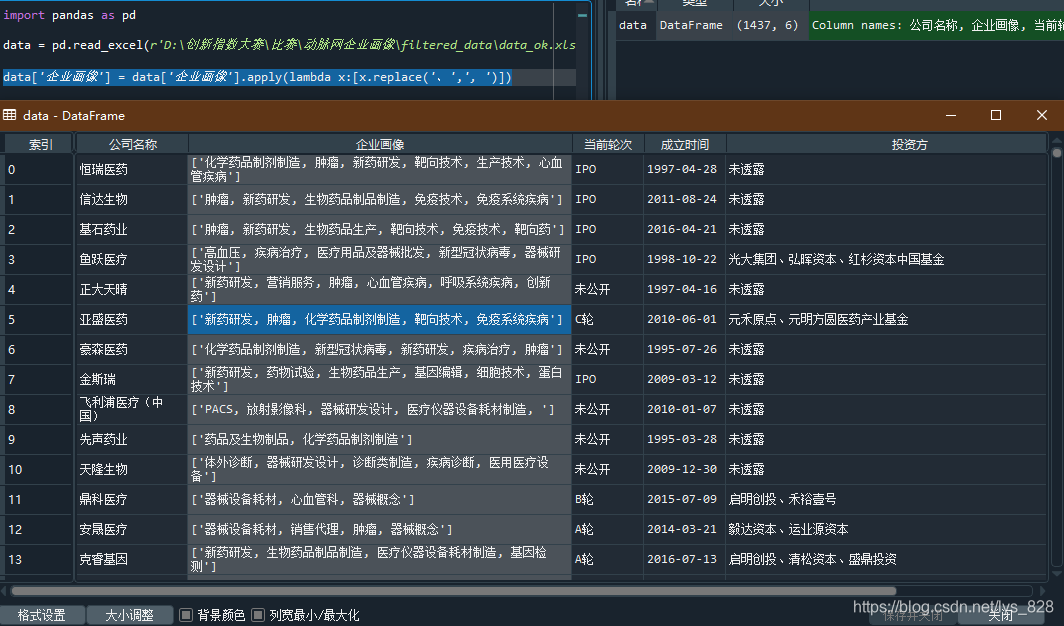
区别在于,jupyter notebook在显示数据的时候将代表字符串格式的引号省去了,但是spyder中是显示出来了。 因此可以推测:虽然在jupyter notebook中数据看上去是一致的,但是格式上并没有化为一致,这也就是为什么直接explode之后并没有出现我们想要的结果的原因,接下来的操作中证实了这个猜测
3. 问题解决
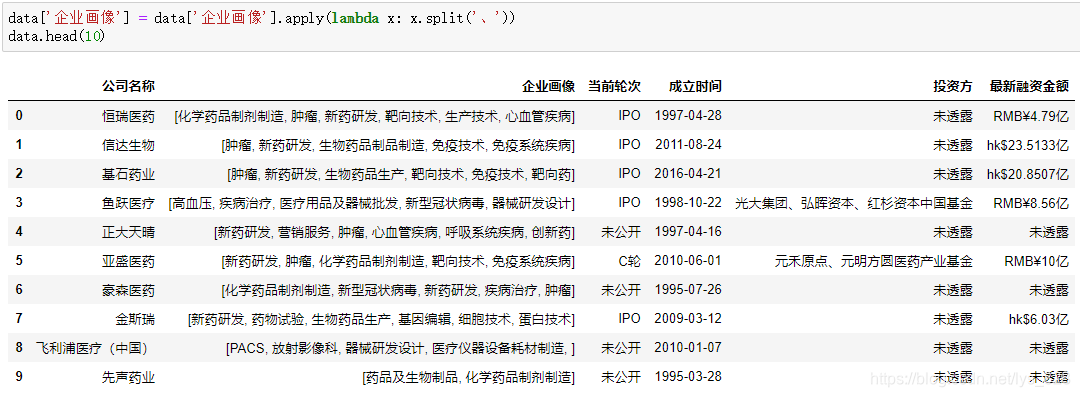
还是修改‘企业画像’中单元格的数据格式,这次应该是将数据转为一个一个的元素,然后是列表的形式,就可以使用split方法,代码及输出结果如下:
然后为了再次体现出差异性,将相同的代码在spyder中运行,结果如下
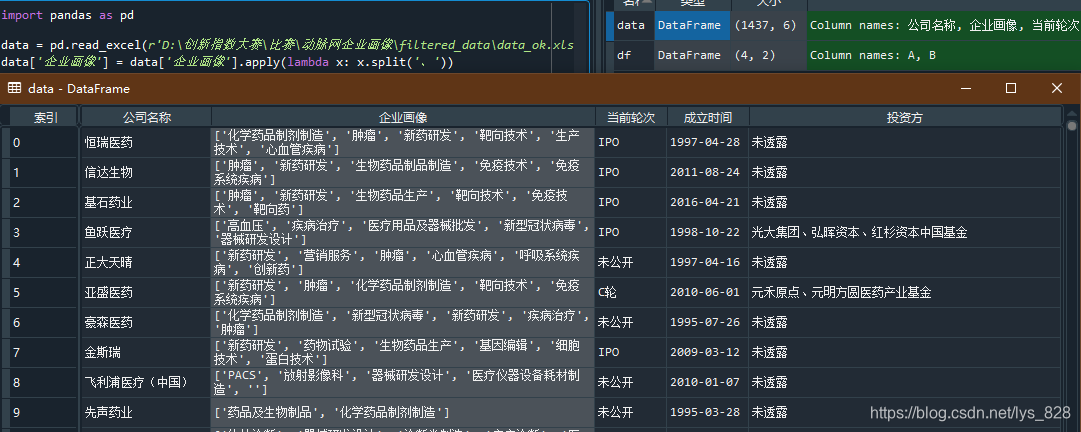
