Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation
摘要
场景文本检测在实时文本翻译、自动信息进入、盲人辅助、机器人感应等已有广泛应用。尽管很多被提出的方法用于水平和多方向文本,但检测弯曲文本仍然是一个挑战性的问题。为了解决该问题,我们提出了一种自适应文本区域表示的文本检测方法。对于一张输入的图片,一个网络首先被用来提取文本候选框,然后这些候选框通过另一个改善网络被验证以及改善。基于自适应文本区域表示的循环神经网络被提出用于改善文本区域,每次都预测一对边界点直到没有新的边界点被发现。通过这种方式,任意形状的文本区域被检测并以自适应数目的边界点来表示。这也给文本区域更加精确的描述。实验结果在CTW1500,TotalText,ICDAR2013,2015以及MSRATD500上都达到了state-of-the-art的水平。
引言
文本对于交流语义信息而言是最基础的媒介,在生活中无处不见,街景,商店门牌,产品包装,菜单等。自动检测识别场景文本对于许多应用程序来说是非常有益的,如实时文本翻译,盲人协助,购物,机器人,智能驾驶以及教育等等。一个端到端的识别系统通常由两部分组成:文本检测和文本识别。文本检测中,文本区域用边界框检测并包围。在文本识别,文本信息从检测的区域中进一步进行检索。文本检测是重要的一步对于端到端的文本识别。
而传统的OCR技术仅仅处理印刷文档字体,场景文本检测试图检测各种复杂的字体。由于复杂的背景和变化多样的字体,尺寸大小,颜色,语言,模糊条件以及方向。场景文本检测已经是一个非常具有挑战性的工作。由于复杂的背景,变化多样的字体,大小,颜色,语言,模糊条件以及方向,场景文本检测成为一个非常具有挑战性的工作。在深度学习之前,传统的人工设计的特征以及传统的特征分类器性能很差。得益于深度学习的发展,近几年场景文本检测性能已经提高了很多。然而,文本检测研究的关注点已经从水平到多方向以及更具挑战的弯曲和任意形状的场景文本。因此本论文关注任意形状的场景文本检测。
本文,我们用自适应文本区域表示提出了一种任意形状的文本检测方法。给一个输入图像,首先用一个Text-RPN获取文本候选框输入的CNN特征图这一步也被获取。然后CNN特征图经过ROI池化得到文本候选特征用一个改善网络来修正改善候选框。在此有三个分支包括文本/非文本分类器,边界框改善和存在于改善网络中的基于自适应文本区域表示的RNN。在RNN中,每一步都预测一对边界点直到预测停止标签。通过这种方式,任意形状的文本区域通过自适应数目的边界点被表示出来。该方法不仅能处理多方向而且能处理任意方向文本包括弯曲形状文本。在5个数据集上都达到了state of the art 的性能。
相关工作
在深度学习方法之前,传统的滑窗以及连接组件(CC)方法作为最具有前景的机器学习工具被广泛使用。滑动窗口方法(27,32)在一个输入图像上移动多尺度窗口分类当前的块是文本还是非文本。CC方法尤其是MSER(26,30),通过提取CCs得到文本候选,然后候选的CCS被分类为文本以及非文本。这些方法经常采用自下而上的策略而且经常需要几个步骤(字符检测,文本线构造以及文本线分类)来检测文本,每一个步骤都可能导致误分类,这些传统文本检测的方法性能非常差。
近几年,基于深度学习的场景文本检测方法已成为主流。这些方法大致分为三类,包括边界框回归算法,语义分割算法以及相结合的方法。边界框回归的方法(5,8,11,12,13,16)是受SSD以及Faster R-CNN相关方法的启发,把文本当成一种物体直接回归边界框作为检测结果。语义分割的方法(3,19,33)试图把文本从背景区域中分割开来,通过一个额外的步骤得到最终的边界框。结合的方法是使用类似Mask-RCNN,将语义分割以及边界框回归相结合得到更好的性能。但由于更多的步骤,它的处理时间增加了。在这三种方法里,得益于物体检测方法的发展边界框回归的方法是最流行的。
对于边界框回归方法又可以分为一阶段以及两阶段方法。一阶段方法包括DDR(5),TextBox(12),TextBoxes++(11),DMPNet(16),SegLink(24) 以及EAST(34)。这些方法直接一步回归文本边界框。两阶段方法包括R2CNN(8),RRD(13),RRPN(22),IncepText(28)以及FEN(31)。这些方法由候选框生成以及修正改善候选框两部分组成。两阶段算法通常比一阶段算法具有更好的性能。因此本文用了两阶段检测算法。
