一、深度学习
1、简介

 不同的连接方法
不同的连接方法
2、全连接前馈网络
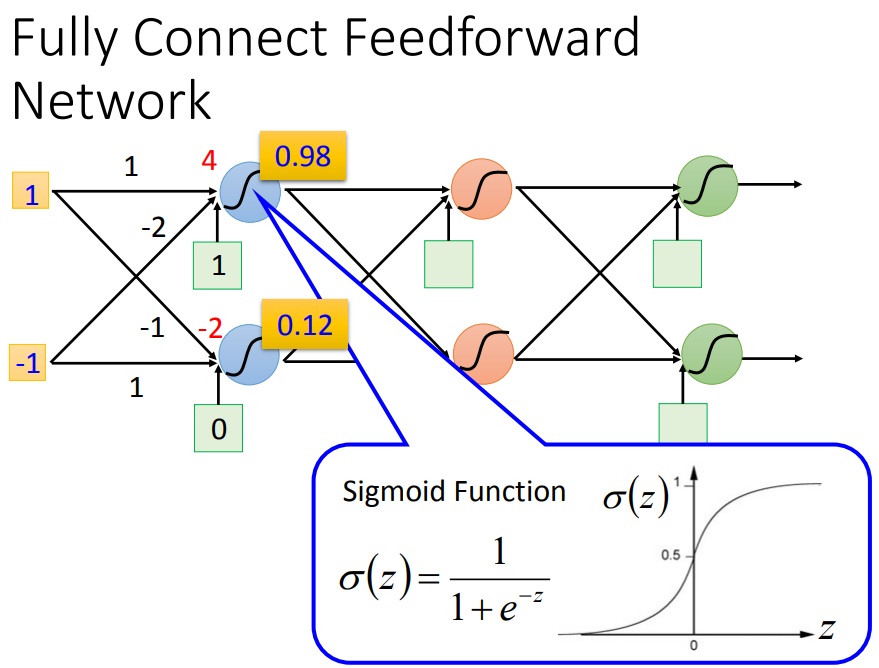
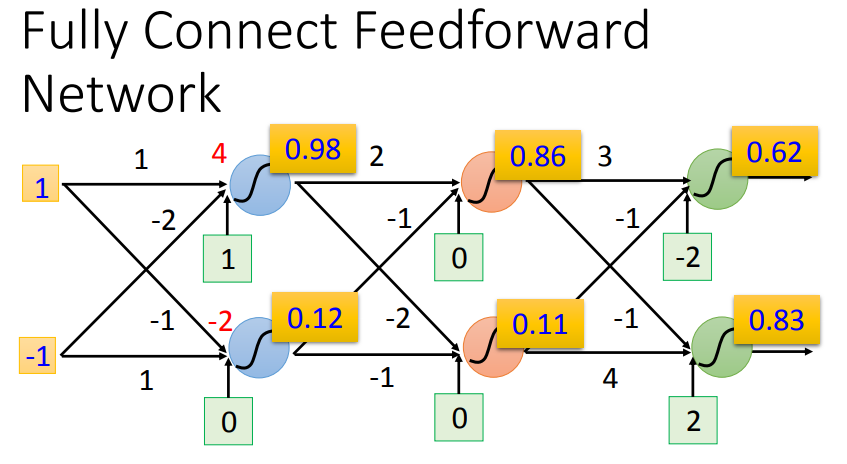
1*1+(-1)*(-2)+1=4--->sigmoid--->0.98

相当于一个函数,输入一个向量,输出一个向量。如果w和b未知,就是一个function set。
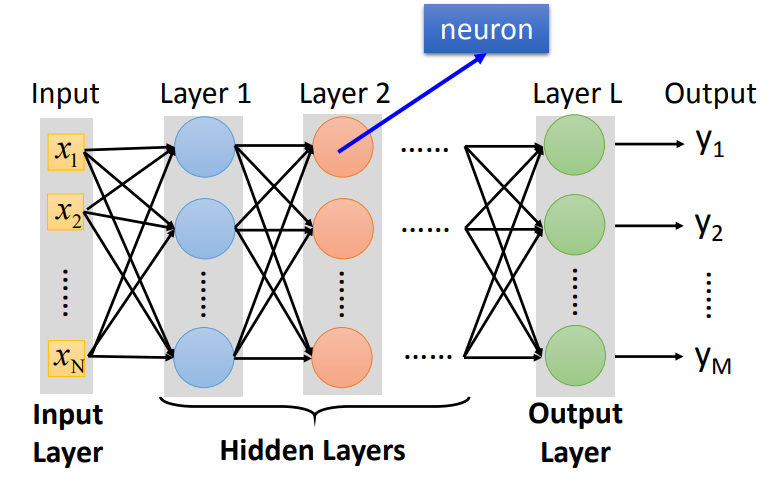
