写在前面:我是「云祁」,一枚热爱技术、会写诗的大数据开发猿。昵称来源于王安石诗中一句
[ 云之祁祁,或雨于渊 ],甚是喜欢。
写博客一方面是对自己学习的一点点总结及记录,另一方面则是希望能够帮助更多对大数据感兴趣的朋友。如果你也对数据中台、数据建模、数据分析以及Flink/Spark/Hadoop/数仓开发感兴趣,可以关注我的动态 https://blog.csdn.net/BeiisBei ,让我们一起挖掘大数据的价值~
每天都要进步一点点,生命不是要超越别人,而是要超越自己! (ง •_•)ง
文章目录
一、前言
在小破站看了晨蕊关于Flink的分享视频 https://www.bilibili.com/video/BV1TE411L7zV/?spm_id_from=333.788.videocard.4,这篇博客主要对这次分享的一些知识点做些整理。
看大佬,人美技术牛! ( •̀ ω •́ )✧

二、实时数仓基本架构
以下是菜鸟作为物流扛把子,它对于数据的需求,主要有以下四点:

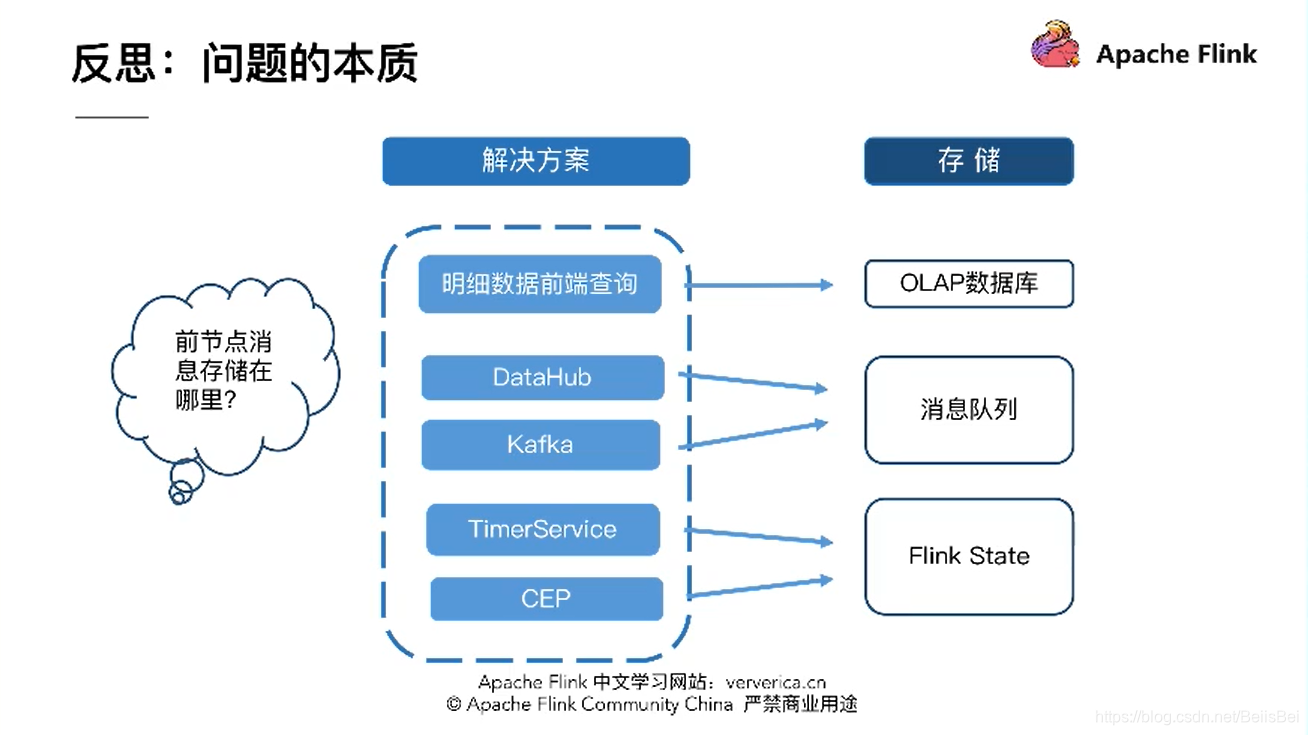
实时的数据,它存在的计算难点如下。我们知道,实时消息存在很多不可确定性,例如社交媒体,可能一个爆点,就会带来数据的流量峰值;而且有的消息也会存在迟到的情况,大佬今天主要分享的就是对未到达消息的处理。
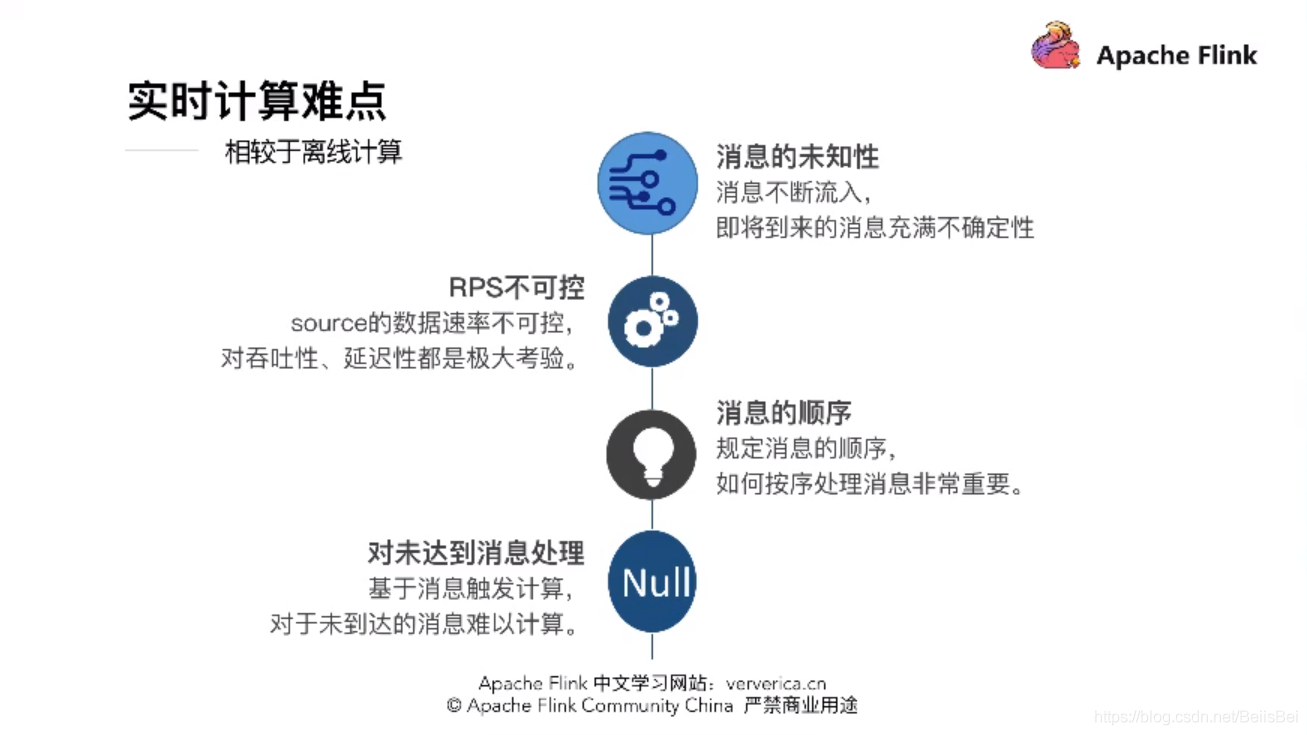

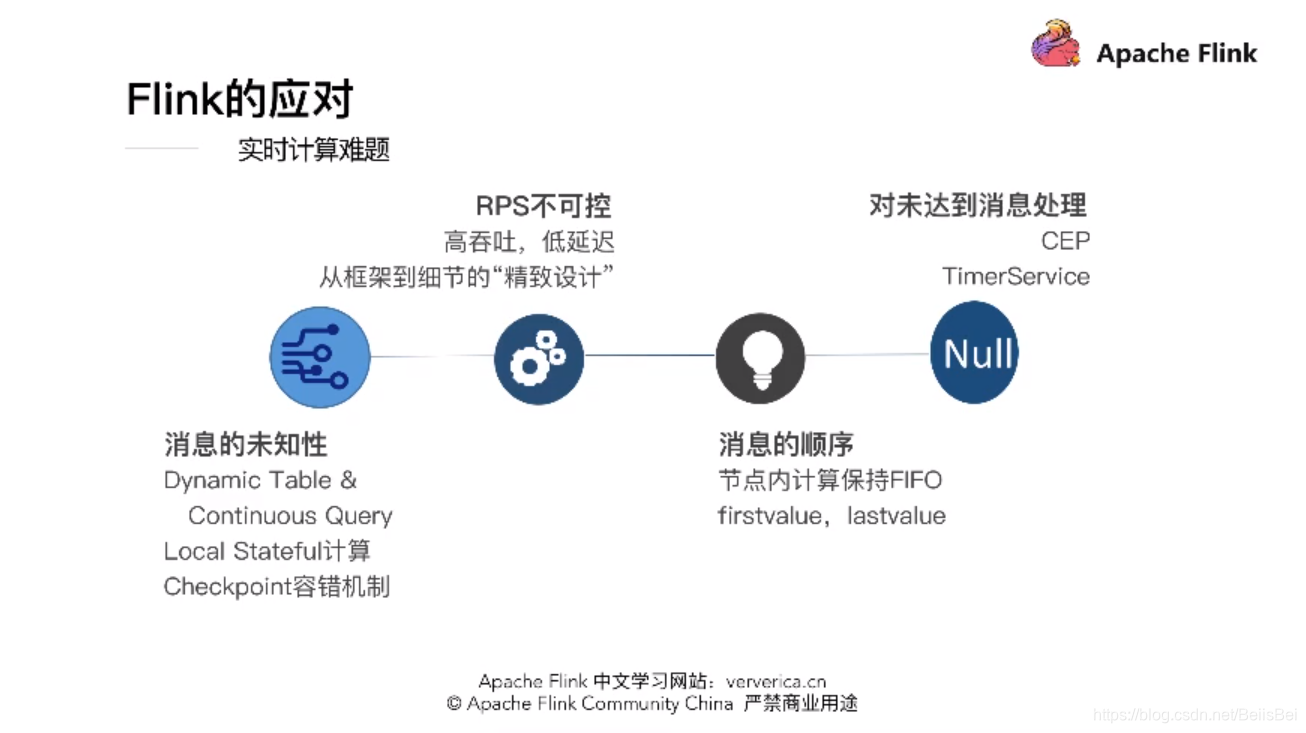
