论文标题:The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification
来源:IEEE TIP 2020
针对目标:细粒度图像分类
下载地址:https://arxiv.org/abs/2002.04264
github地址:https://github.com/PRIS-CV/Mutual-Channel-Loss
首先,说说这篇论文的优点:简单,高效,易于实现。这篇论文相比于SOTA的其余方法,代码量少,只是在常用的网络结构上加入了一个辅助结构。并且,该辅助结构没有引入额外的网络参数,只包含正则化,池化等操作,就达到了SOTA的效果。
创新点: 在细粒度图像分类任务中引入了互通道损失 ,由 判别性组件 和 多样性组件 组成。
网络结构
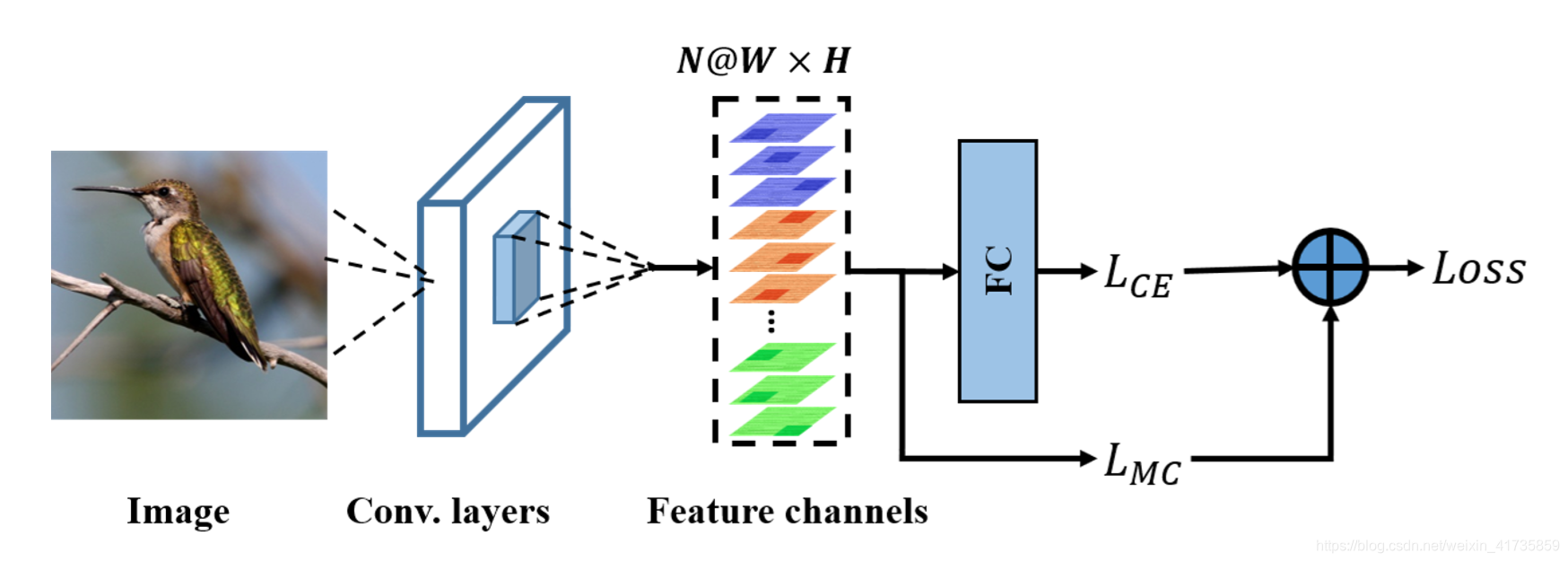
通过观察网络结构图,可以看出来:该网络仅仅是在常规的图像分类网络结构下,加入了一个互通道损失
。Feature channels 是之前 Conv.layers 的最后一个卷积层输出的特征图,
使得网络专注于全局判别性区域,
则使得网络专注于局部判别性区域。
邀请主角登场 – MC-LOSS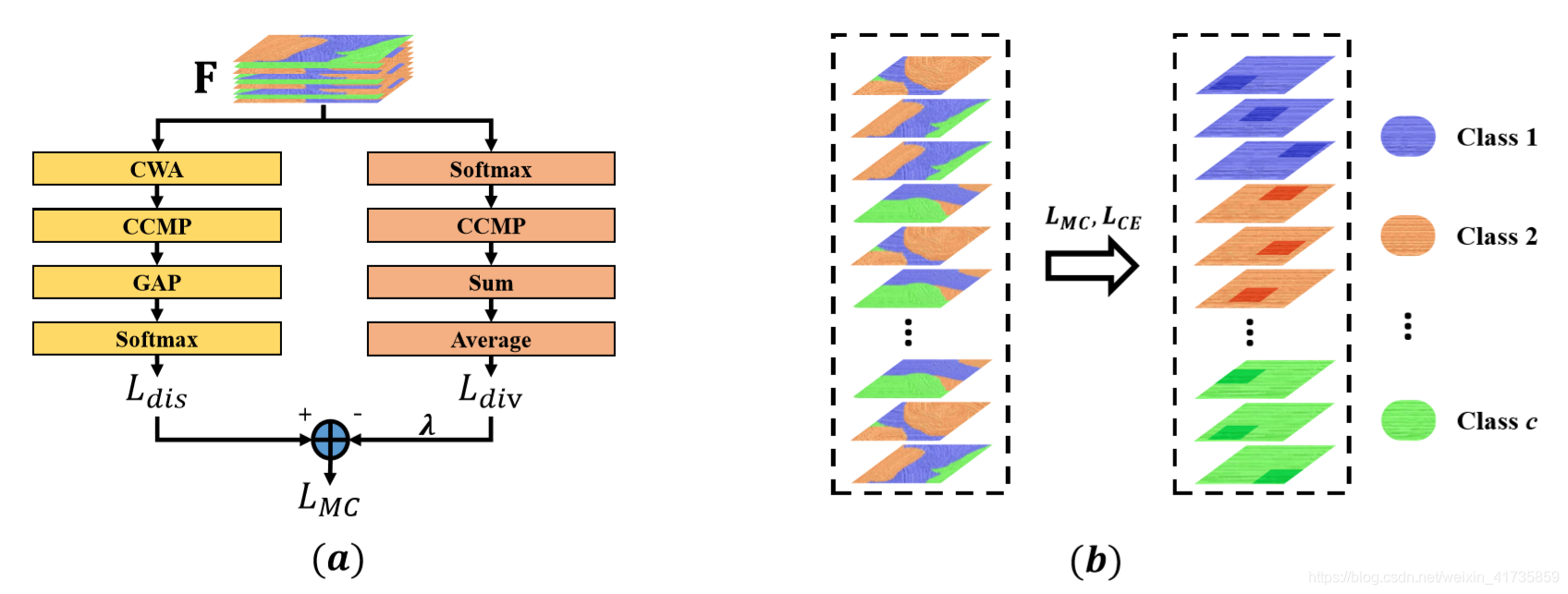
(a)图左侧通道的判别性组件,(a)图右侧通道的多样性组件。(b)图表示使用了
前后的特征图变化,可以看出,使用
之后,得到了了判别性区域,且不同特征图的判别性区域各不相同。
假设,(a)图中的输出特征图
为
通道,总共
个类别,
表示每个类别中特征图的个数。那么:
.
