一、ArrayList数据结构
ArrayList的底层数据结构是一个类型为Object的数组。
数组的初始长度与创建ArrayList对象时使用的构造方法有关
注:数组“elementData”是用来存储数据、操作数据的数组
“DEFAULTCAPACITY_EMPTY_ELEMENTDATA”是默认的空数组
- 传入的初始长度

- 使用无参构造函数,创建长度为0的数组,在加入第一个数据时会将数组扩容到默认值10
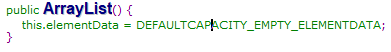
- 使用传相同数据类型的数组的构造函数,长度为传参数组的长度

经测试,如果要存100万数据,需要扩容28次,数据量越大,扩容次数越多,每一次的扩容代表着创建新数组对象,复制原有数据。
如果数据很大,那么有必要为集合初始化一个默认大小,防止多次扩容,但如果数据增长很慢,那么就会浪费内存了,具体怎么做,还是要看实际应用场景。这里只做初步分析。
二、ArrayList的线程安全性
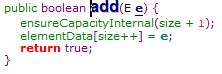
由于ArrayList每次增加数据的时候需要通过add()方法,而add方法的实现是通过size计数,将数据储存在size索引下的数组里,然后再将size加一。
具体举例说明:在单线程运行的情况下,如果Size = 0,添加一个元素后,此元素在位置 0,而且Size=1;而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置0。但是此时 CPU 调度线程A暂停,线程 B 得到运行的机会。线程B也向此ArrayList 添加元素,因为此时 Size 仍然等于 0 (注意哦,我们假设的是添加一个元素是要两个步骤哦,而线程A仅仅完成了步骤1),所以线程B也将元素存放在位置0。然后线程A和线程B都继续运行,都增 加 Size 的值。 那好,现在我们来看看 ArrayList 的情况,元素实际上只有一个,存放在位置 0,而Size却等于 2。这就是“线程不安全”了。
如果非要在多线程的环境下使用ArrayList,就需要保证它的线程安全性,通常有两种解决办法:第一,使用synchronized关键字;第二,可以用Collections类中的静态方法synchronizedList();对ArrayList进行调用即可。
三、ArrayList扩容方式
当使用add()方法是,通过检测插入时size++的值是否大于数组的长度,大于的话通过grow()方法进行数组扩容。grow()方法中的“>>1”是将二进制数字向右移一个单位,即是将数字除2。因此oldCapacity+(oldCapacity>>1)就是扩大了1.5倍,如:原本数组长度为10,进行扩容以后数组长度为10+5=15,扩大了1.5倍。
注:“Integer.MAX_VALUE”是Integer类能取到的最大值0x7fffffff

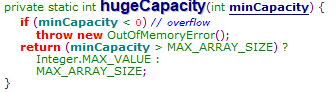
如果扩大两倍后的值大于“Integer.MAX_VALUE - 8”则将扩容数组的长度设置为“Integer.MAX_VALUE”或“Integer.MAX_VALUE-8”。
四、常用方法
图一
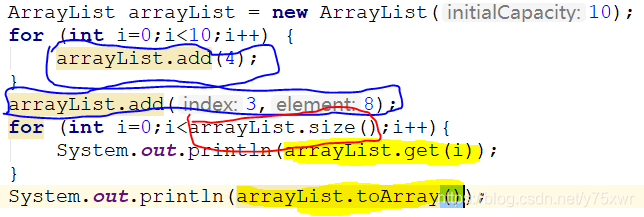

add()增加
代码演示
上图中用蓝笔标识的是add()方法的使用有两种使用方式,一种直接添加数据,一种在指定位置插入数据,会替换掉原先的数据。
源码分析
- 直接在后面添加

先判断size++的值是否超过了数组长度,超过了进行两倍扩容,判断长度以后在size位插入数据。 - 在指定位置插入数据

(1)当index>size时会出现错误“IndexOutOfBoundsException("Index: “+index+”, Size: "+size)”
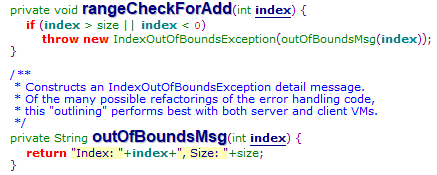
(2)当size++大于数组长度时进行扩容
(3)进行拷贝操作,将index下标后面数据往后移动一个单位
(4)对index下标下的值进行替换
contains()判断是否存在
代码演示
是判断在ArrayList数组中有没有对象与“contains()”括号中相同的对象,有则返回true,没有则返回false。
ArrayList<Course> course = new ArrayList();
// 初始化5个对象
for (int i = 0; i < 5; i++) {
course.add(new Course("course " + i));
}
Course specialCourse = new Course("special course");
course.add(specialCourse);
System.out.println(course);
// 判断一个对象是否在容器中
// 判断标准: 是否是同一个对象,而不是name是否相同
System.out.print("虽然一个新的对象名字也叫 course 1,但是contains的返回是:");
System.out.println(course.contains(new Course("course 1")));
System.out.print("而对specialHero的判断,contains的返回是:");
System.out.println(course.contains(specialCourse));

