Variance
方差是model层面的

6个平行宇宙,则有6个样本集\(\{x^1,x^2,...,x^N\}\),有6个\(m\),6个\(s\)(这里的\(s\)是数据层面的),\(s\)不是真实\(\sigma\)的无偏估计
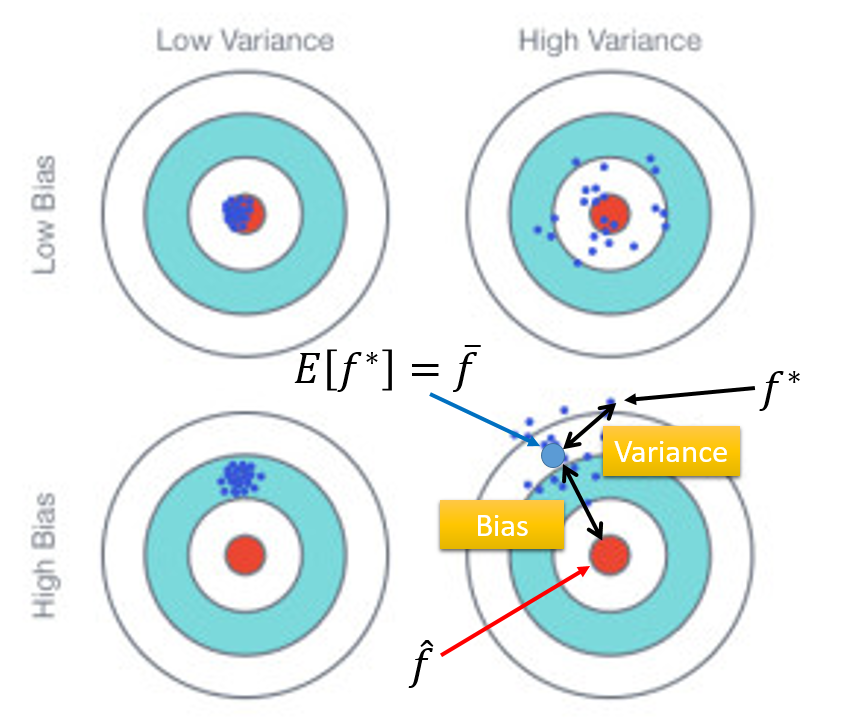
每个\(f^*\)都是一个拟合的model,\(f^*\)的期望值为\(\bar{f}\),\(\hat{f}\)为真实model
\(f^*\)的error来自于bias和variance
100个平行宇宙里,拟合一百个model
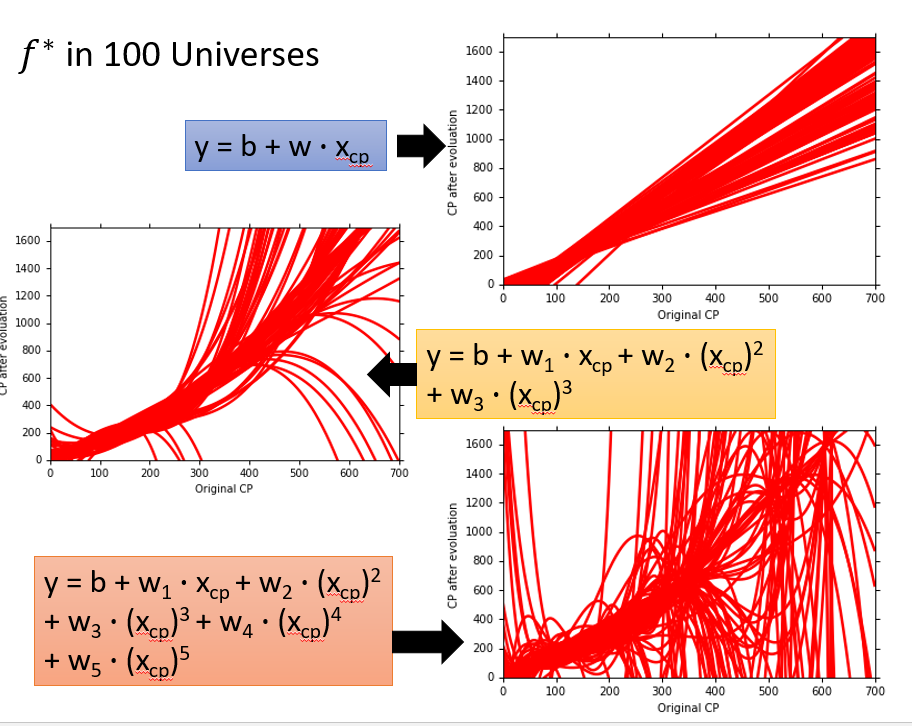
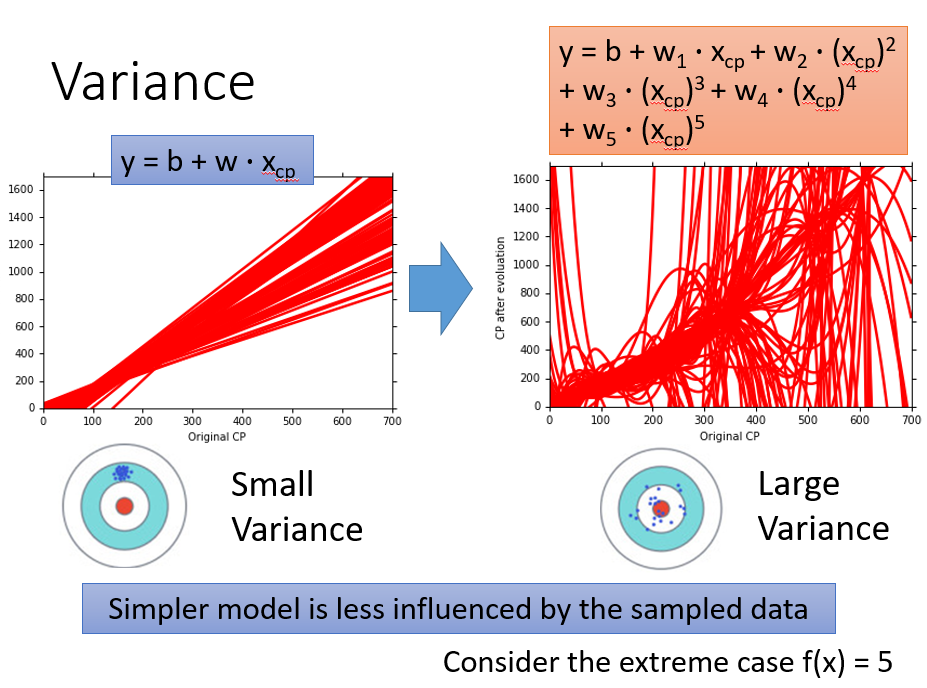