然而大多数提出的场景文本检测算法只能处理水平或多方向文本,像检测弯曲等任意形状文本目前而言更受关注。在CTD(17),固定14个点的多边形被用来表示文本区域。同时,为了准确检测曲线文本,提出了反复横向和纵向偏移连接(TLOC)。虽然固定14个点的多边形对于大多数文本区域是足够的,但对于长的弯曲文本来说是不足够的。除此之外,14个点对于水平以及多方向文本是太多了,对于这些文本区域来说4个点是足够了。在TextSnake,一个文本实例被描述为一系列重叠的圆盘所覆盖的区域,每一个圆盘有自己的半径和方向。圆盘是通过FCN获得的。而且,Mask TextSpoter 是受Mask R-CNN启发,通过语义分割可以操作不规则文本实例的形状。虽然TextSnake和Mask TextSpotter都能处理任意形状的文本,但需要像素级别的预测,这增加了很大的计算量。
考虑到固定数目的多边形是不适合表示不同形状的文本区域。一个自适应的表示方法,即用不同数目的点来表示不同形状的文本。同时,一个RNN用来学习每个文本区域的自适应表示,文本区域直接被标注而且像素级别的语义分割是不需要的。
方法
图1展示了所提出方法的流程图,这是一个两阶段的检测方法。它包含两个步骤:文本候选框以及候选框改善。在文本候选框阶段,一个Text-RPN是被用来生成输入图片文本候选框,同时CNN特征图在此阶段获得。文本候选框被修正以及改善通过一个改善网络。在这一步骤,包含文本与非文本分类,边界框回归以及自适应文本区域表示的RNN。最终带有自适应数目点的多边形将文本区域包围起来,作为最终检测结果.

自适应文本区域表示
场景文本检测用多边形来检测文本区域,一般用两个点来表示水平方向的文字,用4个点来表示多方向文字.CTW1500 用14个点来表示弯曲文本.然而对于一些复杂的场景,像弯曲长文本即使是14个点也不能很好的表示,而对于水平或多方向小于14个点是足够的,因此用14个点表示它们是浪费的.
因此合理的想到用自适应数目点的多边形来表示文本区域.我们很容易想到文本区域的边界顶点可以用作区域表示.如图2a,这类似于一般物体检测.然而这些点并不是排列在一个方向,很难学习到表示.考虑到文本区域通常近似对称上下边界.如图3所示,使用两个点的成对点,文本区域表示的边界可能更适合.从文本区域的一端到另一端更容易学到成对的边界点.如图2(b)所示.通过这种方式不同的文本区域可以用不同数目的点精确的表示.而且,据我们所知,我们是第一次用自适应数目的成对的点来表示文本区域.


文本候选框
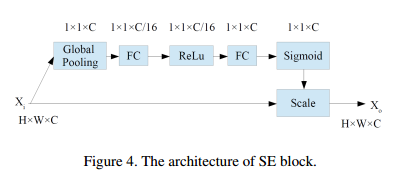
当给出一个输入图像后,第一步首先是得到文本候选框.Text-RPN生成文本区域候选框.该模块的RPN类似于Faster R-CNN,除了网络骨架以及anchor大小不同之外.本论文所提方法骨架网络是SE-VGG16如表1所示,该骨架是通过添加Squeezeand-Excitation (SE) 到 VGG16,如图4所示,SE模块自适应重新校准通道,在通道之间通过明确建模相互依赖性的特征响应,这可以产生显著的性能改进。由于场景文本经常有不同的尺寸,为覆盖更多的文本,anchor 尺寸是被设置为(32,64,128,256,512),同时aspect ratios设置为(0.5,1,2)。

候选框修正
文本候选框生成后,下一步就是要进行调整与修正。正如图1所示,一个修正网络是用来改善候选框的。这包含了几个分支:文本与非文本的分类,包围框的回归以及自适应文本区域表示的RNN网络。文本分类与包围框回归与两阶段检测方法类似,然而最后一个分支被提出为了任意形状的文本表示。
对于提出的分支,输入的是每个文本候选框的特征,这些特征是ROI池化 SE-VGG16生成的特征图。这个分支输出的目标是每个文本区域的自适应边界点数目。因为不同文本区域的文本长度是不同的,所以用RNN来预测这些点是合理的。因此LSTM(RNN的一种变体)是被用在这里,它普遍用于处理序列学习问题,诸如机器翻译,语音识别,图像字幕以及文本识别。