全连接、前馈。输入层只有data,输出层是最后一层,中间都称为隐藏层。现在基于神经网络的方法都是深度学习的方法。
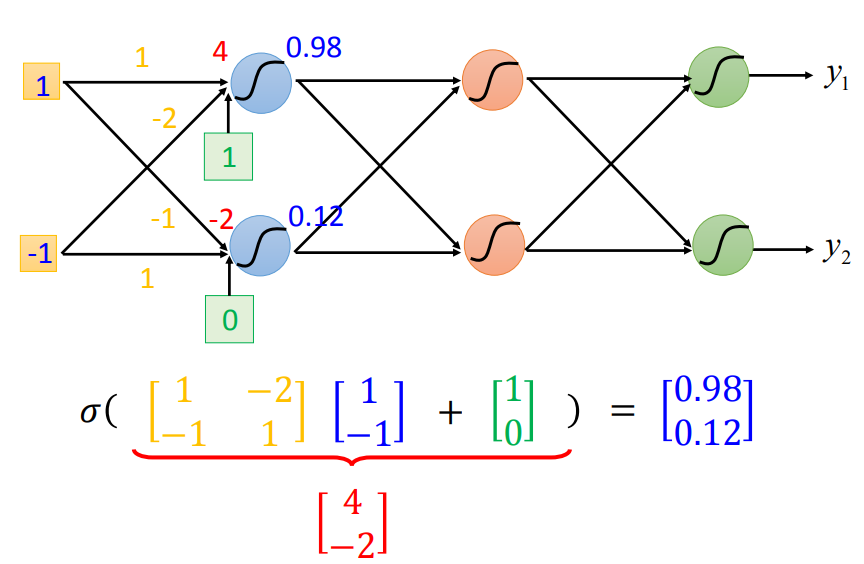


一连串的向量乘以矩阵再加上向量,写成这样的好处是可以进行GPU加速(GPU做矩阵运算更快)
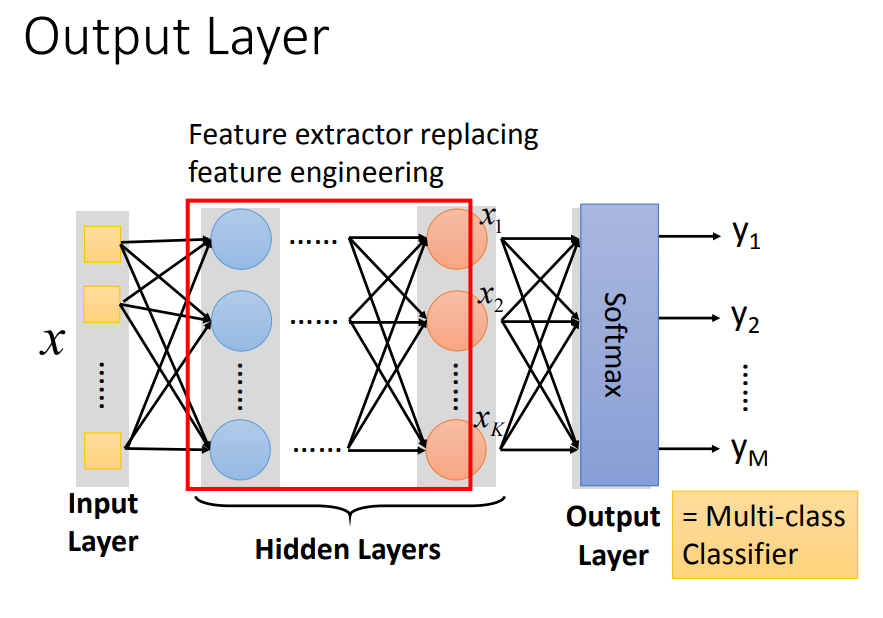
多分类器将 很多次特征抽取后的比较好的feature 分类。由于最后看成多分类器,最后一个layer也经常加上softmax。