判别性组件的构成:
- CWA: Channel-Wise Attention,通道注意力机制。与其他论文中(如SE-Net)的通道注意力机制有所差别,虽然也是通道加权,但是本论文的权值只有0和1。所以,本文的CWA有点类似于Dropout随机失活,不过Dropout是在空间域,CWA是在通道域。比如,有10个类别(c=10),共有40通道的特征图(N=40),此时每个类别4个通道的特征图(ξ=4)。 经过失活概率为0.5的CWA之后,虽然输出也是
通道,但是其中有
通道的特征图中所有的值都归为0了。并且失活与类别也有关,相应的,每个类别中通道失活概率也为0.5,也就是说每个类别有2个通道(ξ/2)失活了。
CWA的作用: 强制让每个通道努力学到充足的判别性信息。因为每次迭代的时候,原先每个类别特征图有一半(ξ/2)都置零了,为了能够进行分类,那剩下的特征图的任务就更大,更需要去学习判别性信息。 - CCMP: Cross-Channel Max Pooling,跨通道的最大池化。将每个类别中所有通道的最大响应值全部放在一张特征图上。原则上,越具有判别性的点,响应越大。关于CCMP的具体实现,可以参考我的另一篇博客:cross channel pooling 的原理与代码实现
CCMP的作用: 通道降维,得到c通道的特征图。 - GAP: GlobalAveragePooling,全局平均池化,应用非常广泛,能够将(b, c, w*h)的特征图池化为(b, c, 1)的特征图。
GAP的作用: 空间降维。 - Softmax: 打分,用于分类。
判别性组件的功能: CWA和CCMP的协作,使得网络能够专注于各种类别的判别性区域。
多样性组件的构成:
虽然判别性组件能够专注于各种类别的判别性区域,但是,仍然无法保证大部分判别性区域都被定位了,于是引入了多样性组件。
- Softmax: 正则化。
- CCMP: 和上文中的CCMP一样的作用,得到c个通道的特征图。
- Sum: 将每个特征图上所有元素求和,每个通道只有一个元素。
- Average: 将所有通道的值求平均。
越大越好。
越大,每个类别中
个通道的特征图,专注的区域越分散。
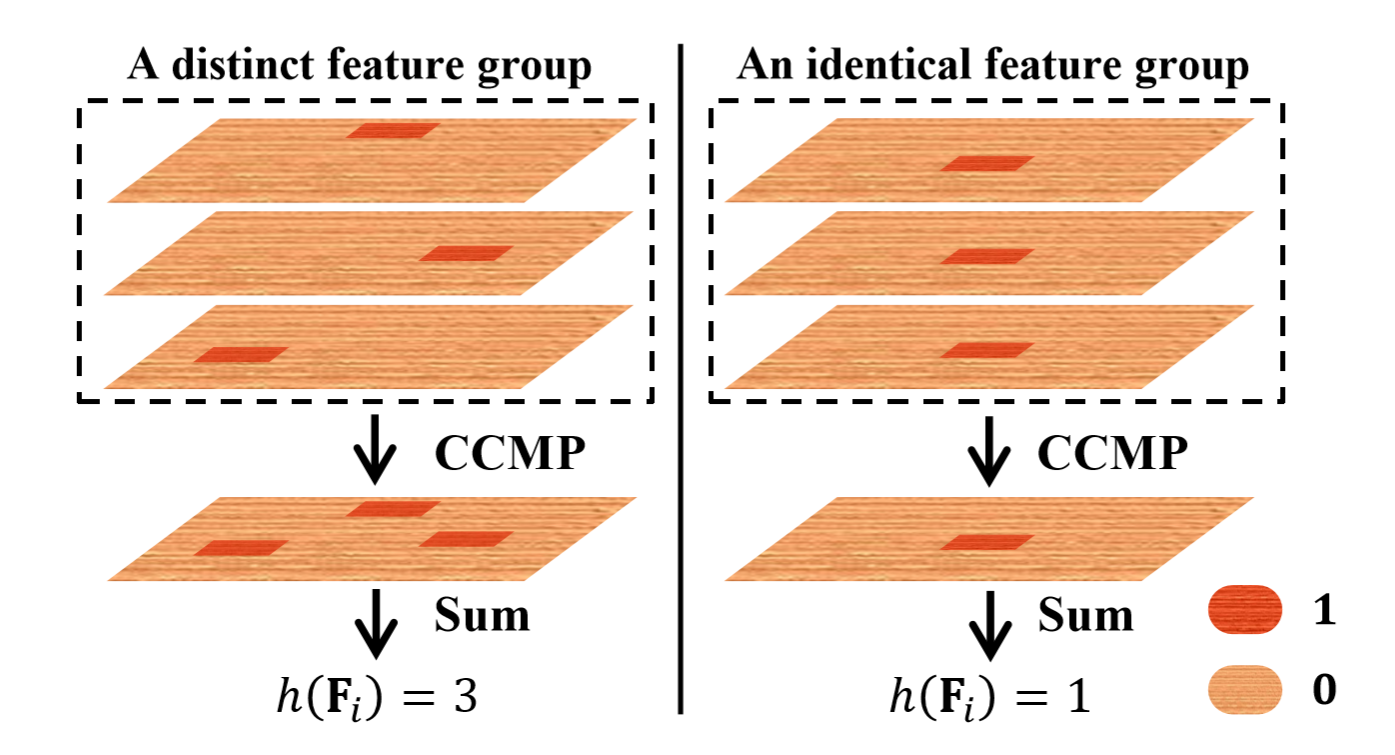
如上图,假设输入特征图经过softmax之后,得到极端情况,每张图上,只有一个点为1(红色点),其余全为0(橙色点)。再经过CCMP和Sum后计算结果。当判别性区域越分散,累加值越高(ξ)。当每个特征图上,判别性区域都一样时,那么CCMP之后的特征图,只有一个点为1,于是Sum之后,累加值最小(1)。另外,多样性组件的存在是以判别性组件的存在为前提,若没有判别性组件,那么多样性组件将毫无意义。
MC-LOSS:
.