虽然提出成对的边界点被用来文本区域表示,却有不同的方式来获取成对的点。简单的,我们可以想象用两个成对的点的坐标来表示。这种方式,成对点的坐标是目标回归得到的如图5所示。然而,成对的点可以用不同的方式来表示,比如用两个点中心点坐标,以及距离和角度。然而,角度在一些特殊情况下是不稳定的,比如,在空间上90度与负90度是相似的,但它们的角度是非常不同的,这使得网路难以学习角度信息。除此之外,方向可以被表示为sin和cos,这是可以稳定预测的,然而需要更多的参数。因此两个点的坐标是被用来本方法的目标回归。
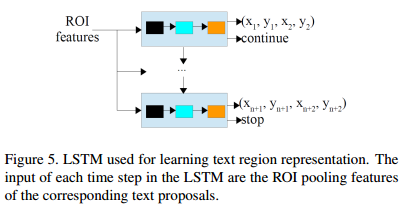
LSTM输入的特征是相同的,即ROI 池化后的特征。每一步的输出是文本区域成对点的坐标。同时,自适应数目的点被用来不同的文本区域,当预测网络停止的时候,一个停止标签是需要的。因为停止标签预测是一个分类问题而坐标预测是一个回归问题。把它们放在同一个分支是不适合的。因此,LSTM的每一步有两个分支,一个是点坐标回归,一个是停止标签预测。每一步都会对文本区域的成对的边界点以及停止还是继续的标签做预测。如果标签是继续,那么另外一对点的坐标在下一步中被预测,否则的话,预测停止而且文本区域是被之前预测的点所表示。通过这种方式,输入图像的文本区域能以成对结点的方式被不同的多边形所检测。
NMS后处理方法也被应用到本文方法中,基于矩形框的NMS当处理多边形框时是不稳定的,因此多边形的NMS是被运用的。NMS之后,剩下的文本区域作为检测结果的输出。
训练目标
Text-RPN是类似于Faster R-CNN的 RPN,它的训练损失计算方式也是类似的。因此,这部分我们仅仅关注改善网络的损失函数。每个候选框的损失定义为文本/非文本分类损失,边界框回归损失,边界点回归损失以及停止/继续的分类损失。每个候选框的多任务损失函数被定义为:

λ1,λ2,λ3是平衡参数,在本文方法中设置为1。
对于文本/非文本分类损失,t是类别标签的下表,文本被标记为1,背景被标记为0。参数p(p0,p1)是文本与背景的概率。Lcls(p; t) = − log pt 是真正类别t的损失。
对于回归框损失,v = (vx; vy; vw; vh)表示一个真正的包围框的中心点以及它的宽高。v∗ = (vx∗; vy∗; vw∗ ; vh∗)是每个候选框的预测。
对于边界点回归损失,u=(ux1; uy1; : : : ; uxn; uyn)是边界点的真实坐标,u∗ = (u∗ x1; u∗ y1; : : : ; u∗ xn; u∗ yn) 是预测坐标。为了保证学到的点对不同尺度的文本是适合的,学习策略也应该被处理保证尺度不变。于是参数被处理为以下的形式:
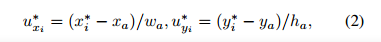
x∗i 和 y∗i 表示了边界点的坐标,xa和ya代表了对应文本候选框中心点的坐标,wa和ha分别表示了候选框的宽和高。
Lreg对应的计算方式如下:

对于停止/继续分类标签损失是一个二分类,它的损失是相似于文本/非文本分类损失。
实验
Benchmarks
本文方法在5个数据集上进行了评测:
- CTW1500: 该数据集1000张训练集,500张测试集,包含了多方向,弯曲文本以及不规则形状文本,文本区域以句子水平标注了14个点。
- TotalText : 该数据集有1255张训练集,300张测试集。超过3种不同的文本方向:水平,多方向,弯曲。图像中的文本以单词级别被标注,标注点的数目自适应(不是固定的数目)。
- ICDAR2013: 229训练集,223测试集,标注是以单词级别的2个点来包围水平框。
- ICDAR 2015: 它关注于自然场景下的文本阅读理解竞赛,包含1000张训练集和500张测试集。以单词级别的4个点来标注倾斜的文本框。
- MSRA-TD500:该数据集包含300张训练集以及200张测试集,它包含了中文和英文的任意方向文本。
实验细节
我们的自然场景文本检测工作是用VGG16的预训练模型来初始化。在5个数据集上测试,训练时,用各自的数据集进行数据增强,所有的模型被训练10×10^4次迭代。 学习率从10^-3开始, 然后当在2×10^4, 6×10^4, 8×10^4的时候分别乘以0.1。我们用0.0005的权重衰减以及0.9的动量。我们用多尺度训练策略,设置训练图片的短边为{400,600,720,1000,1200},同时维持长边在2000.
