1.系统变量
2.自定义变量
3.存储过程
4.函数
5.流程控制结构

1.系统变量
1.1系统变量的分类
系统变量:分为全局变量和会话变量
1.2系统变量的介绍
系统变量由系统提供,不是用户定义,属于服务器层面
1.3系统变量的相关操作
(1).查看所有的系统变量
show global(session) variables
global表示查看全局变量
session表示会话变量
(2)查看满足条件的部分系统变量
show global(session) variables like “...”
(3)查看指定某个系统变量的值
select @@global(@@session).变量名
(4)为某一个系统变量赋值
set global(session) 系统变量名=值
或者:
set @@global(session).系统变量=值
以上的各种指令可以不加global和session默认为session
2.自定义变量
2.1自定义变量的分类
用户变量和局部变量
2.2自定义变量的介绍
变量是用户自定义,不是由系统提供
用户变量:针对当前会话游有效,能声明初始化,赋值使用
局部变量:仅仅在定义它的begin end中有效,应用在begin,end中的第一句话
2.3自定义变量的相关操作
1.用户变量的声明并初始化的五种方式
set @用户变量名=值;
set @用户变量名:=值;
select @用户变量名:=值;
select @用户变量名:=值;
select 字段 into @变量名 from 表
2.用户变量的赋值
set @变量名=值;
不需要指定类型在赋值的时候自动匹配类型
3.用户变量求和案例
set @m=1;
set @n=2;
set @sum=@m+@n;
select @sum;
4.局部变量的声明和声明初始化
declare 变量名 类型;
declare 变量名 类型 default 值;
5.局部变量的赋值
set 局部变量名=值;
set 局部变量名:=值;
select @局部变量名:=值;
select 字段 into @局部变量名 from 表
6.局部变量的求和例子:
declare m int default 1;
declare n int default 2;
set sum=m+n;
select sum;
当然由于不在begin end中所以运行会报错但是语法没问题
2.4用户变量和局部变量的区别
二者不同在于用户变量作用域在当前会话,定义使用在会话中的任何一个位置,语法上必须加@符号,不用限定类型 局部变量作用域在begin,end中只能在这里边使用并且为第一句话,有时候在定义时不需要加@,需要限定类型
3.存储过程
3.1存储过程概念
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需要创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。有点类似java里边的方法
3.2存储过程的好处:
1.提高代码重用性
2.简化操作
3.减少编译次数并且减少和数据库服务器的连接次数,提高效率
这里的减少编译次数指当我们第一次调用时系统会进行编译,第二次再调用的时候用第一遍编译好的代码 关于减少连接服务器次数。一般都是一条sql语句会和服务器有一次联系,存储过程中有多条sql语句在一起只与服务器建立一次联系,存储过程里边的sql语句是不能修改的
3.3存储过程使用流程
1.创建存储过程
create + procedure + 存储过程名(参数列表)
+ begin
+ end
2.存储过程的参数列表;
每个参数包含三部分:参数模式 参数名 参数类型,存储模式可以有多个参数
3.参数模式(等下例子详讲)
in:参数可以作为输入
out:参数作为输出
inout:既可以作为输入又可以作为输出
4.调用语法:
call+存储过程名(实参列表)
5.设置存储过程的结束标记语法:
delimiter+结束标记
6.使用存储过程注意点
1.存储过程必须设置结束标记
2.如果存储过程只有一句话那么begin,end可以省略
3.存储过程中每条独立的sql语句都要有分号
7.例子详解
博主之后的例子都会用到这个表
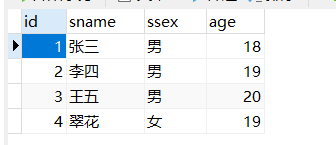
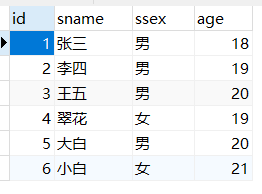
例子1(空参存储过程):在student表中加入两个新的同学
delimiter $
create procedure my1()
begin
insert into student() values(5,"大白","男",20),(6,"小白","女",21);
end $
call my1();//这个是调用
运行完毕后,表中数据如图:
例子2(带in模式的存储过程):在student表中查找大白和小白两个新同学的信息,并且修改小白同学的性别为人妖
delimiter $
create procedure my2(in name1 varchar(4),in name2 varchar(4))
begin
select * from student where sname=name1 or sname=name2;
update student set ssex="人妖" where sname=name1;
end $
call my2("小白","大白") ;
例子3(带out模式的存储过程):我们查找小白同学的性别并且返回出来
delimiter $
create procedure my3(out sexx varchar(4))
begin
select ssex into sexx from student where sname="小白";
end $
call my3(@ssex);
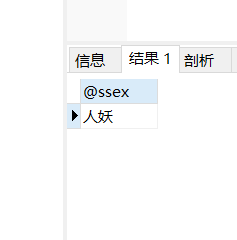
ssex和sexx相当于值传递
ssex into sexx:相当于把查询的结果赋值给这个可以输出的局部变量
inout就是传入和传出都用这一个inout定义的参数
如果我们不在变量的前面添加参数的模式
3.3删除和查看存储过程
1.删除存储过程
drop procedure+存储过程名
注意:这里只能单独删除
2.查看存储过程
show create procedure +存储过程名
3.3存储过程的优缺点
优点
1)存储过程是预编译过的,执行效率高。
2)存储过程的代码直接存放于数据库中,通过存储过程名直接调用,减少网络通讯。
3)安全性高,执行存储过程需要有一定权限的用户。
4)存储过程可以重复使用,减少数据库开发人员的工作量。
缺点
1)调试麻烦,但是用 PL/SQL Developer 调试很方便!弥补这个缺点。
2)移植问题,数据库端代码当然是与数据库相关的。但是如果是做工程型项目,基本不存在移植问题。
3)重新编译问题,因为后端代码是运行前编译的,如果带有引用关系的对象发生改变时,受影响的存储过程、包将需要重新编译(不过也可以设置成运行时刻自动编译)。
4)如果在一个程序系统中大量的使用存储过程,到程序交付使用的时候随着用户需求的增加会导致数据结构的变化,接着就是系统的相关问题了,最后如果用户想维护该系统可以说是很难很难、而且代价是空前的,维护起来更麻烦。
4.函数
4.1函数简介
1.可以参照存储过程,两者概念一样
2.函数在mysql中的好处和存储过程类似
4.2函数的基础语法(例子会和流程控制结构一起讲):
1.创建函数:
create function 函数名(参数列表) returns 返回类型
begin
函数体
end
这里的每一个参数包含参数名和参数类型,函数体肯定有return语句
2.函数的调用
select 函数名(参数列表)
参数列表是先参数名再参数类型
3.查看函数
show create function +函数名
4.删除函数
drop function+函数名
4.3函数和存储过程的区别:
1.存储过程可以有0或多个返回(就是out类型的数据),适合批量的插入和更新
2.有且仅有一个返回值,适合做处理数据后返回一个结果
5.流程控制结构
5.1流程控制结构分类
顺序结构,分支结构,循环结构
5.2分支结构
1.if结构:
if 条件1 then 语句1
elseif 条件2 then 语句2
…
else 语句n
end if;
应用范围:begin end中
例子:
delimiter //
CREATE FUNCTION a1(score int) RETURNS char
BEGIN
IF score>=90 AND score<=100 THEN return 'A';
ELSEIF score>=80 THEN return 'B';
ELSEIF score>=60 THEN RETURN 'C';
ELSE RETURN 'D';
END IF;
END //
SELECT a1(88)
if函数
if(表达式1,表达式2,表达式3)
执行顺序:如果表达式1成立则返回表达式2的值,否则返回表达式3的值
例子:
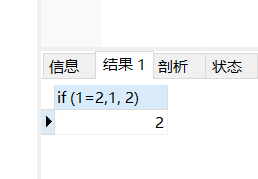
select if (1=2,1, 2)
运行结果:
2.case结构:
语法:
case结构:作为独立的语句