Flink 将动态的消息转化为动态的表,对于表的操作就是 Continuous Query ,理解为对一张张静态的表的处理。Flink 从框架的精妙的设计,都在追求高吞吐和低延迟的平衡。 对未到达的消息,可以用CEP和TimeService这些功能API进行处理。
以下是菜鸟的实时数仓架构:
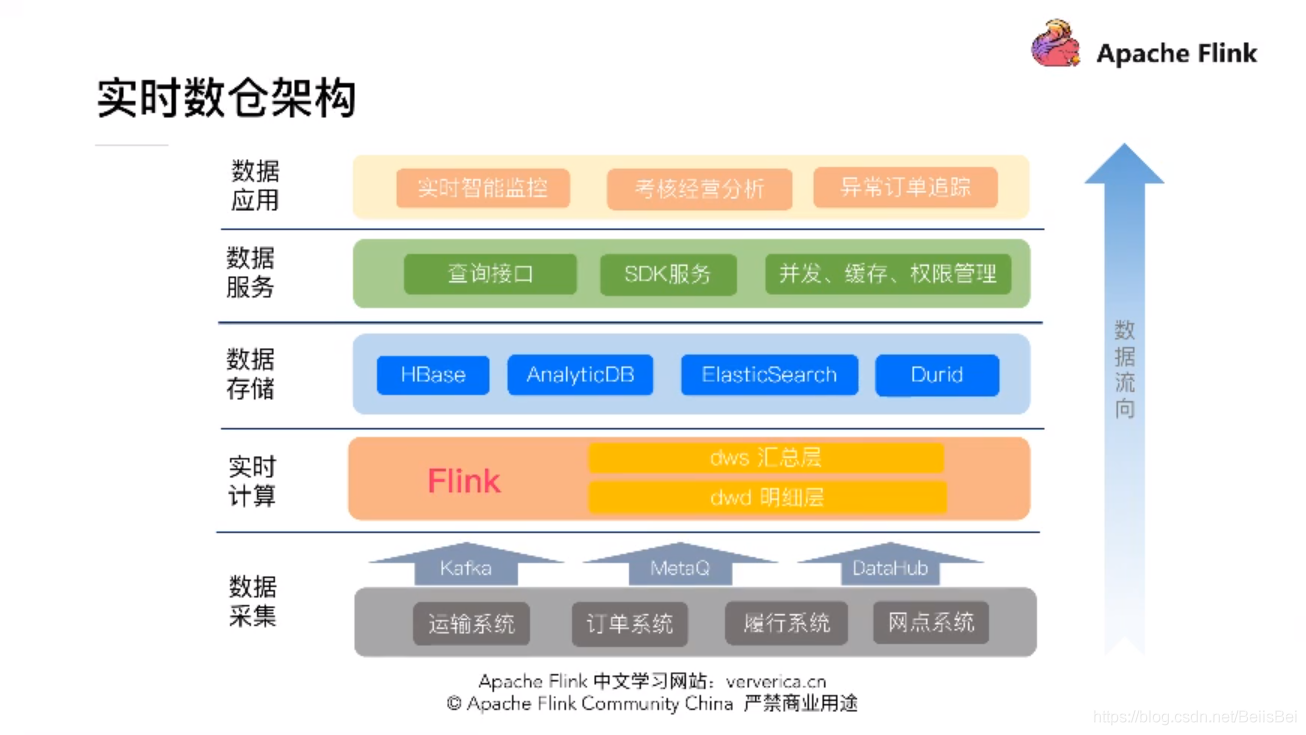
实时计算:两层分层计算,相对离线层次较少,主要是基于实时计算的低延迟的考虑,层次越少越好,以降低延迟。