3、例子
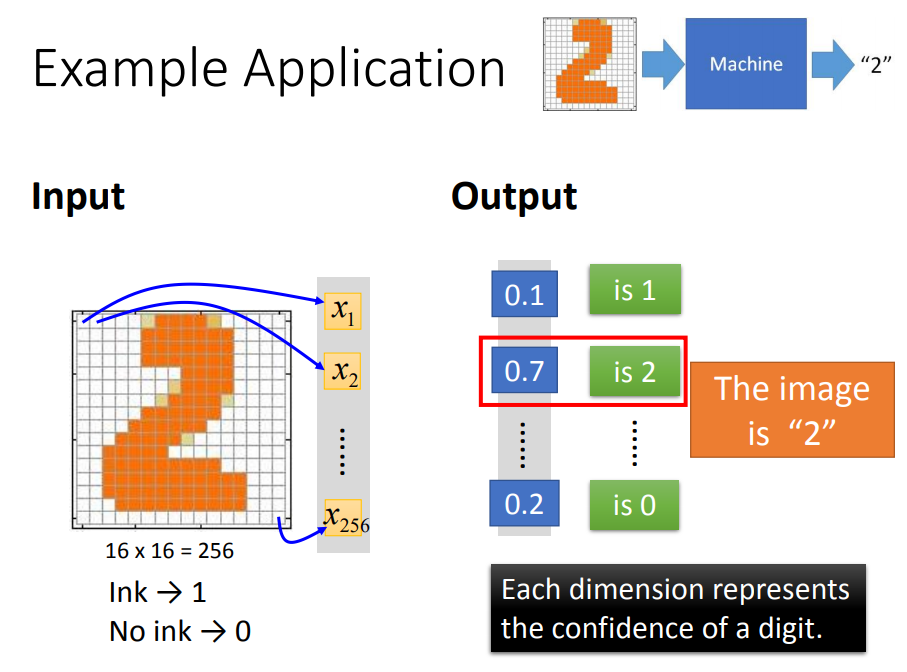
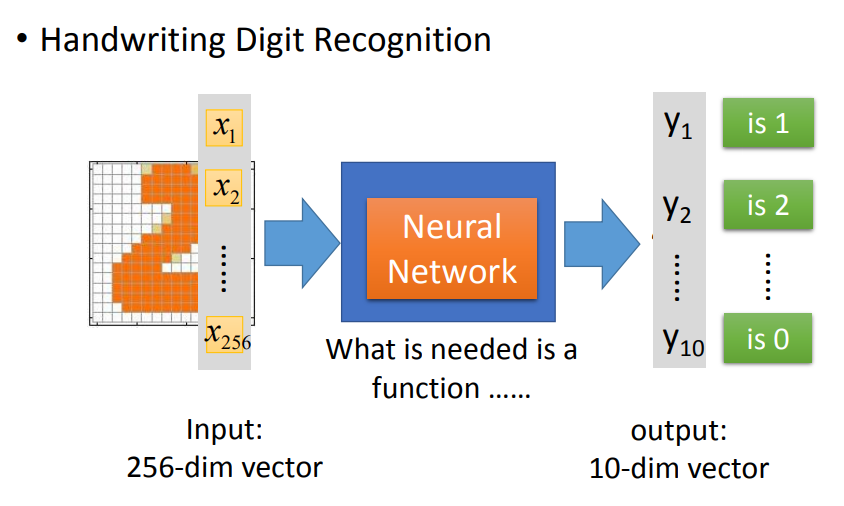
输入256维,输出10维。
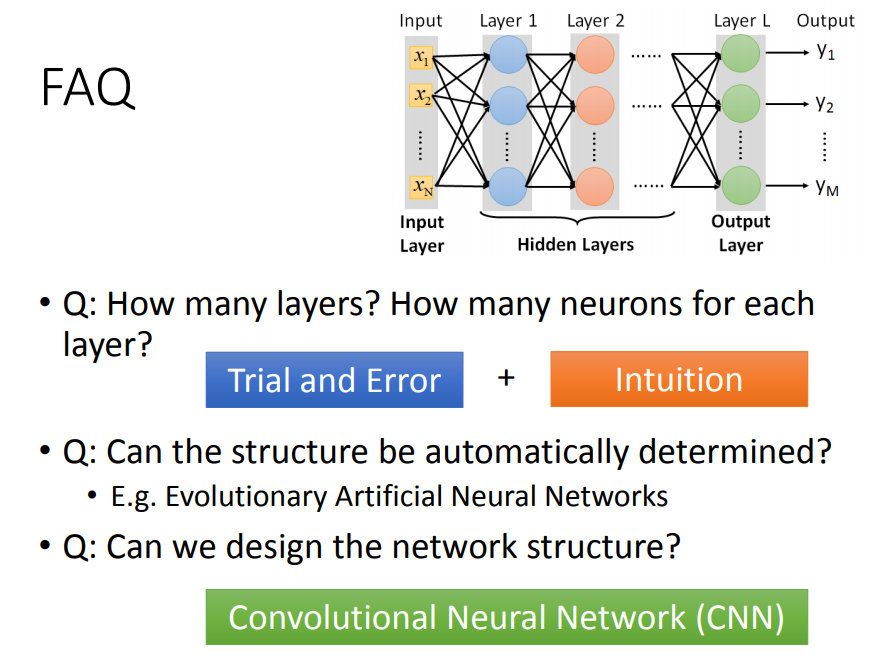
有了深度学习,不需要在影像辨识或是自然语言处理时来做特征抽取,但是麻烦变成了如何设计神经网络。