然后再对比‘企业画像’中的数据,可以发现之间的区别:jupyter notebook在显示数据的时候会将引号省去,造成表面上数据格式的统一(也证实了之前的猜测),这次的数据格式是和官方示范的一样了,接下来就是进行数据拆分了
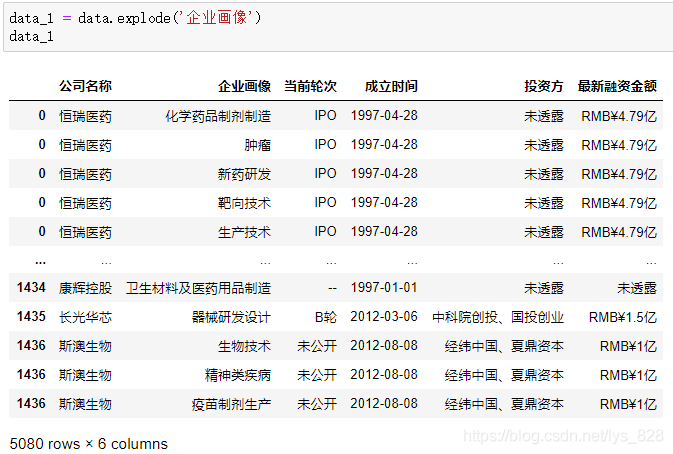
在jupyter notebook中执行代码如下:
在spyder中执行代码如下:
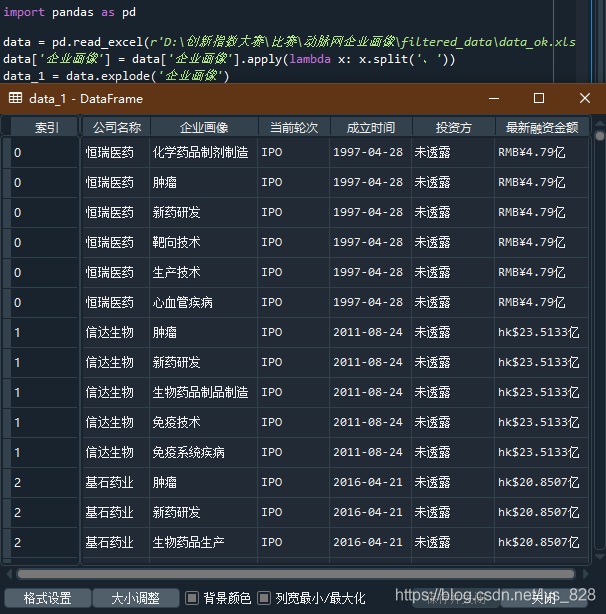
最终完成数据清洗的要求,进行数据的多维特征提取
4. 小结
官方示例给的demo很是简洁,但是在实际操作的过程中数据并没有那么简单,而且在编程敲代码中不要只习惯用一种编辑器,因为没有一种编辑器可以说是非常完美的,都存在优缺点,根据具体的需要选择相应的编辑器即可
切记:敲代码的初衷是解决问题,使得问题简单化而不是复杂化