实验
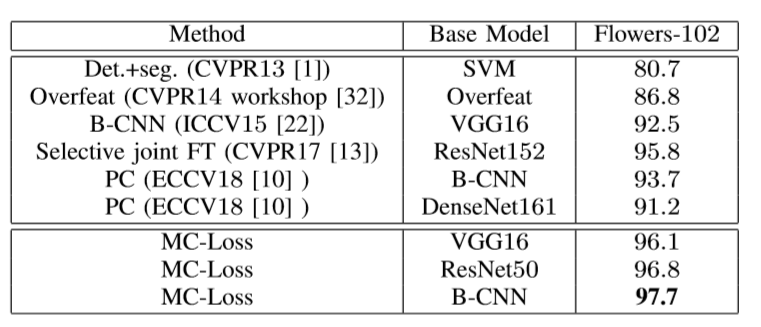
1.与SOTA模型比较(加入预训练模型):

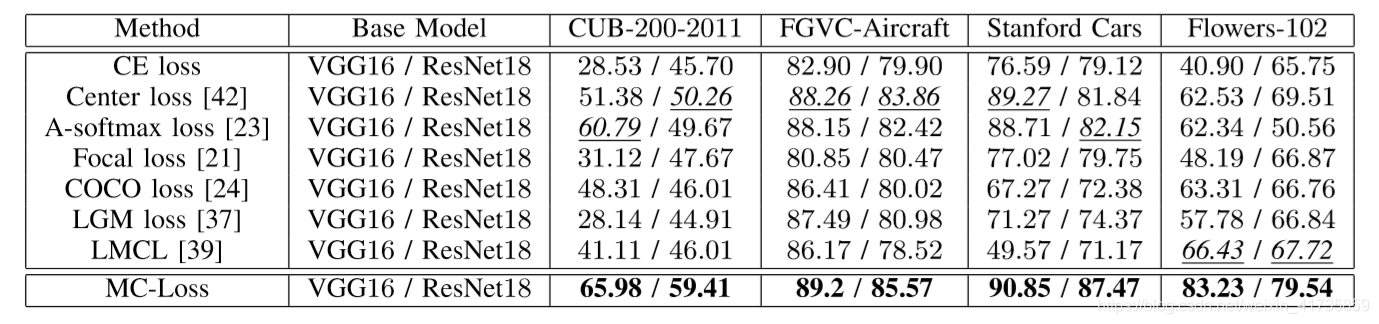
2.与其他分类损失函数比较(未加入预训练模型):
复现
在未加入预训练模型使用VGG16作为主干网络复现时,MC-Loss(ξ=3)的方法下,鸟类数据集准确率达到了67.33(原文65.98),车辆数据集准确率达到了90.34(原文90.85)。
特征图可视化效果:
1.属于某一类的特征图(文中每ξ个特征图负责一个类别),前三列表示三个特征图,最后一列为前三列叠加效果。
 2.不属于某一类的特征图
2.不属于某一类的特征图
 特征图注意力区域可视化的方法可以参考:特征图可视化为类激活图(CAM)
特征图注意力区域可视化的方法可以参考:特征图可视化为类激活图(CAM)
参考链接:
https://blog.csdn.net/u013347145/article/details/105568990
https://zhuanlan.zhihu.com/p/106922799