不过对于影像辨识或是自然语言处理问题,设计网络结构可能比特征工程更容易,不如让机器自己去找出好的特征。
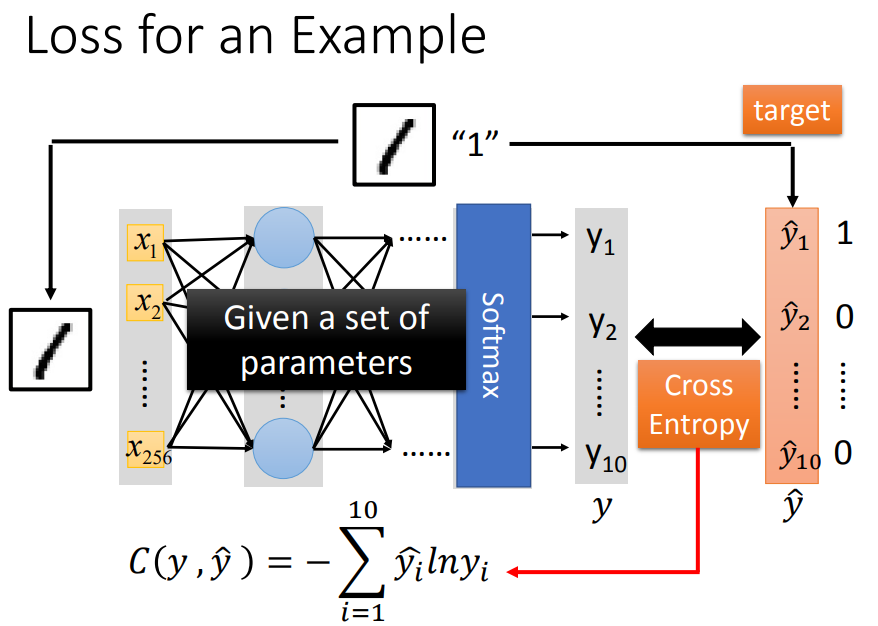
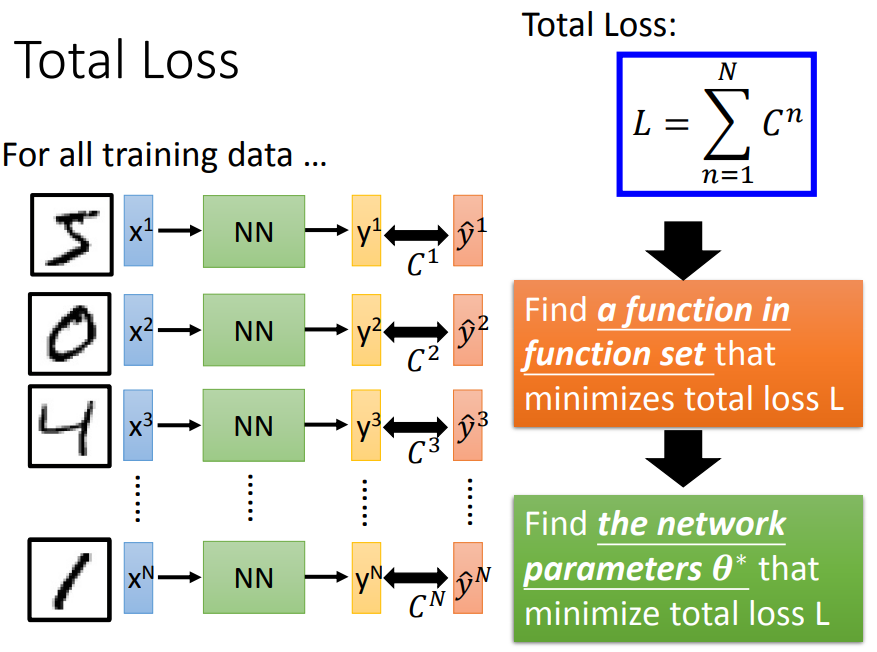
计算交叉熵损失,通过调整参数,使得交叉熵越小越好。所有training data的cross entropy相加就是损失函数L,找一组网络参数最小化L。
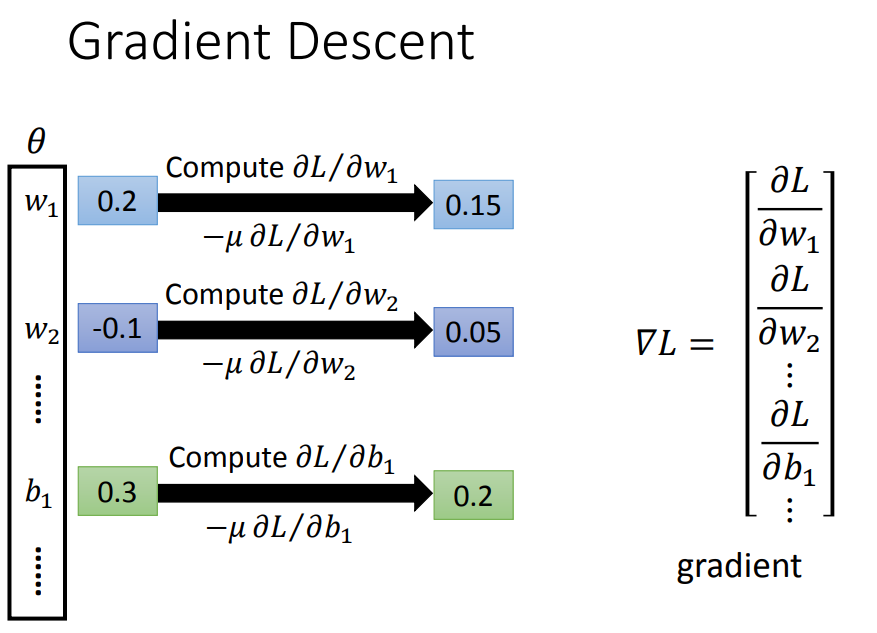