数据存储:NoSQL 非关系型数据库 + ALOP 面向在线分析型数据库
数据服务:主要是屏蔽掉物理数据库查询的语法差异,数据库的设置差异,直接提供查询接口
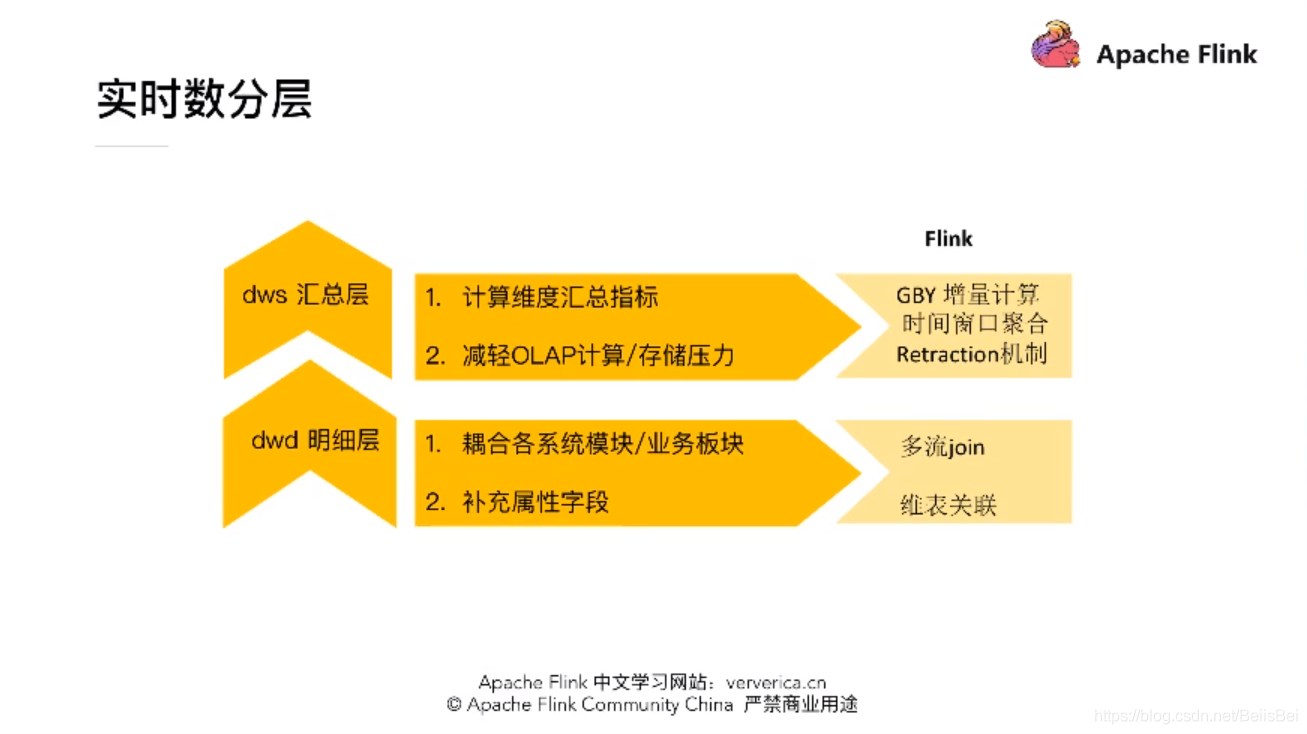
明细层:主要是耦合各个业务系统/模块,多流Join 将已经解耦的各个模块再耦合在一起,再通过关联静态维表来补充属性字段。
汇总层:尽量减轻OLAP存储的压力
三、难题:实时超时统计