case结构:作为表达式

两种case结构作为表达式使用,可以嵌套在其他语句种使用,可以放在任何地方,begin end里边或外边
作为独立的语句使用只能放在begin end里
例子(作为独立的语句):
delimiter //
CREATE PROCEDURE a2(in score int)
BEGIN
CASE
WHEN score>=90 AND score<=100 THEN SELECT 'A';
WHEN score>=80 THEN SELECT 'B';
WHEN score>=60 THEN SELECT 'C';
ELSE SELECT 'D';
End case;
end //
call a2(88) //
5.3循环结构
1.while循环
【标签】while+循环条件 do
循环体
end while+【标签】
想用循环控制就要用标签
当然也可以不用标签:
例子:
delimiter //
CREATE PROCEDURE a3(in score int)
BEGIN
DECLARE i int DEFAULT 4;
WHILE i<=score DO
INSERT into sanguo VALUES(i,"赵云","女");
SET i=i+1;
END WHILE;
end //
call a3(10) //
我们用标签:
delimiter //
CREATE PROCEDURE a8(in score int)
BEGIN
DECLARE i int DEFAULT 40;
a:WHILE i<=score DO
IF i=50 or i=60 THEN INSERT into sanguo VALUES(i,"赵云","女");
end if;
SET i=i+1;
END WHILE a;
end //
call a8(70) //
2.loop循环
【标签】loop
循环体
end loop 【标签】
3.repeat循环
【标签】repeat
循环体
until 结束循环条件
end repeat 【标签】