MySQL知识点汇总之DML语言、数据插入优化、视图
前言
今天有空继续整理了一下MySQL的知识点,接着前几篇博文给大家分享…
DML语言(数据管理语言)
执行条件:
向表中插入数据修改现存数据删除现存数据
插入数据(insert)
语法:(使用insert一次只能插入一条数据)
#方法一:
INSERT INTO 表名(插入数据的列字段,...,...)VALUES(对应插入的值,...,...);
#方法二:
INSERT INTO 表名 VALUES(添加该表所有列字段值);
从上面的语法可以看出,有两种方法进行单条数据的插入,在开发过程中,建议使用第一种带上指定列字段的方式插入值,原因在于:
后期表的结构可能会更改,有可能多一个或者少一个字段,那么使用第二种方式势必就会报错
数据插入优化
我们在实际开发过程中,可能面对的是百万级数据、千万级数据的插入,那么对于运行速度的一个优化是很有必要的,这里我使用存储过程模拟插入了10w条数据,看看插入时间:
create table test_xiaoyang(
id int not null auto_increment primary key,
tname varchar(50)
)
select * from test_xiaoyang;
#插入数据
#创建存储过程
DROP PROCEDURE IF EXISTS my_insert;
CREATE PROCEDURE my_insert()
BEGIN
DECLARE n int DEFAULT 1;
loopname:LOOP
INSERT INTO `test_xiaoyang`(`tname`) VALUES ('测试');
SET n=n+1;
IF n=100000 THEN
LEAVE loopname;
END IF;
END LOOP loopname;
END;
#执行存储过程
CALL my_insert();
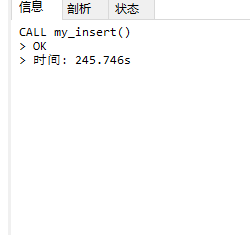
这里可以看到,仅仅插入10w条数据,就用了差不多246s,下面给大家看一下优化方式和过程:
利用引擎的特点进行更改优化:
建表时默认数据库是InnoDB引擎,而InnoDB的一个优点在于提交、回滚、崩溃恢复能力的事务安全能力,而比较适用于在查询、插入数据的引擎的是MyISAM引擎,更改一下表的引擎为MyISAM后,插入10w条数据的所需时间:
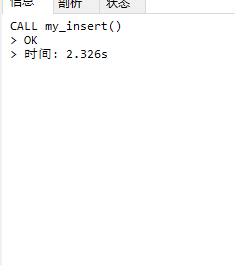
可以看到在运行速度上,提高了很多,那么在InnoDB的引擎下怎么去优化插入数据的速度呢?
在事务中进行插入处理:
#创建存储过程
DROP PROCEDURE IF EXISTS my_insert;
CREATE PROCEDURE my_insert()
BEGIN
DECLARE n int DEFAULT 1;
START TRANSACTION;
loopname:LOOP
INSERT INTO `test_xiaoyang`(`tname`) VALUES ('测试');
SET n=n+1;
IF n=100000 THEN
LEAVE loopname;
END IF;
END LOOP loopname;
COMMIT;
END;
#执行存储过程
CALL my_insert();
这里主要把循环增加插入的数据放在了START … COMMIT中;
10w条数据插入运行速度:
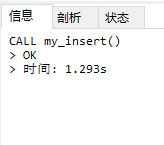
相对于没使用事务来说,优化节省了不少速度,这是因为进行一个INSERT操作时,MySQL内部会建立一个事务,在事务内进行真正插入处理。通过使用事务可以减少创建事务的消耗,所有插入都在执行后才进行提交操作。
当然了,这仅仅是插入10w条数据进行的一个演示,在面对百万级、特别是上千万级数据时,速度效率会急剧下降,在数据量较大时,有序数据索引定位较为方便,也就是:合并插入数据+事务+有序数据进行数据插入,如果有兴趣的朋友可以留言,可以专门写一篇博客进行效果演示
从其它表中拷贝数据
#复制指定数据
INSERT INTO 需要数据的表
SELECT *
FROM 拷贝数据的表
WHERE 拷贝数据的指定列字段 = 条件;
#复制全部数据
create table 需要数据的表
SELECT *
FROM 拷贝数据的表;
#方法二:
INSERT INTO 需要数据的表
SELECT *
FROM 拷贝数据的表
更新数据(update)
1、可以一次更新多条数据
2、如果需要回滚数据,需要保证在DML前,进行 设置:SET AUTOCOMMIT = FALSE;
语法:
UPDATE 表名
SET 列名1 = value , 列名2= value, ...
WHERE 指定条件修改;
删除数据(delete)
DELETE FROM 删除数据的表
WHERE 指定条件删除;
视图
含义:虚拟表,和普通表一样使用,mysql5.1版本出现的新特性,是通过表动态生成的数据
创建使用视图进行查询的优点:
- 执行效率会更快
在实际开发过程中,可能遇到多表联查,5、6张表联查都是很正常的,普通的联表查,每次都是调用执行查询语句进行查询,而使用查询视图时,会把需要查询的语句进行预编译在创建的视图里,会进行预编译,当视图一创建好, 语句就已经执行完了保存在视图里,调用视图查询,省略了一个联表查询的步骤过程,如图:

2. 编码会更加便捷
对于编码更加便捷这一点那就比较直观了,之前的5、6张表查询因为条件不同,可能每次都需要几百行代码,现在利用视图进行条件过滤筛选想要的结果集,省略了很多代码…
视图的创建
#语法:
create view 视图名
as
查询语句;
查询视图
SELECT * FROM 视图名;
#方法二:
DESC 视图名;
修改视图名
create or replace view 视图名
as
查询语句;
#方式二
alter view 视图名
as
查询语句;
删除视图
DROP VIEW 视图名;
尾言
好了,MySQL的DML语言以及视图就简单的介绍到这里了,博文里的存储过程以及优化插入和查询速度效率问题欢迎大家评论区探讨…