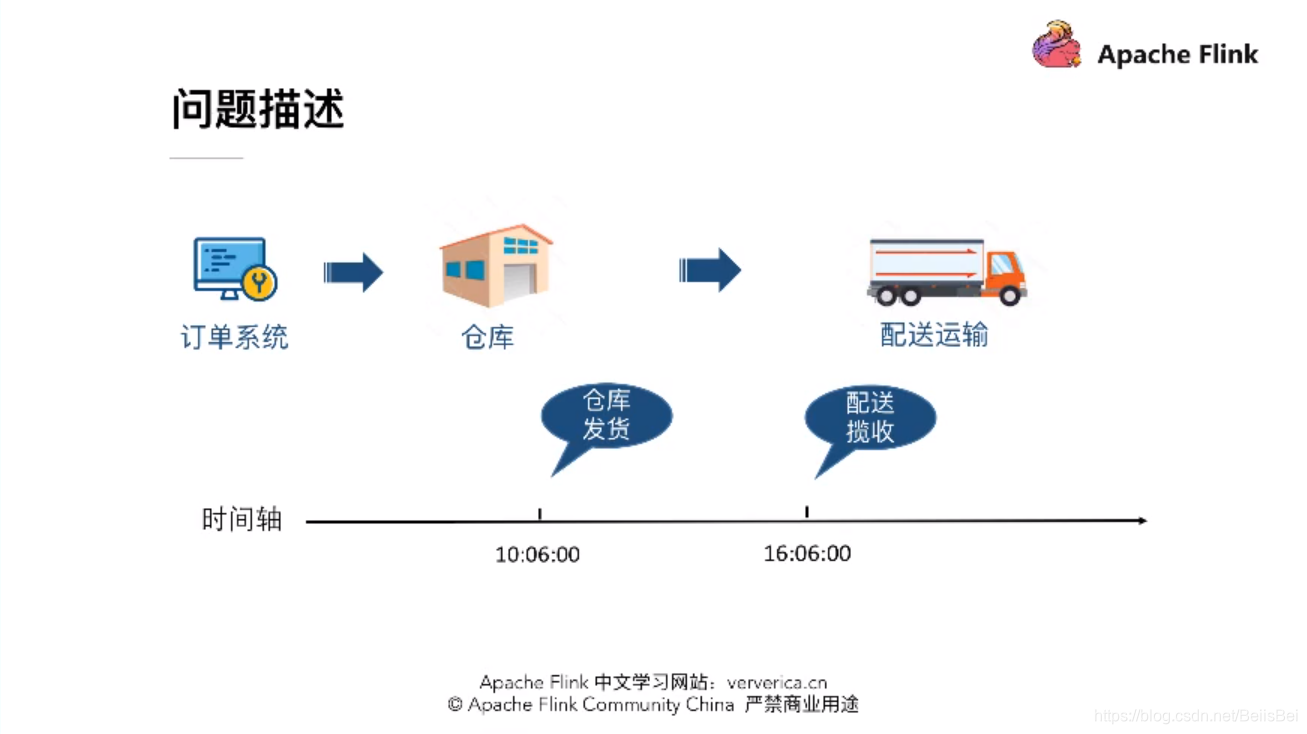
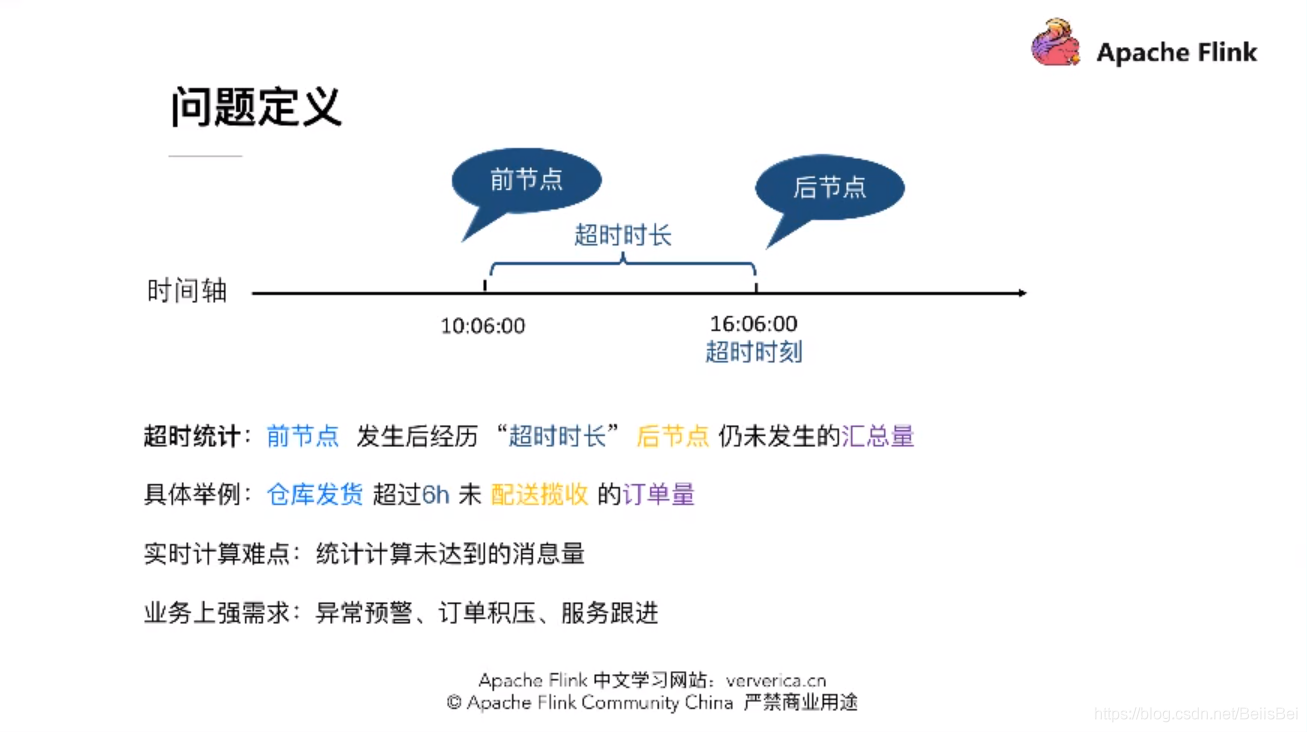
菜鸟刚开始的解决方案,但是存在以下的缺点:
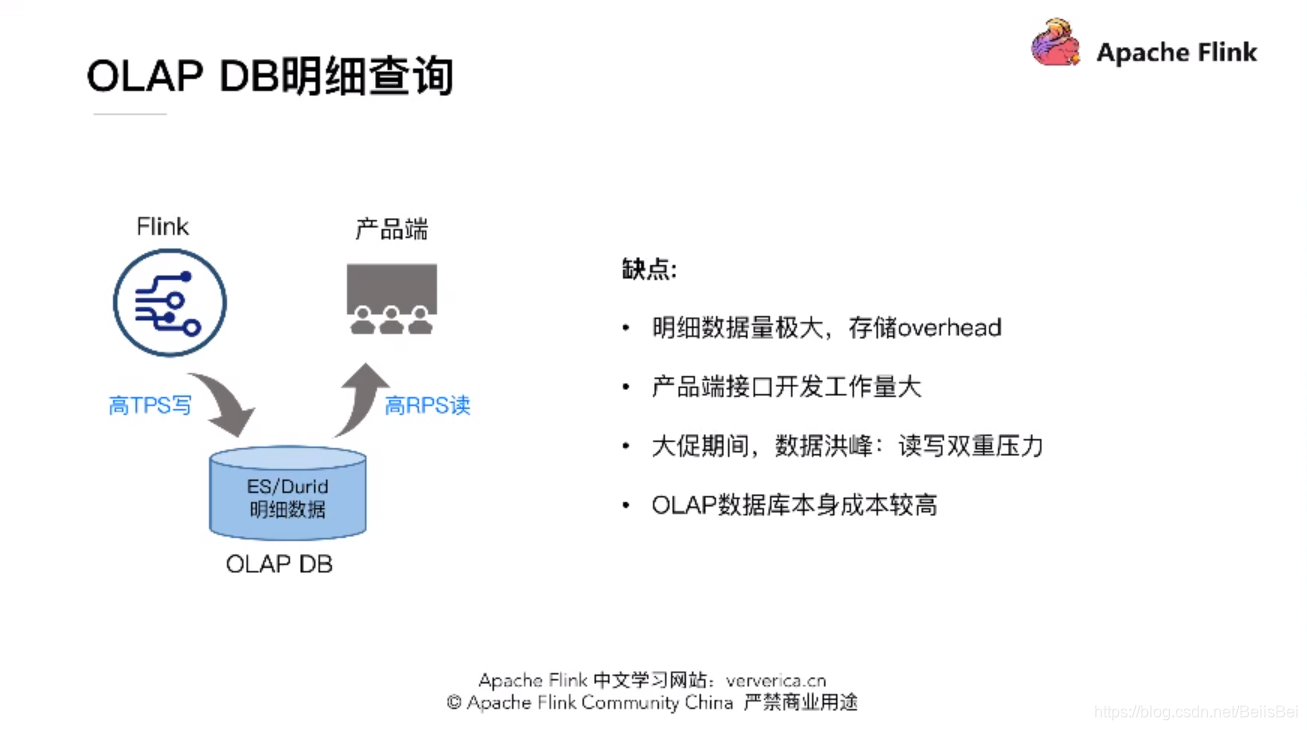
很明显,这个方案是不可行的,需要在Flink就解决问题。
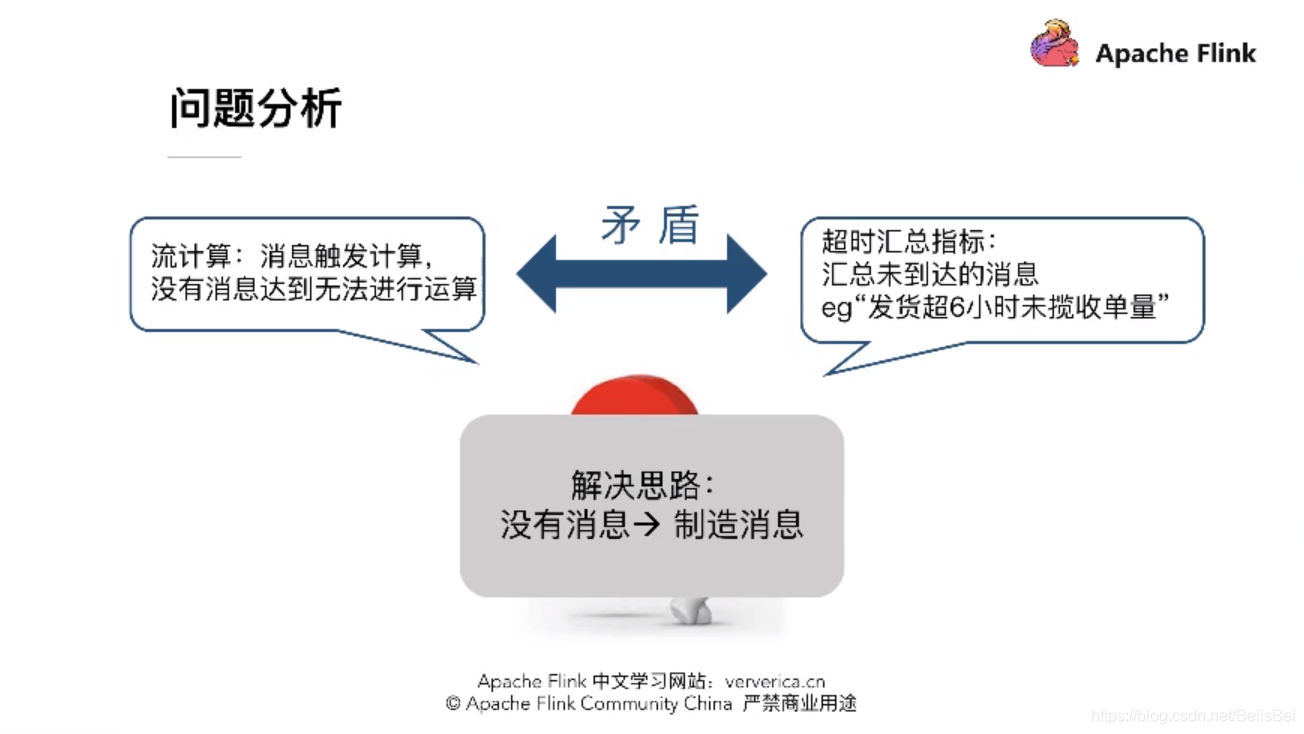