同样用梯度下降来优化参数。

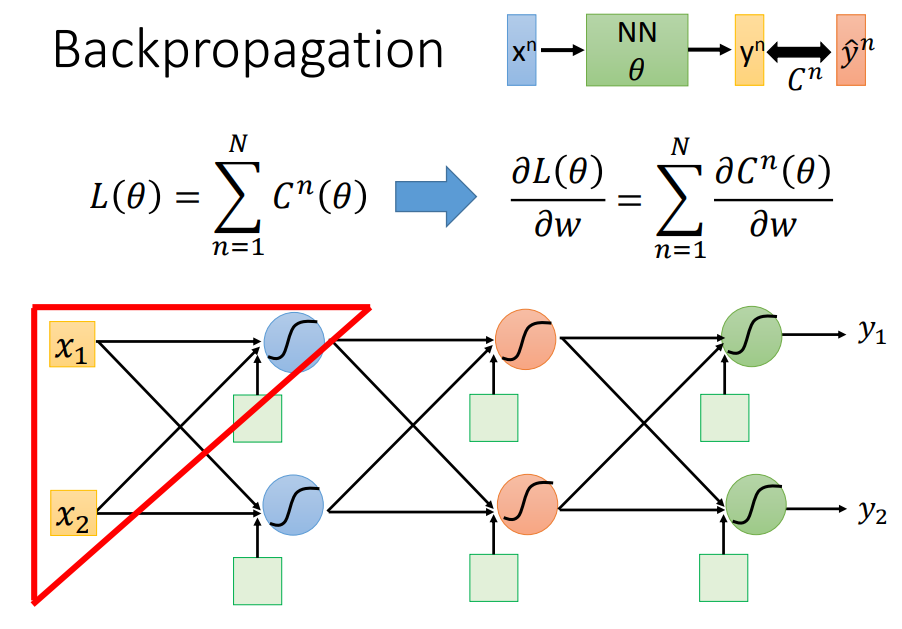
4、反向传播

对于高维的vector,为了有效的计算梯度,使用反向传播。反向传播实际就是使用链式法则:


下面的推导只考虑一笔data来计算,最后求和即可。
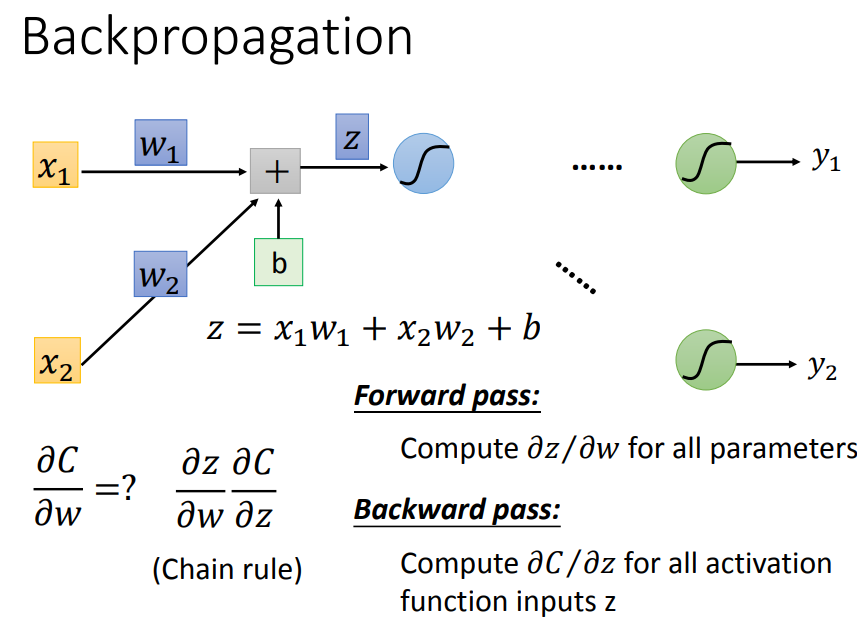
根据链式法则,C对w求偏微分,可以拆成z对w和C对z。下面分别看这两部分:
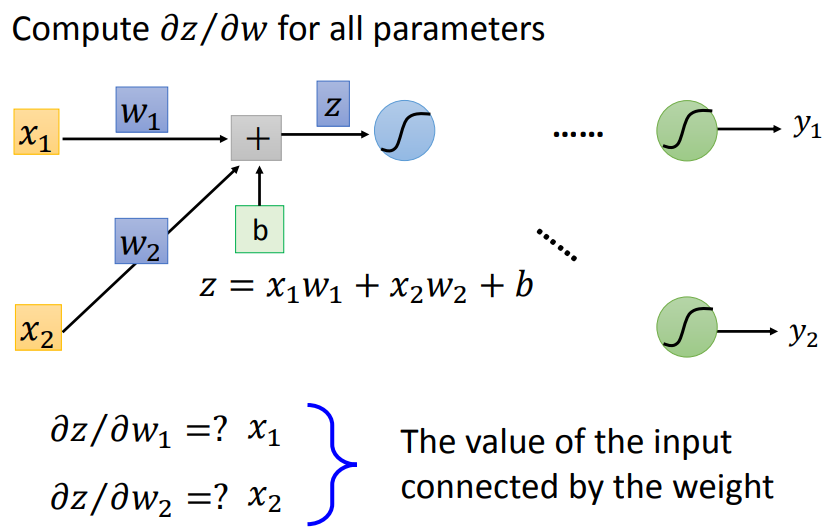