简单的model比较集中,复杂的model比较散乱
为什么复杂的model散乱(方差大)?
简单的model不容易受到不同data的影响,而复杂的model容易受到不同data的影响
比如极端model,\(f(x)=c\),不同宇宙的model是一样的,方差为0
Bias
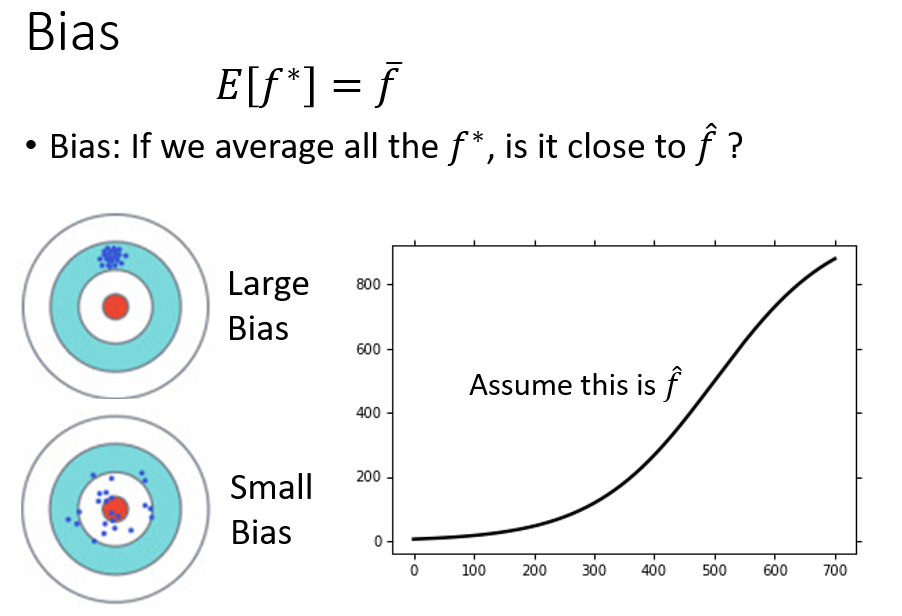
\(f^*\)的平均\(\bar{f}\)与\(\hat{f}\)的距离小,则Bias小;\(f^*\)的平均\(\bar{f}\)与\(\hat{f}\)的距离大,则Bias大
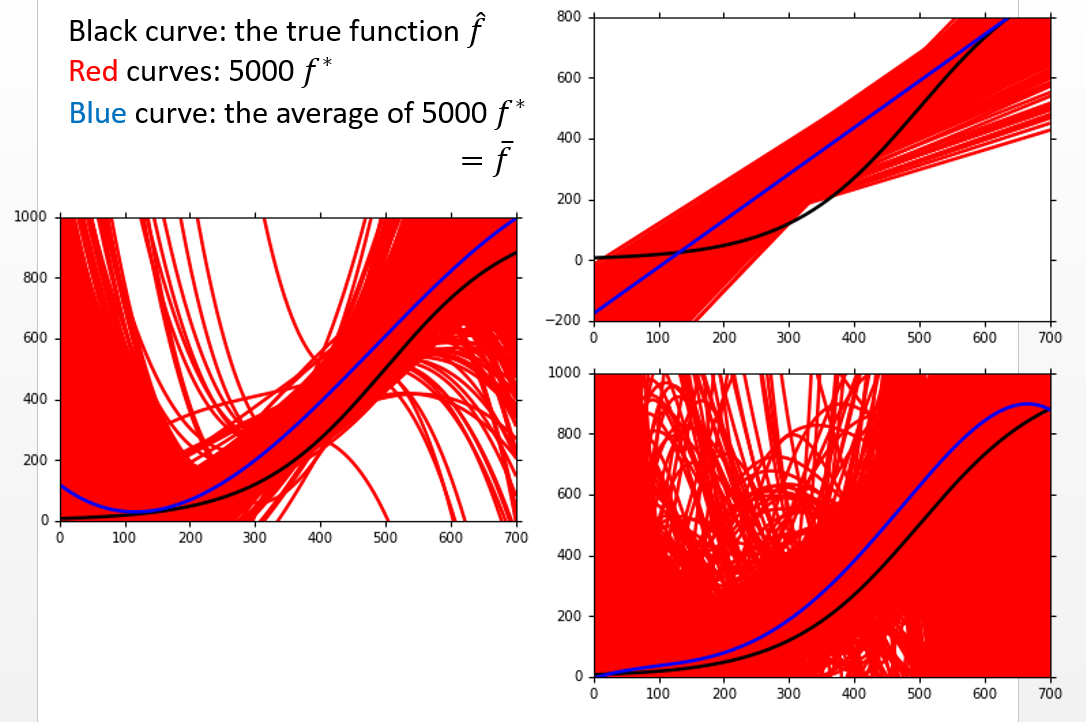
假设样本是从\(\hat{f}\)中抽样的,抽样5000次