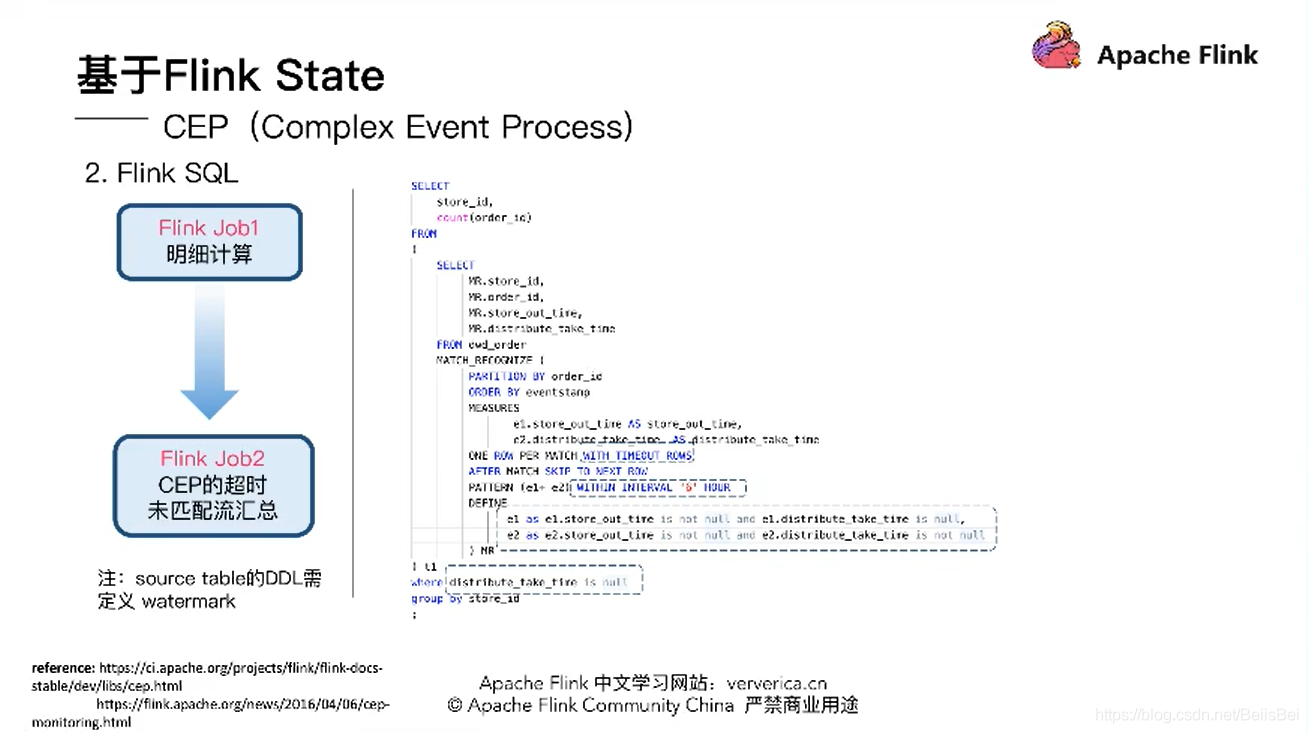
四、解决方案
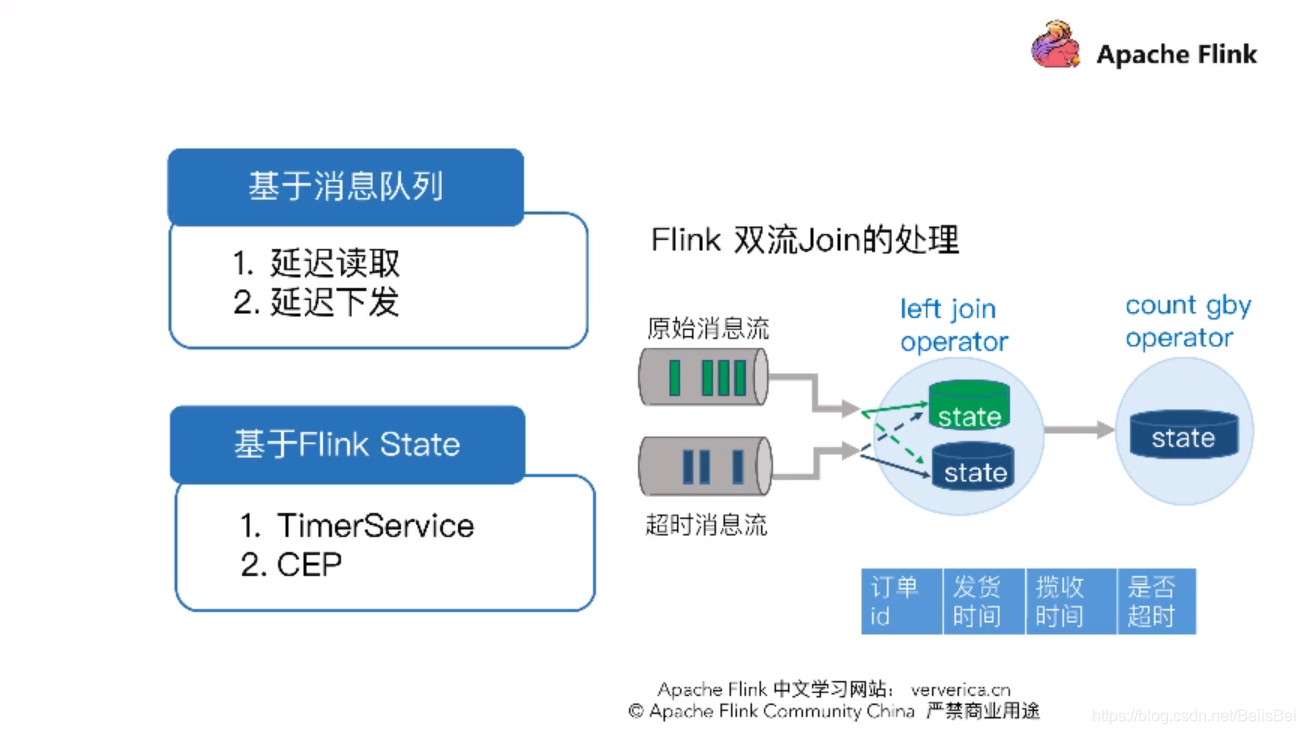
双流Join的原理,人为制造出超时消息,让它去触发它对左流原始消息流的查询,再触发它的计算。
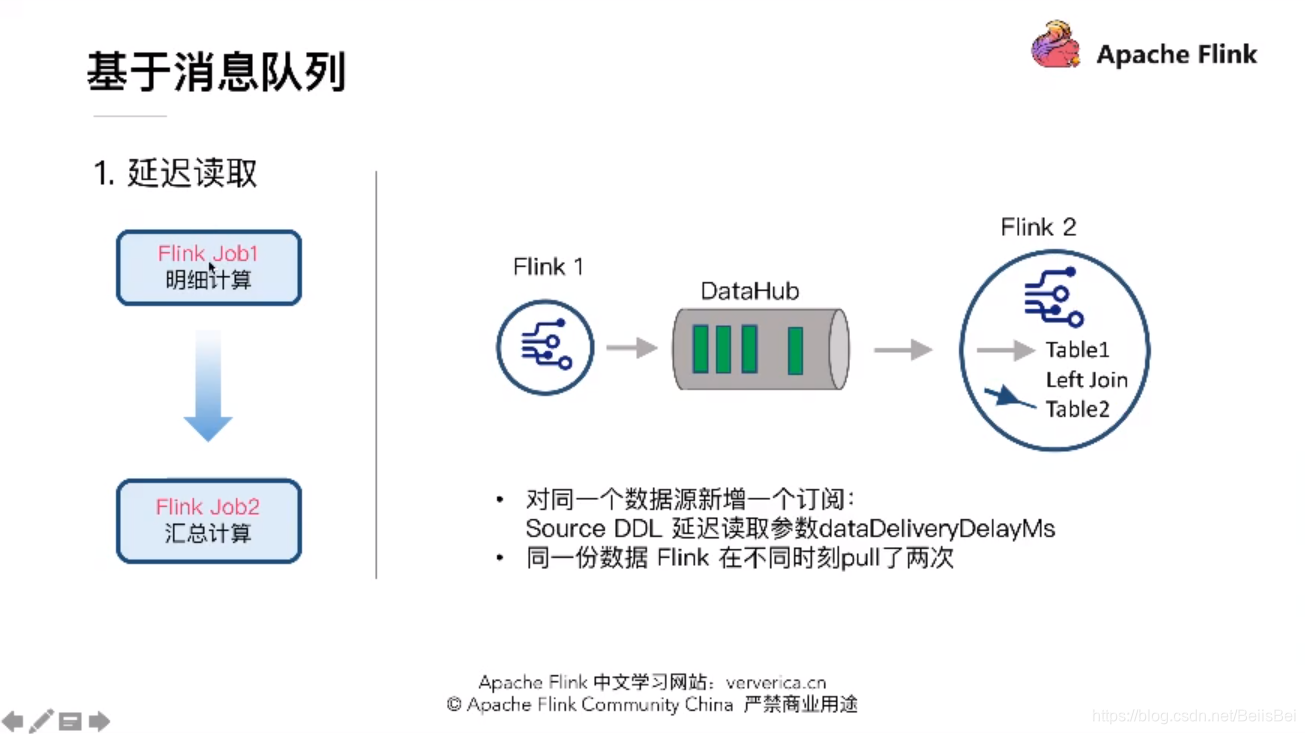
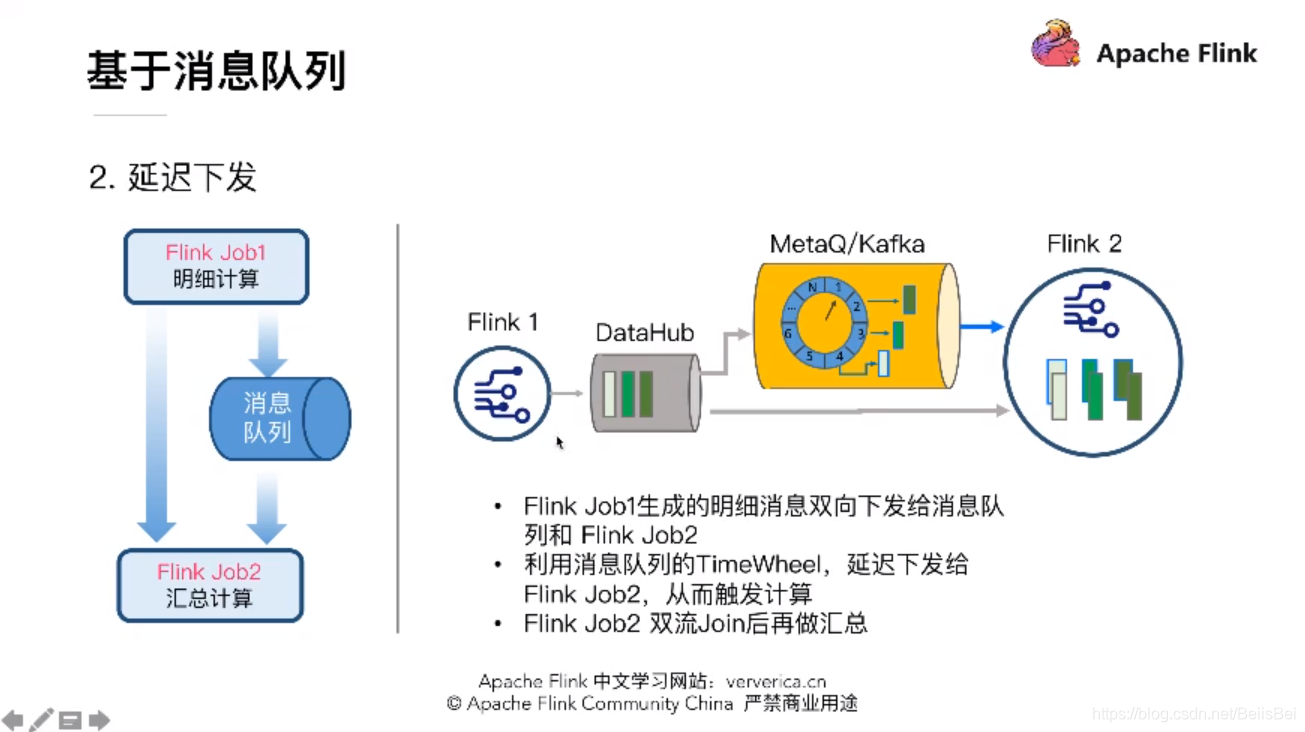
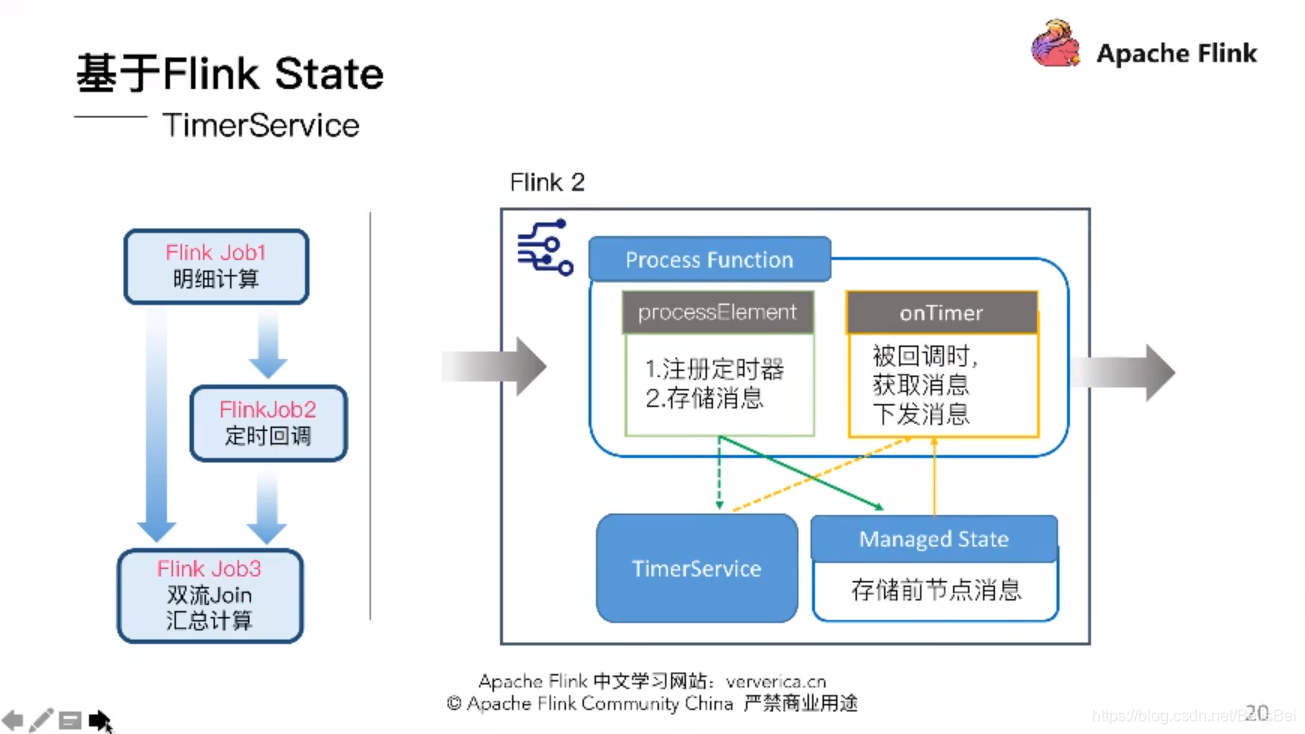