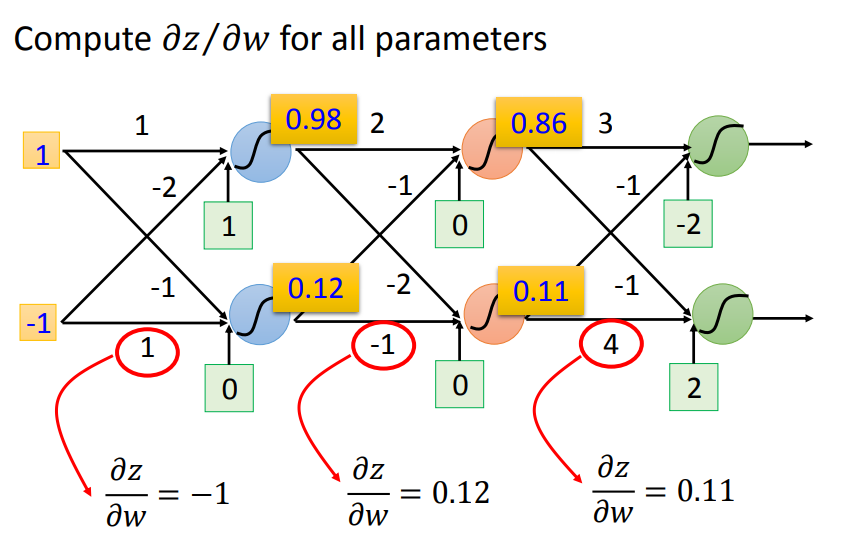
对于forward pass:w前面接的是什么,微分以后就是什么。
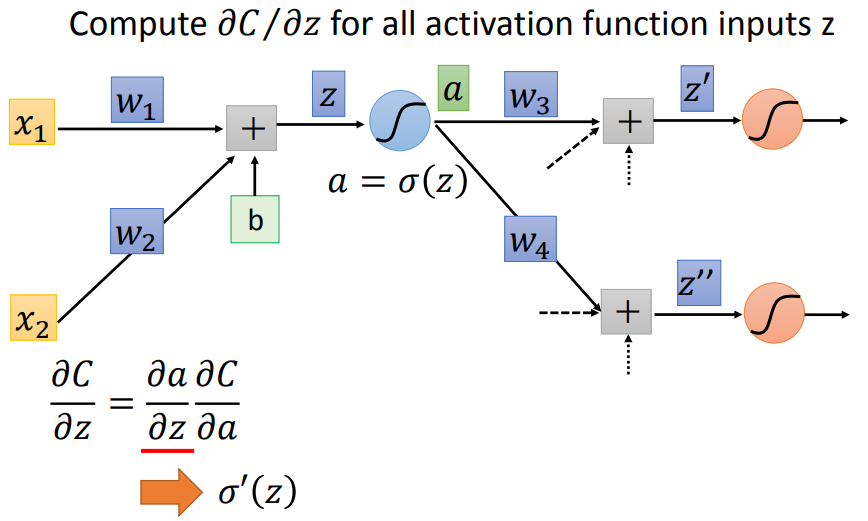
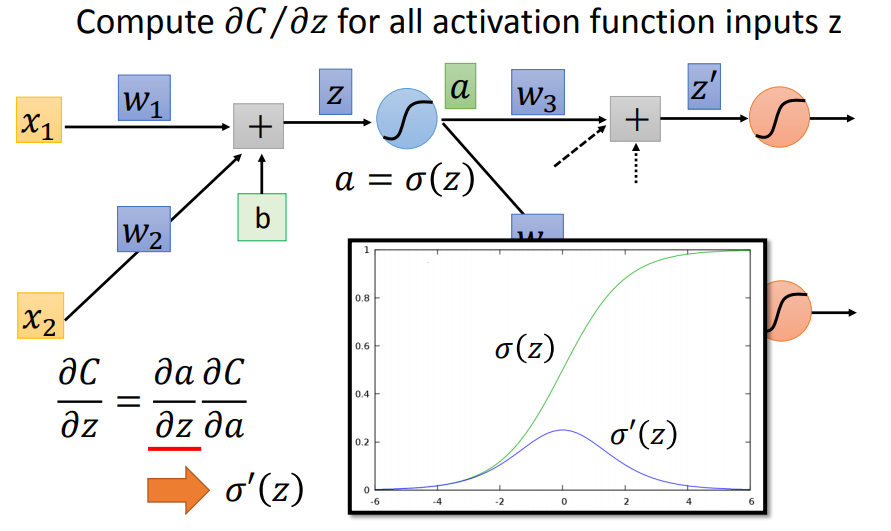
对于backward pass,同样链式法则,sigmoid函数的部分可以直接算
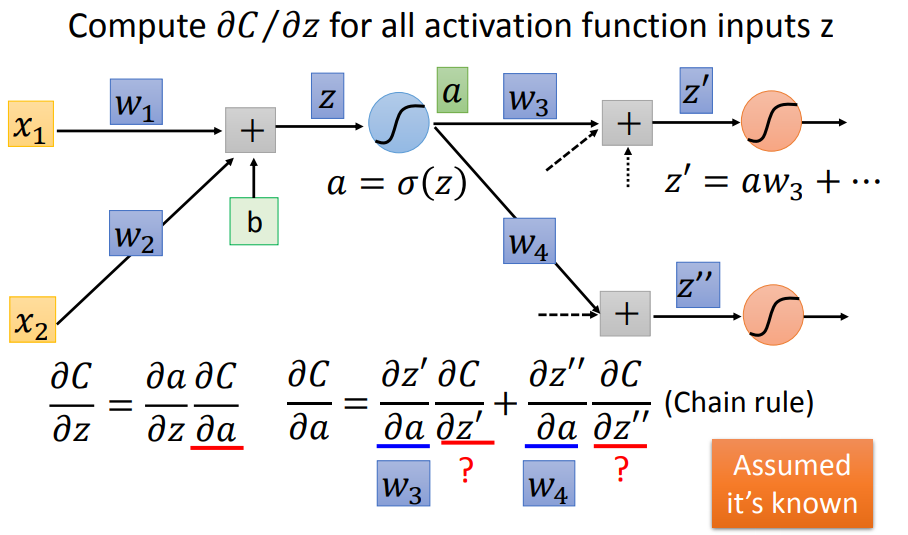