自适应文本区域表示可以可以处理不同数目的点。ICDAR13,15以及MSRA-TD500是矩形框的标注很容易转换成成对的点。然而对于 CTW1500以及TotalText数据集,需要一些操作将真实的标注转换成我们需要的。
CTW1500文本区域有14个点的标注,它需要转换成自适应成对的点。首先14个点被分成7对,然后计算每个点的交叉角度,它是当前点与临近两个点的角度。对于每个点对,角度取小的那一个。接下来,点对根据降序排列分类,我们尝试按顺序移除每一个点对。移除操作之后的多边形区域相对原来的区域大于0.93,此点对可以被移除。否则的话,操作停止,剩下的点被用来训练文本区域表示。
TotalText中的文本区域标签是自适应数目的点,但这些点不是成对的点,对于偶数目的点,是容易处理为成对的点。对于奇数数目的点,先找到开始的两个点和结束的两个点,剩余的点是根据与开始点的距离进行匹配。
所提方法的结果是在一个训练模型的单尺度测试结果。因为测试图像尺度对检测结果有较深的影响,像FOTS对不同的数据集用不同的尺度,我们也在不同的数据集上用不同的测试尺度,以获得最好的性能。在我们的实验中,ICDAR2013用9601400,ICDAR2015用12002000,剩余的其它数据用全用720*1280. 所提的方法是用Caffe来实现,并在P40GPU上来实现。
网络学习
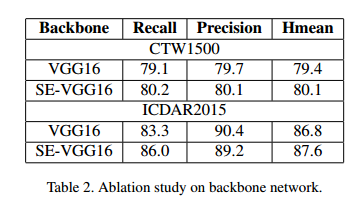
所提方法的基本骨架是SE-VGG16,因为VGG16经常被其它最先进的方法所使用。为了验证基本骨架的有效性,我们使用SE-VGG16和VGG16在数据集CTW1500和ICDAR2015上进行对比试验,如表2所示,结果表明SE-VGG16是比VGG16更好。
同时,本文提出了一种任意文本形状的自适应区域表示方法,为了验证检测的有效性,我们在CTW1500增加了文本区域表示的网络学习。作为对比,我们用固定的14个点来作为回归目标。是验证结果如下:
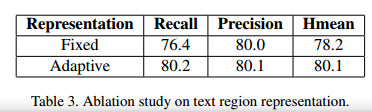
与其它方法对比
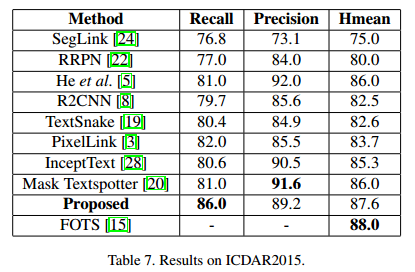
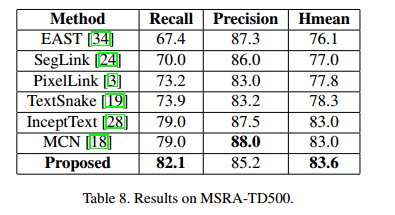
为了展示所提方法的性能,我们在几个数据集上进行了测试。
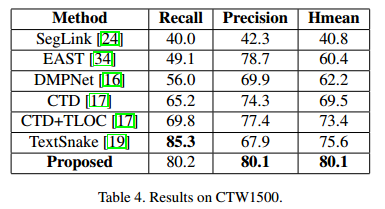
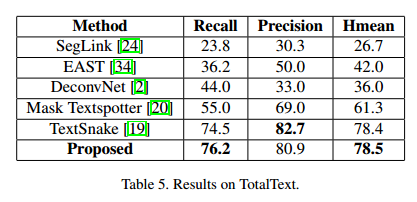
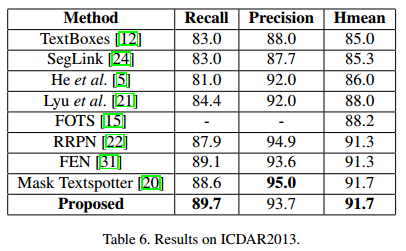
速度



结论
在本论文中,我们提出了一种自适应文本区域表示的任意形状的文本检测模型。用Text-RPN提取候选框之后,每一个文本区域用RNN验证改善来预测自适应数目的边界点。实验在5个数据集上不仅能检测水平多方向而且能很好的检测任意形状的场景文本。特别在CTW1500和MSRA-TD500数据集上,分别代表了弯曲文本和多方向文本。
接下来,所提方法可以在这几个方面进行改善。
- 任意形状的文本可以用角点来检测,对训练图像来说更容易标注。
- 为了完成文本识别的任务,需要考虑端到端的场景文本检测识别。