1次项,5000个拟合曲线比较集中,但平均起来与\(\hat{f}\)比较远
3次项,拟合曲线比较散乱,平均与\(\hat{f}\)更接近
5次项,拟合曲线最散乱,平均与\(\hat{f}\)最接近
简单model Bias大,复杂的model Bias小
为什么复杂的model偏差小?
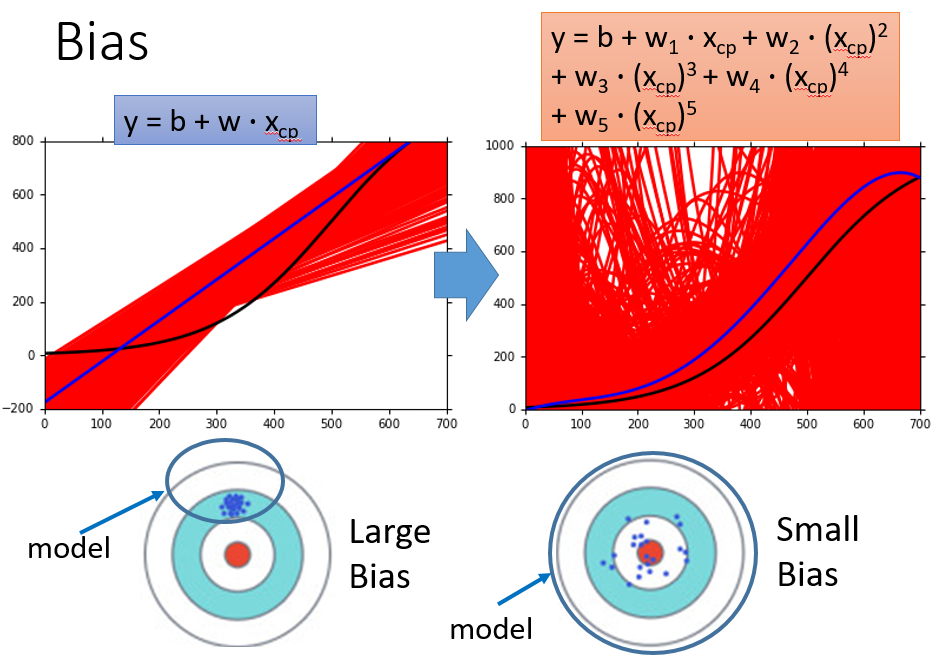
model 是从function space 挑选的,简单的model space 比较小,可能没有包含\(\hat{f}\)
复杂的model space 大,可能包含\(\bar{f}\) ,虽然\(f^*\)散布比较开(由于数据量小、抽样等问题),但是平均\(\bar{f}\)与\(\hat{f}\)更接近