后一部分同样使用链式法则,假设下一层只有两个神经元,我们得到上图这样的式子。
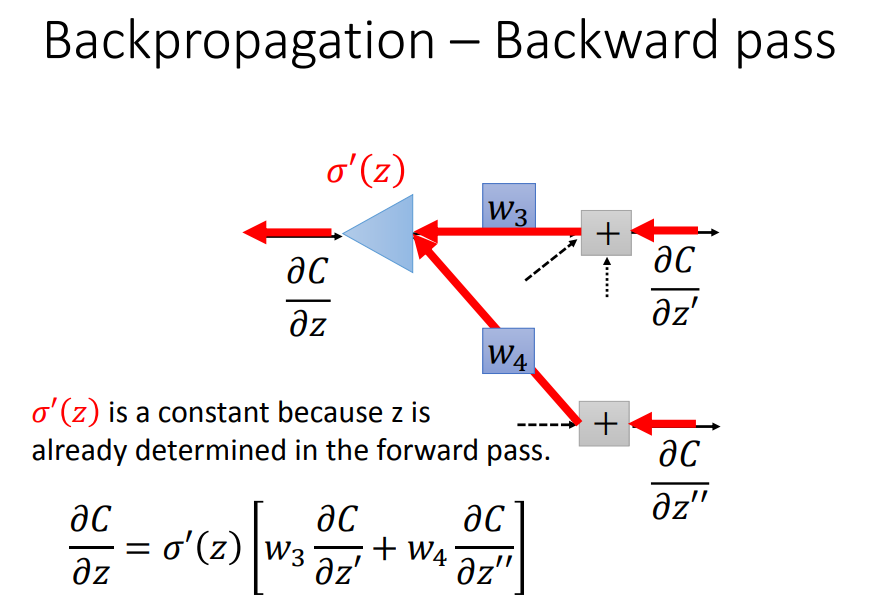
这个式子可以用上图类似神经网络的样子画出来,σ'(z)可以看做一个常数(直接乘上一个常数画成三角形)。

① 最后剩下的两项,如果是输出层,可以直接算出结果,如上例中y1对z'的偏导是sigmoid函数的导数,C对y1的偏导是交叉熵求导。