源码分析
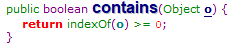

由图可知,当运行contains()是调用indexOf()方法,在indexOf()中循环判断ArrayList中的对象与对比对象进行equals对比,如果对比对象中重写了equals()方法就对比equals()中的比较值,如果没重写就对比对象的地址。
set()替换
源码分析

(1)对index与size进行大小比较,看是否越界
(2)对数组下标为index的值进行覆盖
(3)返回原值
get()获取指定位置的对象
代码演示
看图一中的get()方法的使用,直接在括号中放入要获取的指定位置,将会获得该位置的值。
源码分析
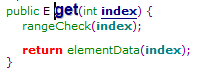
(1)先判断获取的位置是否小于size,如果大于size抛出“IndexOutOfBoundsException("Index: “+index+”, Size: "+size)”
(2)通过下标获取数组中的值
indexOf()获取对象所处的位置
源码分析

根据输入的值,与ArrayList中的对象进行对比,找到了一样的就返回该对象的地址,通过equals方法进行的比较,没重写对比的是对象地址,重写了就对比equals中的东西。
remove()删除
代码演示
有两种实现删除的方式,一种输入下标值进行删除;一种通过对比值进行删除,但是只会删除遇上的第一个相同值。
源码分析

(1)判断index是否越界
(2)获得index后面需要往前移动的个数
(3)对index后面的值往前移动一个位置
(4)将size位设置为null,并且将size-1
(5)返回删除的数值

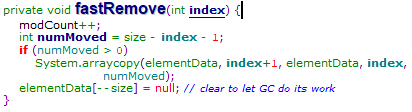
(1)判断输入的值是否为null确定对比的方式
(2)对比找到相同的值的下标
(3)将相同值后面的数据往前移动一个单位
(4)将size位设置为null,并且将size-1
(5)返回ture/false
toArray()转换为数组
代码演示

addAll() 把另一个容器所有对象都加进来
代码演示
注:另一个容器必须是Collection子类。

有两种实现方式,一种是直接在ArrayList最后面加入另一个数组中的全部值,还有一个是在ArrayList指定下标后加另一个数组中的全部值。
源码分析

(1)使用toArray()将容器的值放入Object数组中
(2)获得数组长度
(3)判断加入数组中的之后有没有可能ArrayList中的下标越界,可能就扩容
(4)对数组的值进行拷贝,返回true/false

(1)使用toArray()将容器的值放入Object数组中
(2)获得数组长度
(3)判断加入数组中的之后有没有可能ArrayList中的下标越界,可能就扩容
(4)将index后面的数据移动要插入数据的个数
(4)对数组的值进行拷贝,返回true/false
与vector的对比
Vector的实现其实和ArrayList的底层实现很类似,都是封装了一个Object[],但Vector是一个比较古老的集合,JDK1.0就已经存在,建议不要使用这个集合,Vector与ArrayList的主要区别是:Vector是线程安全的,ArrayList是非线程安全的,但性能上Vector比ArrayList低。
给出以下几点总结:
1、Vector有四个不同的构造函数。 无参构造的容量默认值为10
2、扩充容量的方法ensureCapacityHelper。与ArrayList不同的是,Vector在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当容量不足以容纳当前的元素个数时,就看构造方法中传入的容量增长系数CapacityIncrement是否为0,如果不为0,就设置新的容量为 旧容量 + 容量增长量;如果为0,设置新的容量为旧的容量的2倍,如果设置后的容量还不够,则直接新的容量设置为 旧容量 + 传入参数所需要的容量 而后同样用Arrays.copyof()方法将元素拷贝到新的数组。
3、很多方法都加入了synchronized同步语句,来确保线程安全。
4、Vector在查找给定元素索引值等方法中,源码都将该元素的值分为null和不为null两种情况处理,Vector中允许元素为null
5、其他很多地方与ArrayList实现大同小异,Vector现在已经不再使用。