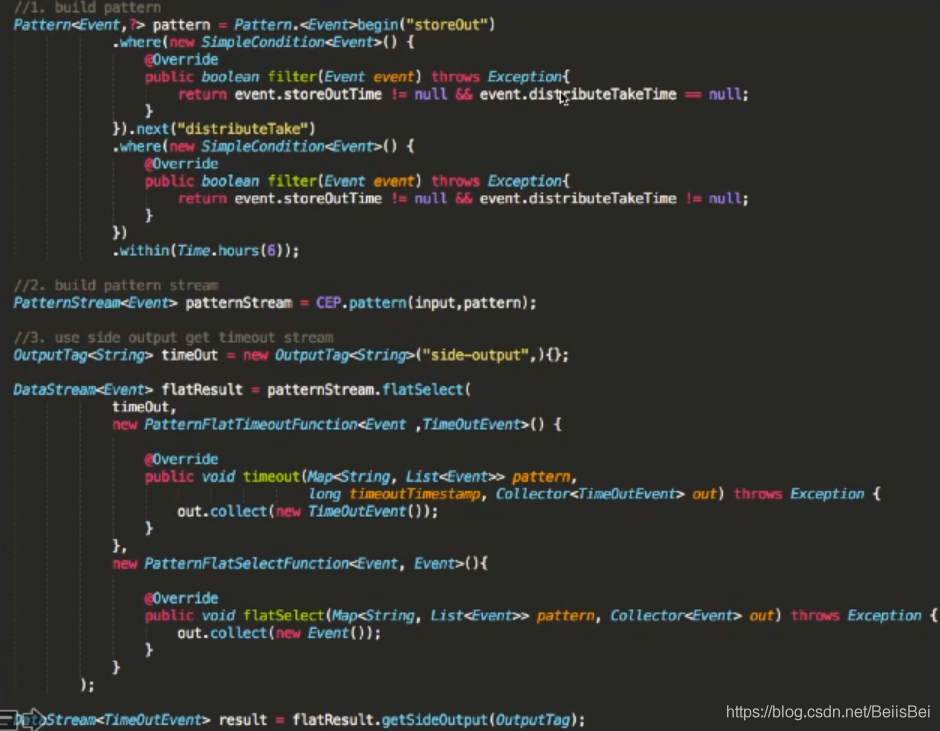
完全基于Flink,用三个Job就可以解决问题,得用到Flink最底层的API TimeService .全局定时器,这是一个比较完美的方案。
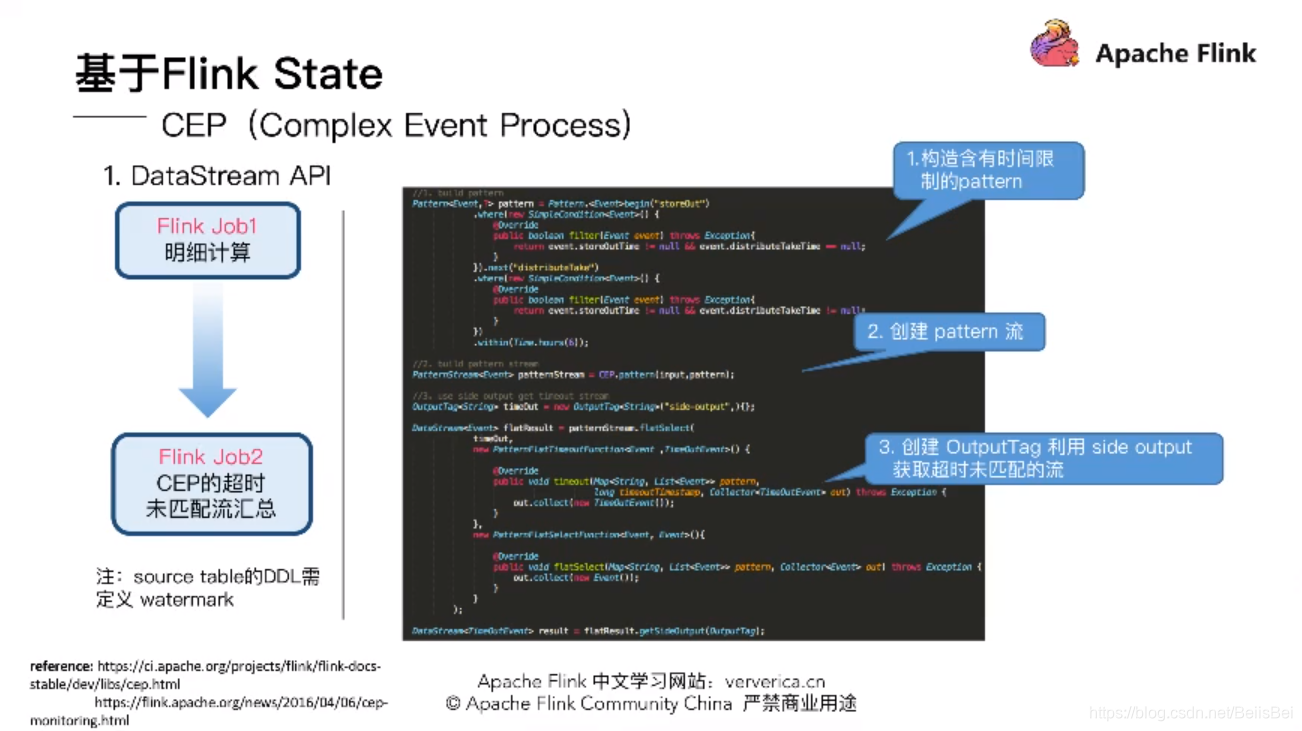
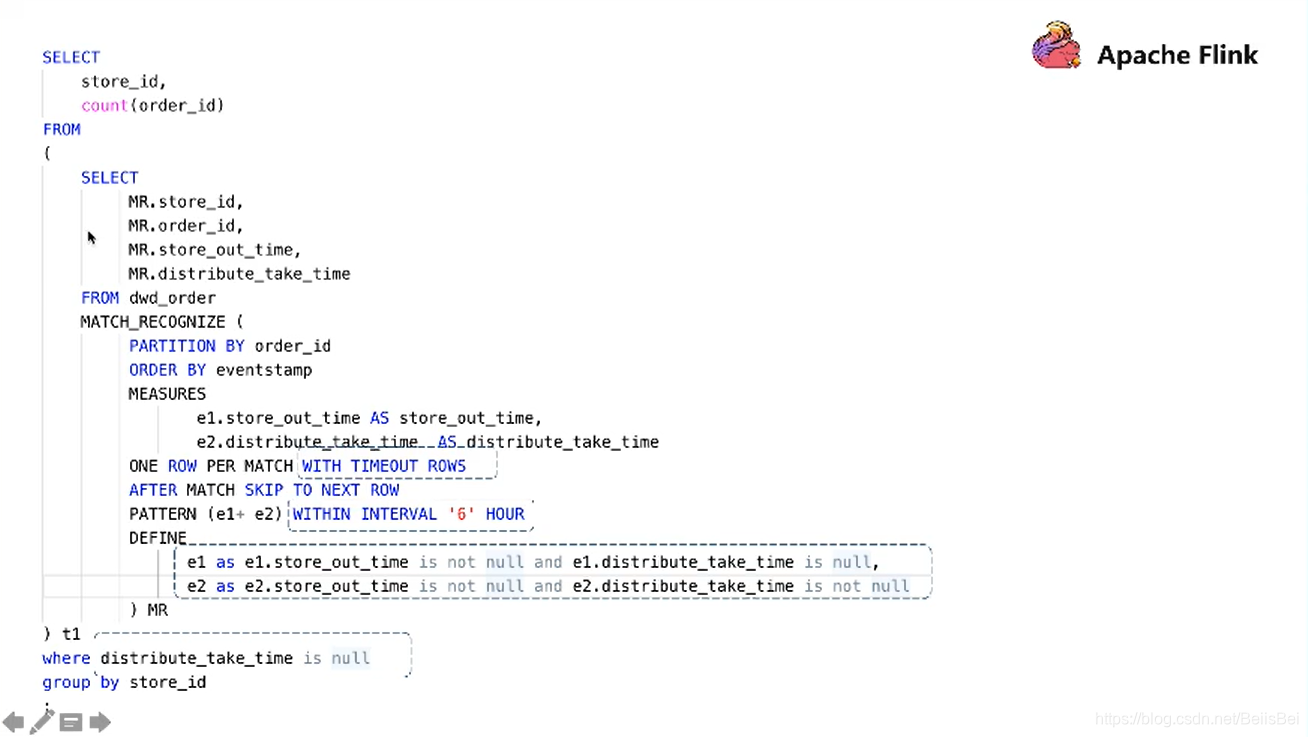
类似时间序列的正则匹配