文章目录
效果图
xlsxwriter
from xlsxwriter.workbook import Workbook
import re
# 创建Excel对象
workbook = Workbook('a.xlsx')
worksheet = workbook.add_worksheet()
color = workbook.add_format({'color': 'red', 'bold': True})
# 日期高亮
rc = re.compile('([0-9年月日]{2,})')
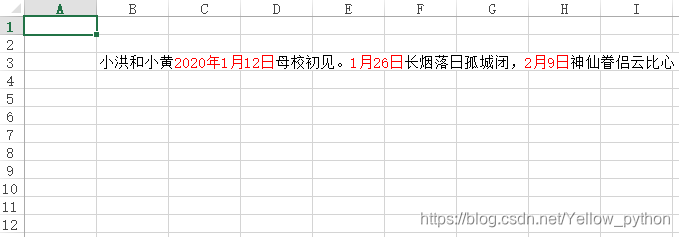
sentence = '小洪和小黄2020年1月12日母校初见。1月26日长烟落日孤城闭,2月9日神仙眷侣云比心'
format_ls = rc.split(sentence)
for i in range(len(format_ls)-1, -1, -1):
if rc.fullmatch(format_ls[i]):
format_ls.insert(i, color) # Prefix the word with the format
print(format_ls)
# 写入单元格
row, col = 2, 1
worksheet.write_rich_string(row, col, *format_ls)
workbook.close()
中间产物打印
['小洪和小黄', <xlsxwriter.format.Format object at 0x00000225C39CE588>, '2020年1月12日', '母校初见。', <xlsxwriter.format.Format object at 0x00000225C39CE588>, '1月26日', '长烟落日孤城闭,', <xlsxwriter.format.Format object at 0x00000225C39CE588>, '2月9日', '神仙眷侣云比心']
报错场景
from xlsxwriter.workbook import Workbook
# 创建Excel对象
workbook = Workbook('a.xlsx')
worksheet = workbook.add_worksheet()
color = workbook.add_format({'color': 'red'})
col = 1
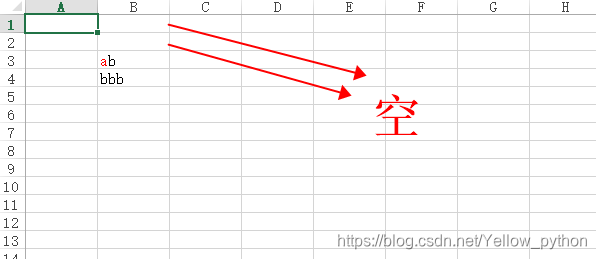
for row, string_parts in enumerate([
[color, 'a', ''], # Excel doesn't allow empty strings in rich strings.
[color, 'a'], # You must specify more then 2 format/fragments for rich strings.
[color, 'a', 'b'], # 不报错
['b', 'b', 'b'], # 不报错
]):
print(string_parts)
worksheet.write_rich_string(row, col, *string_parts)
workbook.close()
总结
- 不允许空字符串
- format/fragments数量≥3
xlsxwriter其它接口
from jieba import tokenize
from xlsxwriter.workbook import Workbook
# 创建Excel对象
workbook = Workbook(filename='phone.xlsx')
worksheet = workbook.add_worksheet()
color = workbook.add_format({'bold': True, 'color': 'red'})
def ner(text):
for clause in text.split(','): # 切句
for word, head, tail in tokenize(clause): # 分词+位置
if word in {'小米', '苹果'}: # NER
yield (
[i for i in(clause[:head], color, word, clause[tail:])if i],
word,
)
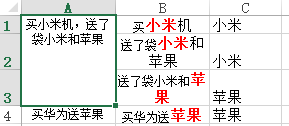
texts = ['买小米机,送了袋小米和苹果', '诺基亚', '买华为送苹果']
row = 0
for e, t in enumerate(texts):
first_row = row
for w, c in ner(t):
worksheet.write_rich_string(row, 1, *w)
worksheet.write_string(row, 2, c)
row += 1
print(first_row, row)
if row == first_row+1:
worksheet.write_string(row-1, 0, t)
elif row > first_row+1: # 合并单元格
worksheet.merge_range(first_row, first_col=0, last_row=row-1, last_col=0, data=t)
# 列宽
linefeed = workbook.add_format({
'align': 'center', # 居中对齐(align: vi. 排列)
'valign': 'top', # 上对齐
'text_wrap': 1, # 换行
'font_size': 9, # 字体大小
# 'bg_color': 'gray', # 背景色
})
worksheet.set_column(first_col=0, last_col=1, width=11, cell_format=linefeed)
workbook.close()