用法:注意是用英文的逗号",",且之间没有空格。
文件名,[工作表名称,不写则默认当前激活的表],[从第几行开始,不写则默认第二行,因为很多表第一行是title],列名(第一列是要查找的元素,列名可以不连续,比如“ade”)
脚本会自动把要查找的第一列进行大小写变换,去除空格等操作,下面的例子中,第一列的名字有的是大写,有的小写,前后还有空格,脚本会默认它们相同
现有Sheet1,内容如下
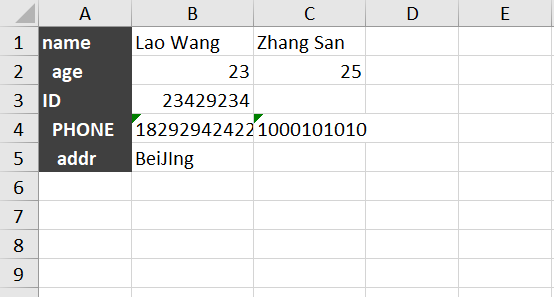
Sheet2内容如下

想把 Sheet1 的 B,C 列的信息复制到 Sheet2 的 B,C列上,执行脚本:
Source fileName,[sheetName],[row],columns:
vlookup.xlsx,Sheet1,1,abc
Target fileName,[sheetName],[row],columns:
vlookup.xlsx,Sheet2,1,abc
{'name': ['Lao Wang', 'Zhang San'], 'age': [23, 25], 'id': [23429234, None], 'phone': ['18292942422', '1000101010'], 'addr': ['BeiJIng', None]}
{'addr': [None, None], 'phone': [None, None], 'id': [None, None], 'age': [None, None], 'name': [None, None]}
Processing...
Done.
然后Sheet2的内容就变成了:
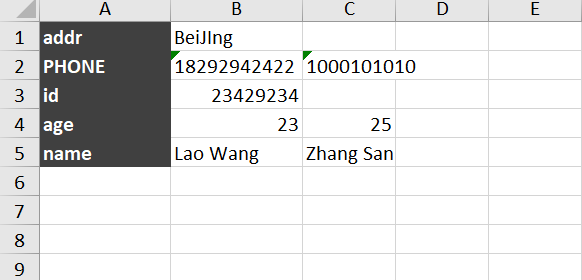
import openpyxl
def read_Excel(path,sheetName,row,*col):
# 默认从第二行开始,因为很多表都有表头
if row == '':
row = 2
else:
row = int(row)
workbook = openpyxl.load_workbook(path)
# 默认打开当前激活的工作表
if sheetName == "":
sheet0 = workbook.active # 获取当前激活的工作表
else:
sheet0 = workbook[sheetName] # 如果制定了工作表,就打开指定的工作表
highest = sheet0.max_row
case_list = {}
# title 所在列,对比的那一列,假设A列
title = col[0]
for i in range(row,highest+1): # 遍历行
value_list = []
if sheet0[title+str(i)].value == None: # 如果A5是空的,pass
pass
else:
v1 = sheet0[title+str(i)].value.lower().strip() # 忽略大小写和前后空格
# 除去 title的其他列
for j in range(1,len(col)):
v2 = sheet0[col[j]+str(i)].value
value_list.append(v2)
case_list[v1] = value_list
print(case_list)
return case_list
def write_Excel(dict,path,sheetName,row,*col):
# 将处理好的数据再次写入excel
if row == "":
row = 2
else:
row = int(row)
workbook = openpyxl.load_workbook(path)
if sheetName == "":
sheet0 = workbook.active # 获取当前激活的工作表
else:
sheet0 = workbook[sheetName]
highest = sheet0.max_row
# case title 所在列
title = col[0]
for i in range(row,highest+1):
if sheet0[title + str(i)].value != None:
v1 = sheet0[title + str(i)].value.lower().strip() # 忽略大小写和前后空格
for key in dict:
if key == v1:
for j in range(1,len(col)):
v2 = sheet0[col[j]+str(i)]
v2.value = dict[key][j-1]
workbook.save(path)
def process(r1,r2):
# 对比处理两次读取的内容,然后更新r2的内容
print('Processing...')
for key in r1:
if key in r2:
length = len(r1[key])
if length > 0:
for i in range(0, len(r1[key])):
# 如果想要不想覆盖原有的数值,可以取消注释,然后删除下面那行
# if r2[key][i] == None:
# r2[key][i] = r1[key][i]
r2[key][i] = r1[key][i]
else:
pass
return r2
def manual():
info1 = input('Read from fileName,[sheetName],[row],columns:\n')
file1,sheetName1,row1,list1 = info1.split(',')
info2 = input('Write into fileName,[sheetName],[row],columns:\n')
file2,sheetName2,row2,list2 = info2.split(',')
r1 = read_Excel(file1,sheetName1,row1,*list1)
r2 = read_Excel(file2,sheetName2,row2,*list2)
r3 = process(r1,r2)
write_Excel(r3,file2,sheetName2,row2,*list2)
print('Done.')
if __name__ == "__main__":
manual()