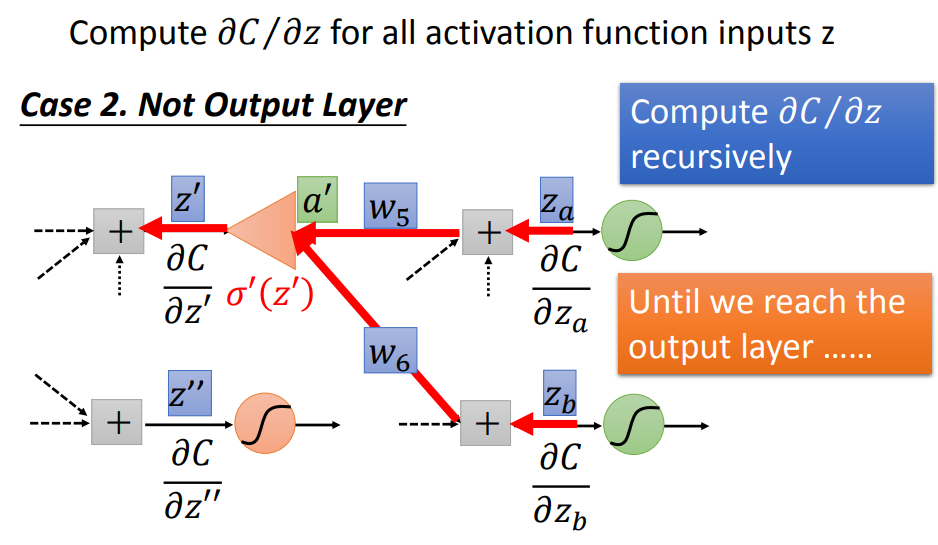
② 如果不是输出层,可以按照一模一样的式子以此类推,直到输出层。

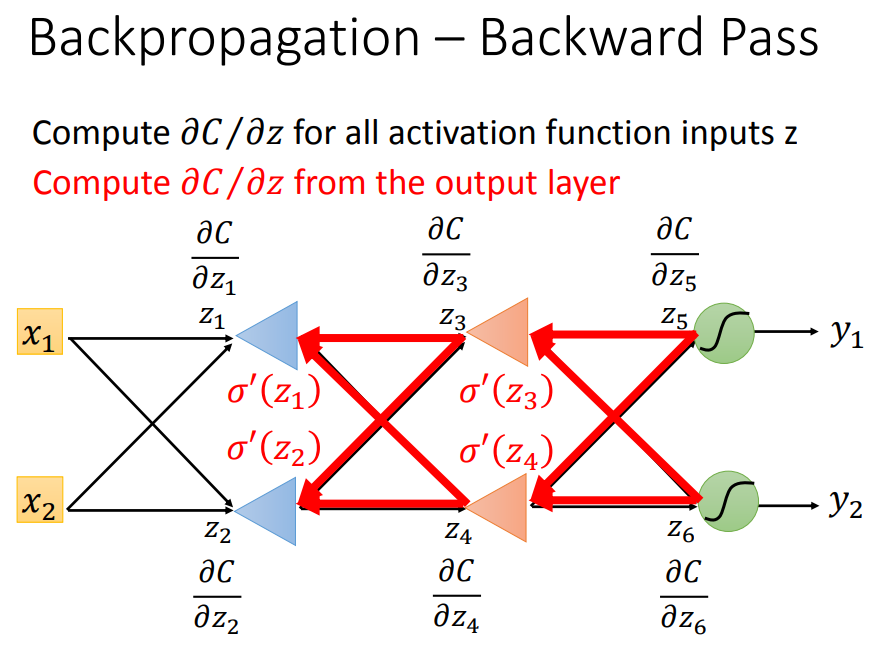
如上,如果要算backward pass,从z5,z6对C的偏微分开始求,即从输出层开始计算,接下来可以算z3和z4,再算z1和z2。
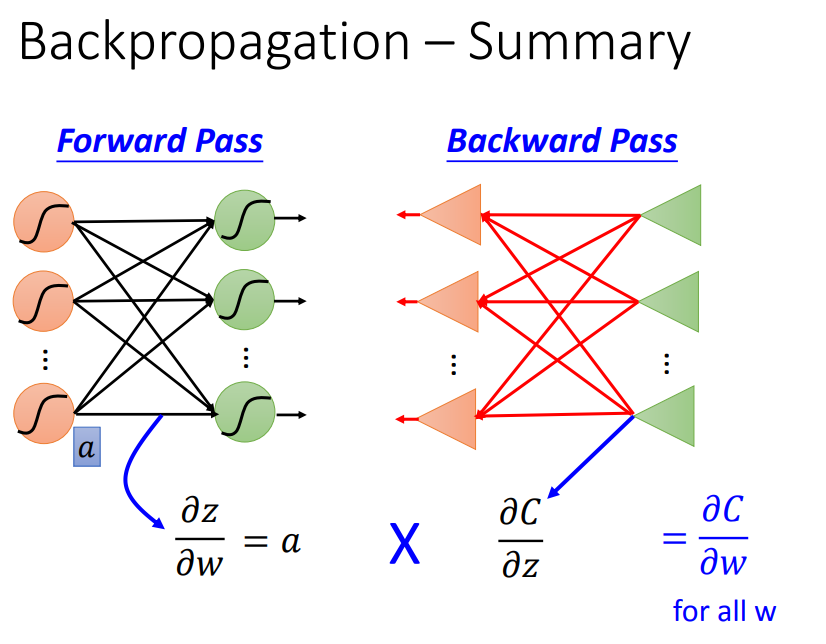
综上,顺推法和逆推法结合,这样就可以更高效地计算出偏微分。
5、